Train ML models in Vantage using Database Analytic Functions
Overview
There are situations when you want to quickly validate a machine learning model idea. You have a model type in mind. You don't want to operationalize with an ML pipeline just yet. You just want to test out if the relationship you had in mind exists. Also, sometimes even your production deployment doesn't require constant relearning with MLops. In such cases, you can use Database Analytic Functions for feature engineering, train different ML models, score your models, and evaluate your model on different model evaluation functions.
Prerequisites
You need access to a Teradata Vantage instance.
If you need a test instance of Vantage, you can provision one for free at https://clearscape.teradata.com
Load the sample data
Here in this example we will be using the sample data from val database. We will use the accounts, customer, and transactions tables. We will be creating some tables in the process and you might face some issues while creating tables in val database, so let's create our own database td_analytics_functions_demo.
You must have CREATE TABLE permissions on the Database where you want to use Database Analytics Functions.
Let's now create accounts, customer and transactions tables in our database td_analytics_functions_demo from the corresponding tables in val database.
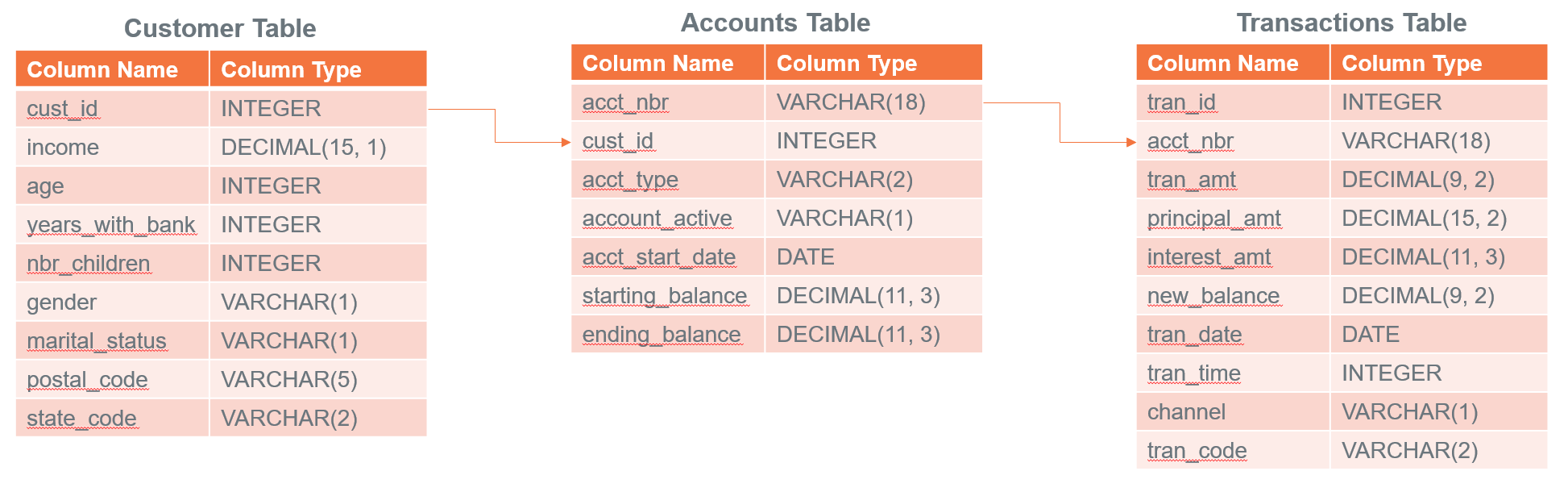
Understand the sample data
Now, that we have our sample tables loaded into td_analytics_functions_demo, let's explore the data. It's a simplistic, fictitious dataset of banking customers (700-ish rows), Accounts (1400-ish rows) and Transactions (77K-ish rows). They are related to each other in the following ways:
In later parts of this how-to we are going to explore if we can build a model that predicts average monthly balance that a banking customer has on their credit card based on all non-credit card related variables in the tables.
Preparing the Dataset
We have data in three different tables that we want to join and create features. Let's start by creating a joined table.
