Use AWS SageMaker with Teradata Vantage
Overview
This how-to will help you to integrate Amazon SageMaker with Teradata Vantage. The approach this guide explains is one of many potential approaches to integrate with the service.
Amazon SageMaker provides a fully managed Machine Learning Platform. There are two use cases for Amazon SageMaker and Teradata:
-
Data resides on Teradata Vantage and Amazon SageMaker will be used for both the Model definition and subsequent scoring. Under this use case Teradata will provide data into the Amazon S3 environment so that Amazon SageMaker can consume training and test data sets for the purpose of model development. Teradata would further make data available via Amazon S3 for subsequent scoring by Amazon SageMaker. Under this model Teradata is a data repository only.
-
Data resides on Teradata Vantage and Amazon SageMaker will be used for the Model definition, and Teradata for the subsequent scoring. Under this use case Teradata will provide data into the Amazon S3 environment so that Amazon SageMaker can consume training and test data sets for the purpose of model development. Teradata will need to import the Amazon SageMaker model into a Teradata table for subsequent scoring by Teradata Vantage. Under this model Teradata is a data repository and a scoring engine.
The first use case is discussed in this document.
Amazon SageMaker consumes training and test data from an Amazon S3 bucket. This article describes how you can load Teradata analytics data sets into an Amazon S3 