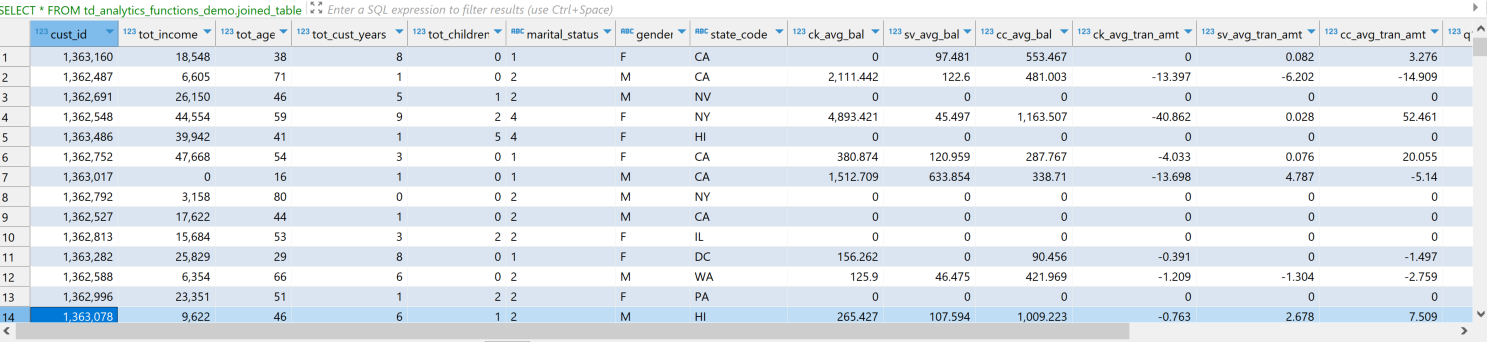
Let's now see how our data looks. The dataset has both categorical and continuous features or independent variables. In our case, the dependent variable is cc_avg_bal which is customer's average credit card balance.
Feature Engineering
On looking at the data we see that there are several features that we can take into consideration for predicting the cc_avg_bal.
TD_OneHotEncodingFit
As we have some categorical features in our dataset such as gender, marital status and state code. We will leverage the Database Analytics function TD_OneHotEncodingFit to encode categories to one-hot numeric vectors.
TD_ScaleFit
If we look at the data, some columns like tot_income, tot_age, ck_avg_bal have values in different ranges. For the optimization algorithms like gradient descent it is important to normalize the values to the same scale for faster convergence, scale consistency and enhanced model performance. We will leverage TD_ScaleFit function to normalize values in different scales.
TD_ColumnTransformer
Teradata's Database Analytic Functions typically operate in pairs for data transformations. The first step is dedicated to "fitting" the data. Subsequently, the second function utilizes the parameters derived from the fitting process to execute the actual transformation on the data. The TD_ColumnTransformertakes the FIT tables to the function and transforms the input table columns in single operation.
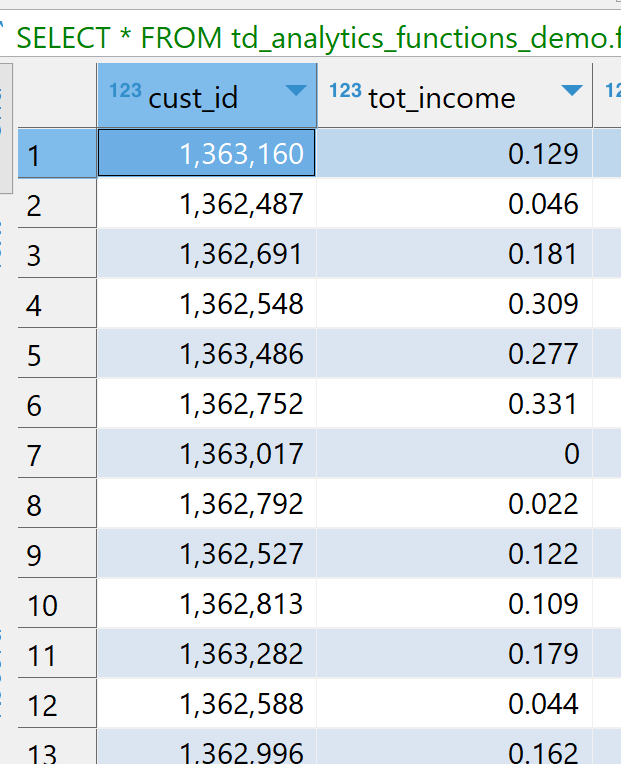
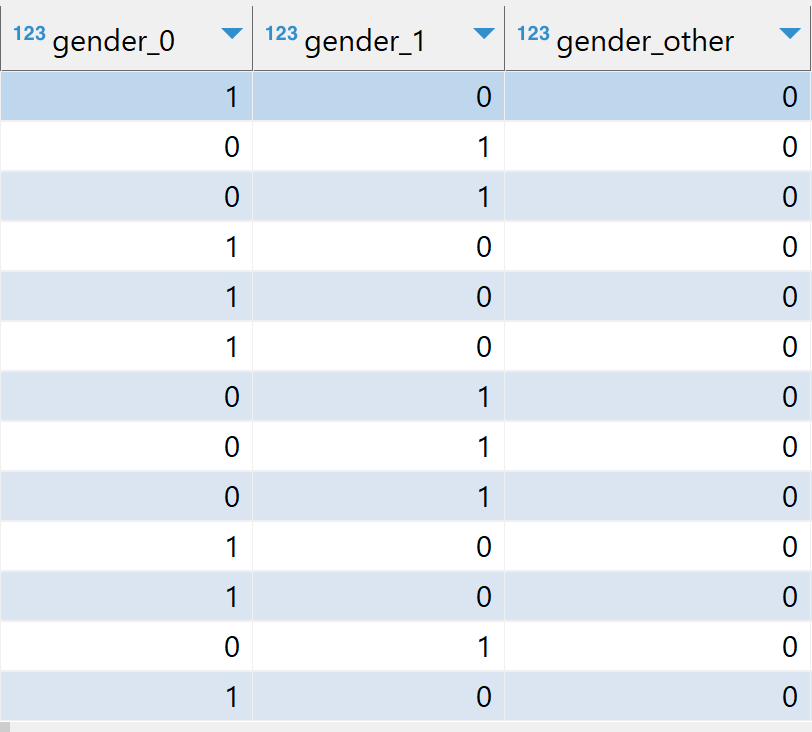
Once we perform the transformation we can see our categorical columns one-hot encoded and numeric values scaled as can be seen in the image below. For ex: tot_income is in the range [0,1], gender is one-hot encoded to gender_0, gender_1, gender_other.
Train Test Split
As we have our datatset ready with features scaled and encoded, now let's split our dataset into training (75%) and testing (25%) parts. Teradata's Database Analytic Functions provide TD_TrainTestSplit function that we'll leverage to split our dataset.
As can be seen in the image below, the function adds a new column TD_IsTrainRow.
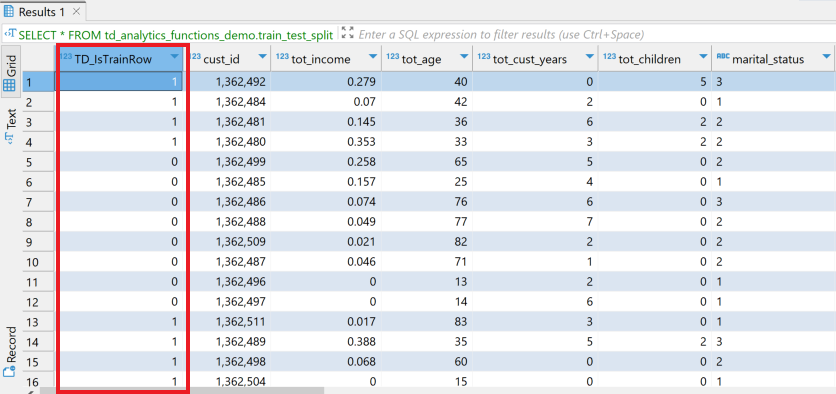
We'll use TD_IsTrainRow to create two tables, one for training and other for testing.