bucket. The data can then available to Amazon SageMaker to build and train machine learning models and deploy them into a production environment.
Prerequisites
- Access to a Teradata Vantage instance.
Hinweis
If you need a test instance of Vantage, you can provision one for free at https://clearscape.teradata.com
- IAM permission to access Amazon S3 bucket, and to use Amazon SageMaker service.
- An Amazon S3 bucket to store training data.
Load data
Amazon SageMaker trains data from an Amazon S3 bucket. Following are the steps to load training data from Vantage to an Amazon S3 bucket:
-
Go to Amazon SageMaker console and create a notebook instance. See Amazon SageMaker Developer Guide for instructions on how to create a notebook instance:
-
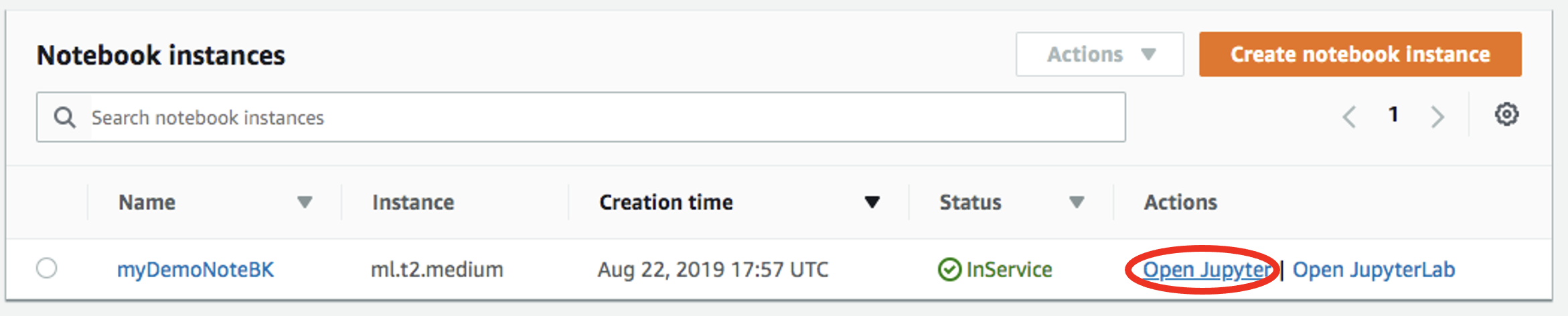