Training with Generalized Linear Model
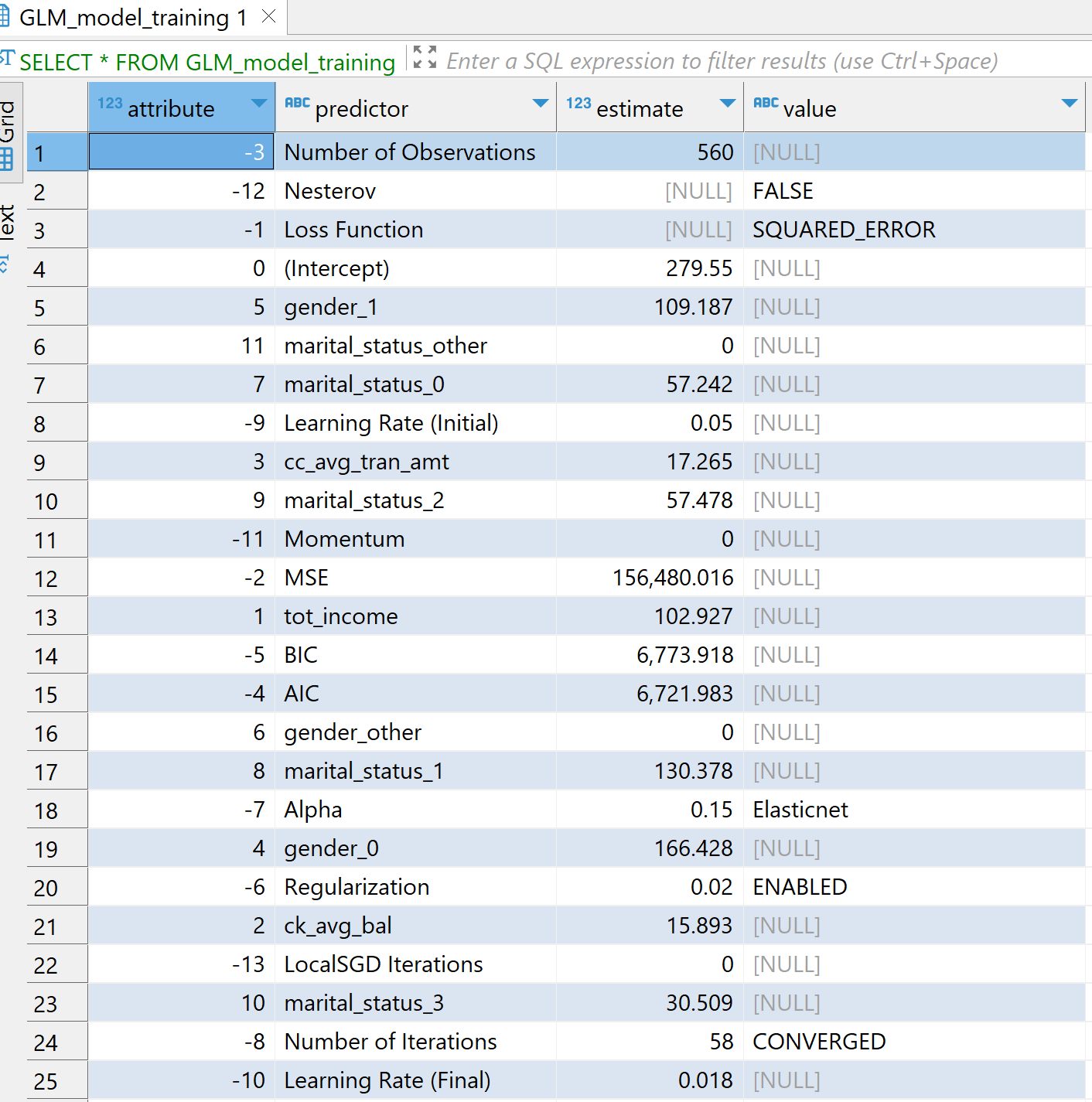
We will now use TD_GLM Database Analytic Function to train on our training dataset. The TD_GLM function is a generalized linear model (GLM) that performs regression and classification analysis on data sets. Here we have used a bunch of input columns such as tot_income, ck_avg_bal,cc_avg_tran_amt, one-hot encoded values for marital status, gender and states. cc_avg_bal is our dependent or response column which is continous and hence is a regression problem. We use Family as Gaussian for regression and Binomial for classification.
The parameter Tolerance signifies minimum improvement required in prediction accuracy for model to stop the iterations and MaxIterNum signifies the maximum number of iterations allowed. The model concludes training upon whichever condition is met first. For example in the example below the model is CONVERGED after 58 iterations.