Open your notebook instance:
-
Start a new file by clicking on
New -> conda_python3: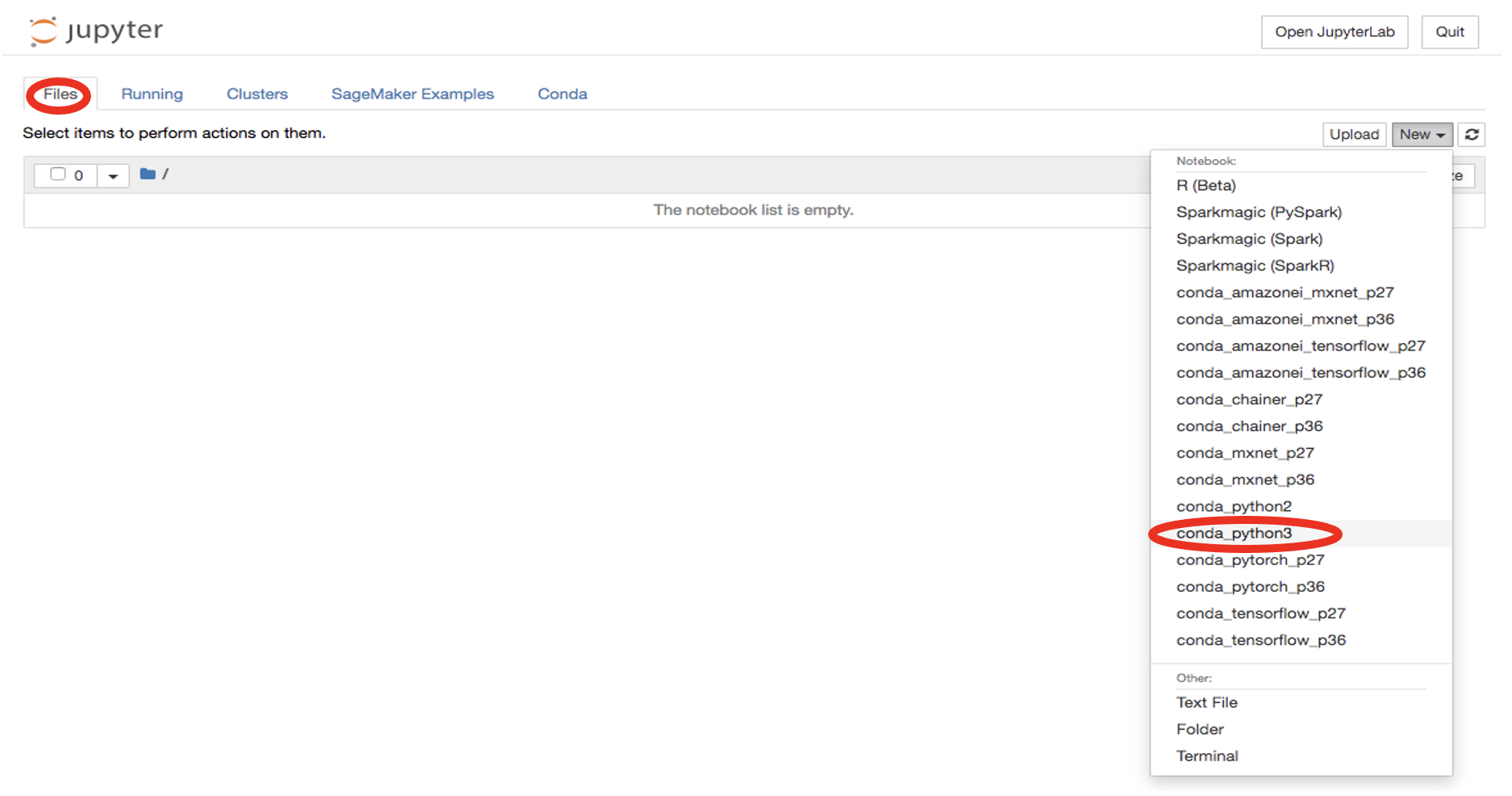
-
Install Teradata Python library:
-
In a new cell and import additional libraries:
-
In a new cell, connect to Teradata Vantage. Replace
<hostname>,<database user name>,<database password>to match your Vantage environment: -
Retrieve data rom the table where the training dataset resides using TeradataML DataFrame API:
-
Write data to a local file:
-
Upload the file to Amazon S3:
Train the model
-
Select
Training jobson the left menu underTraining, then click onCreate training job: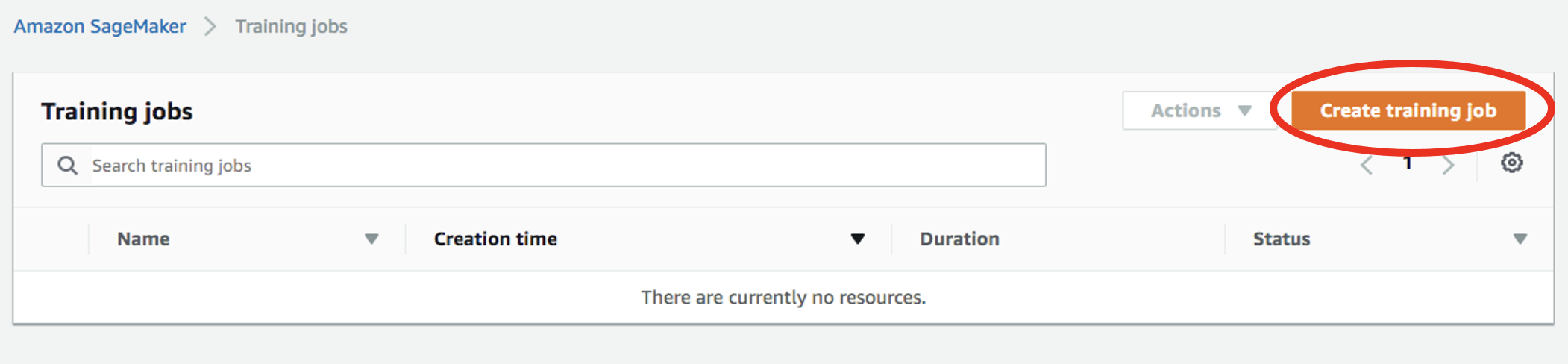
-
At the