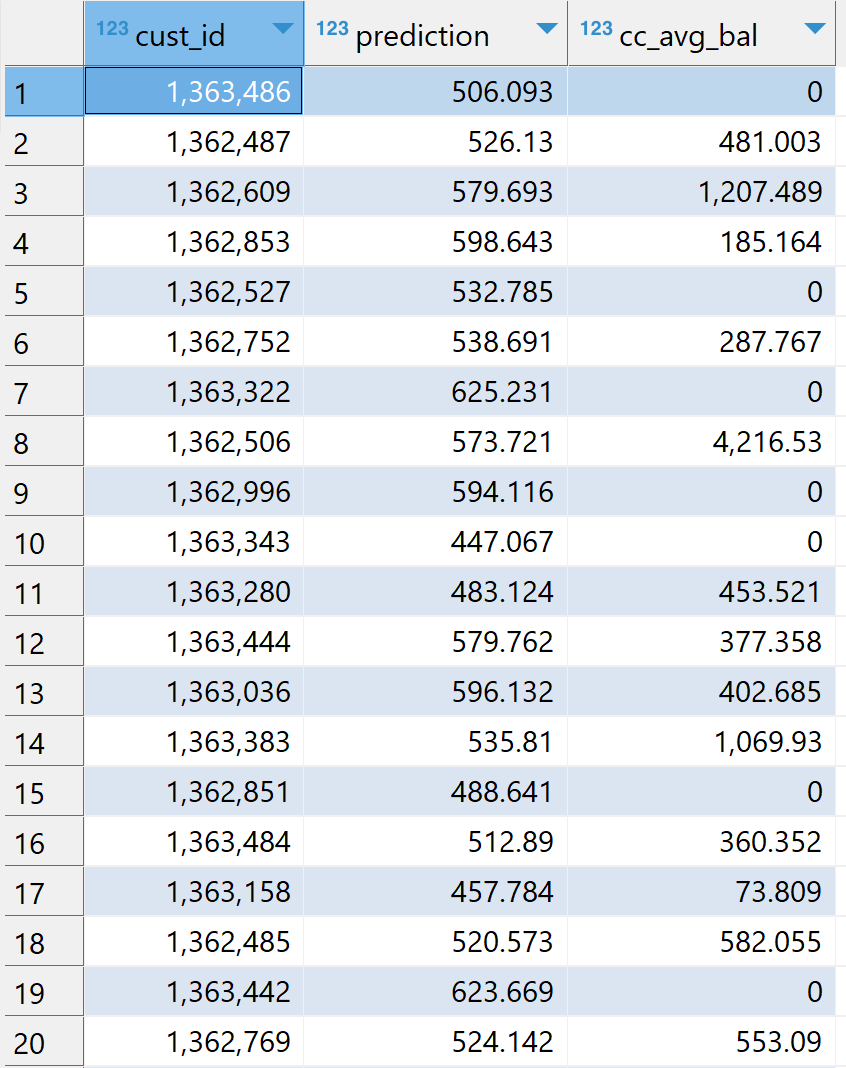
Scoring on Testing Dataset
We will now use our model GLM_model_training to score our testing dataset testing_table using link:TD_GLMPredictDatabase Analytic Function.
Model Evaluation
Finally, we evaluate our model on the scored results. Here we are using TD_RegressionEvaluator function. The model can be evaluated based on parameters such as R2, RMSE, F_score.

The purpose of this how-to is not to describe feature engineering but to demonstrate how we can leverage different Database Analytic Functions in Vantage. The model results might not be optimal and the process to make the best model is beyond the scope of this article.
Summary
In this quick start we have learned how to create ML models using Teradata Database Analytic Functions. We built our own database td_analytics_functions_demo with customer,accounts, transactions data from val database. We performed feature engineering by transforming the columns using TD_OneHotEncodingFit, TD_ScaleFit and TD_ColumnTransformer. We then used TD_TrainTestSplit for train test split. We trained our training dataset with TD_GLM model and scored our testing dataset. Finally we evaluated our scored results using TD_RegressionEvaluator function.
Further reading
If you have any questions or need further assistance, please visit our community forum where you can get support and interact with other community members.