Create training jobwindow, fill in theJob name(e.g.xgboost-bank) andCreate a new rolefor the IAM role. ChooseAny S3 bucketfor the Amazon S3 buckets andCreate role: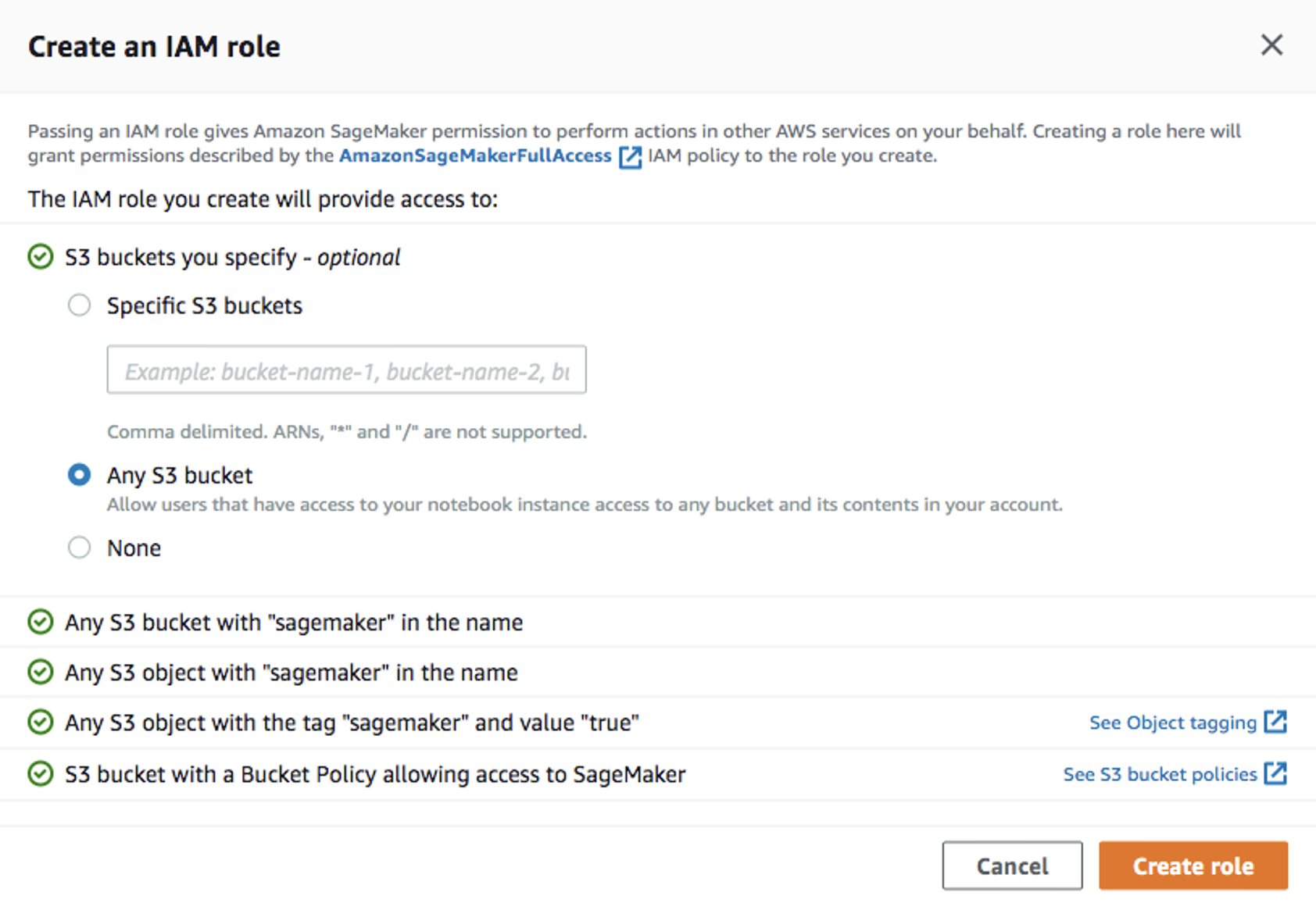
-
Back in the
Create training jobwindow, useXGBoostas the algorithm: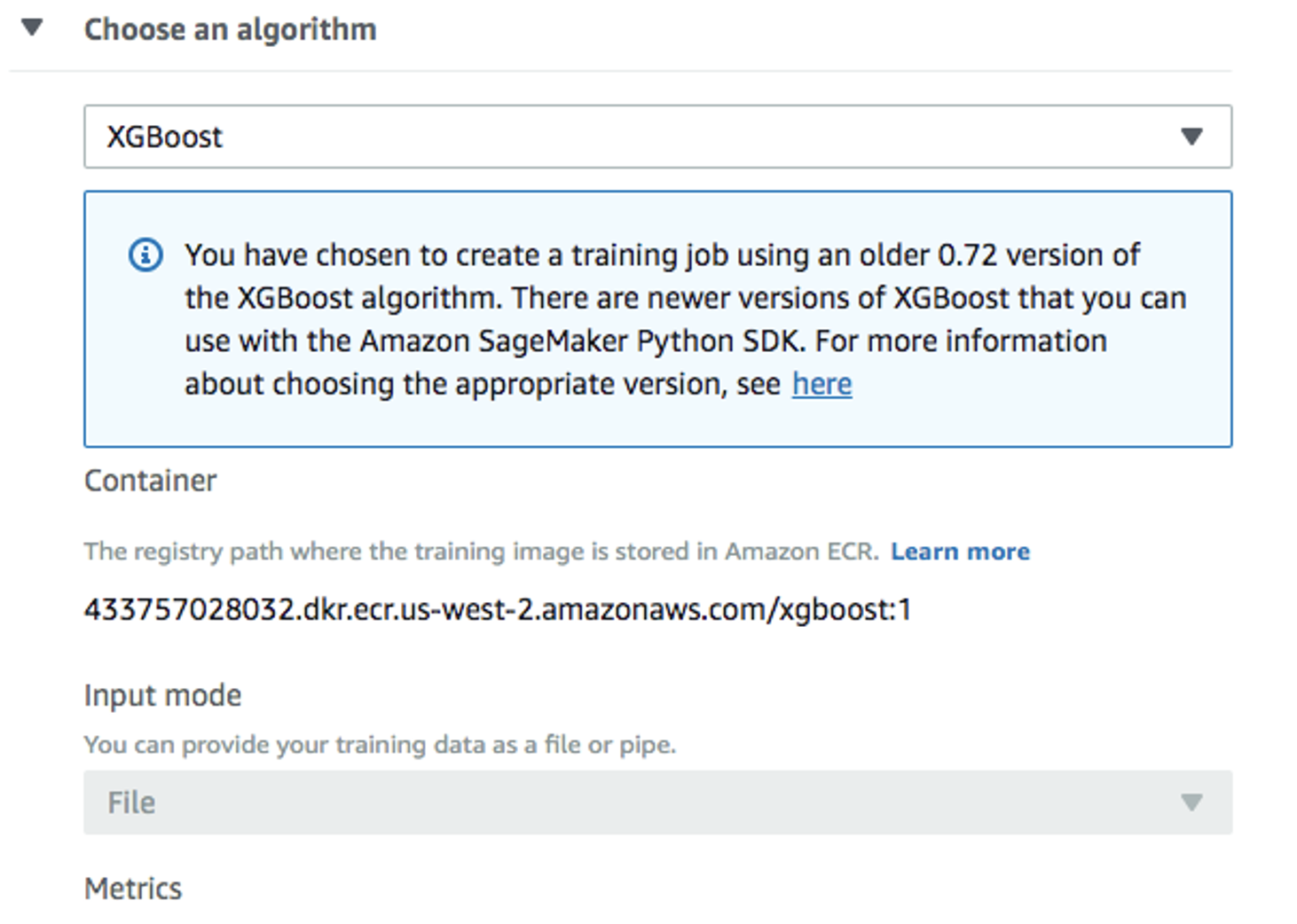
-
Use the default
ml.m4.xlargeinstance type, and 30GB of additional storage volume per instance. This is a short training job, shouldn't take more than 10 minutes. 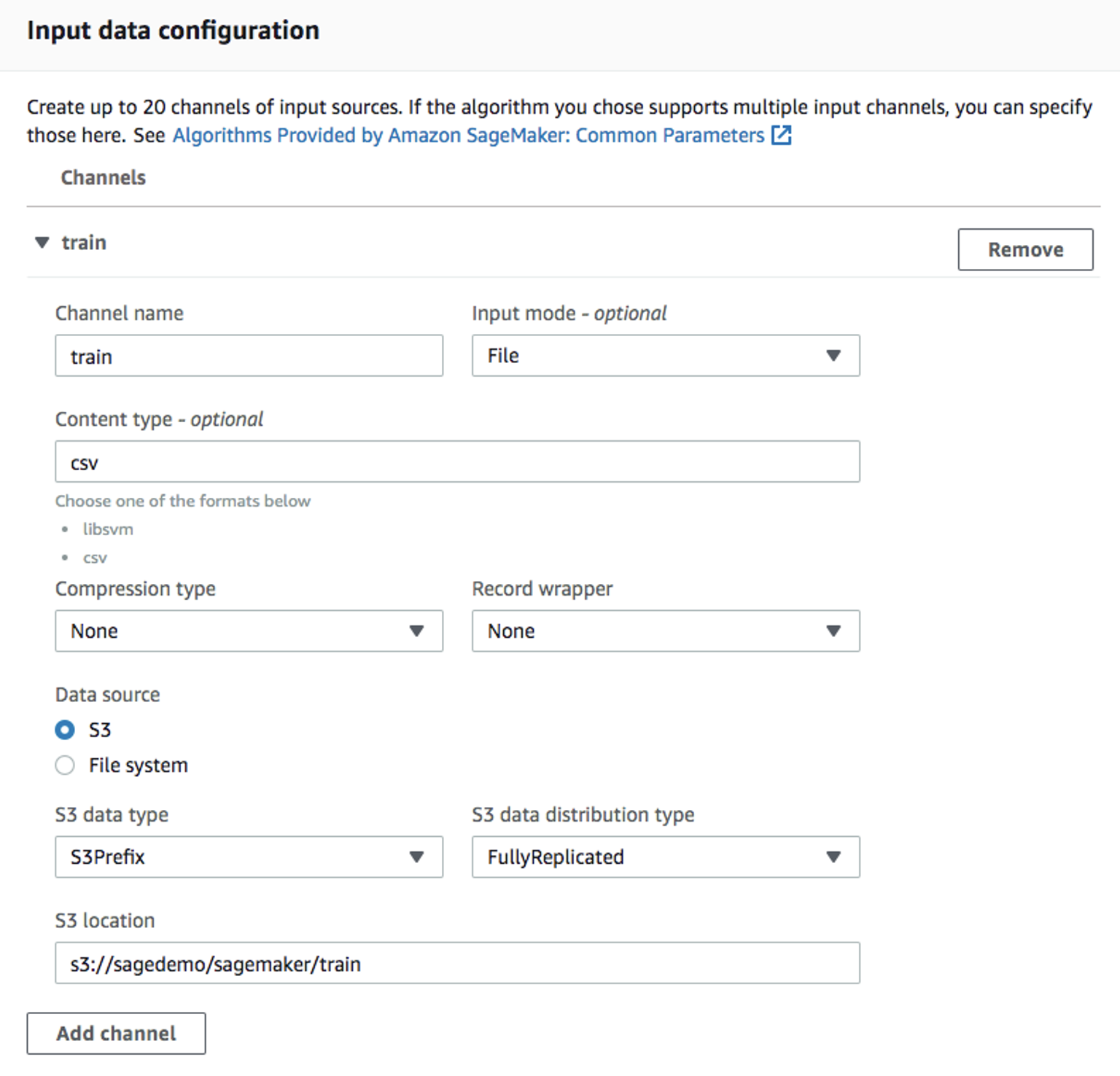
-
For
Output data configuration, enter path where the output data will be stored: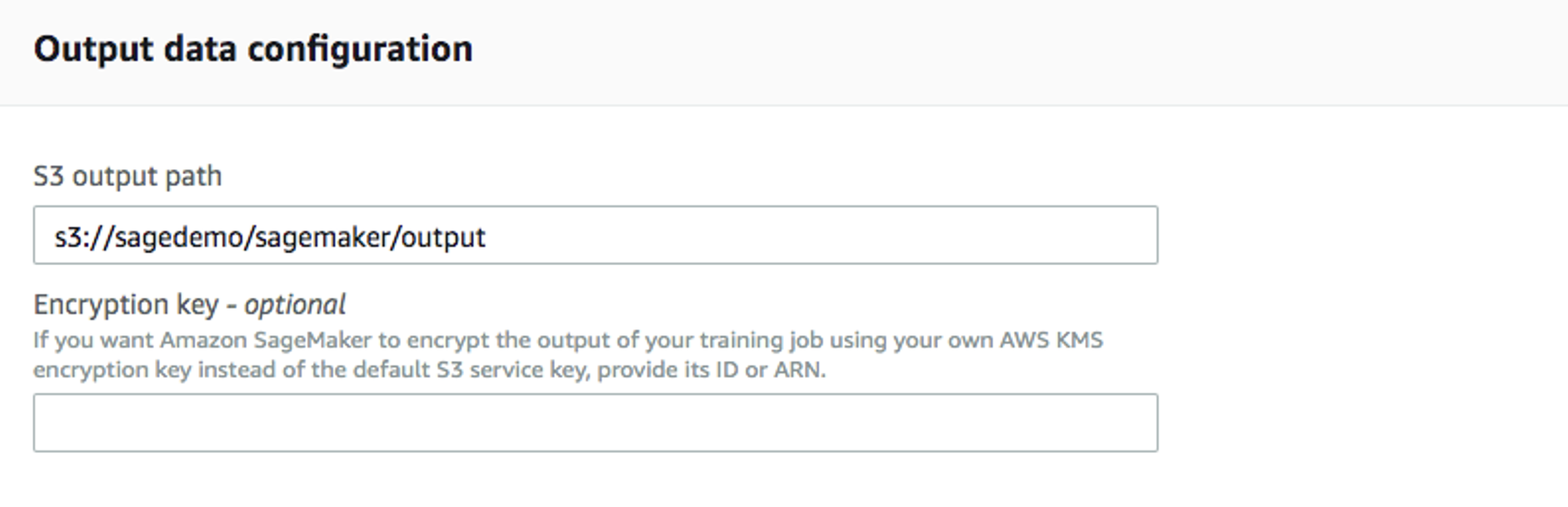
-
Leave everything else as default, and click on “Create training job”. Detail instructions on how to configure the training job can be found in [Amazon SageMaker Developer Guide](https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-mkt-algo-train.html#sagemaker-mkt-algo-train-console].
Once the training job's created, Amazon SageMaker launches the ML instances to train the model, and stores the resulting model artifacts and other output in the Output data configuration (path/<training job name>/output by default).
Deploy the model
After you train your model, deploy it using a persistent endpoint
Create a model
- Select
ModelsunderInferencefrom the left panel, thenCreate model. Fill in the model name (e.g.xgboost-bank), and choose the IAM role you created from the previous step. - For
Container definition 1, use433757028032.dkr.ecr.us-west-2.amazonaws.com/xgboost:latestasLocation of inference code image.Location of model artifactsis the output path of your training job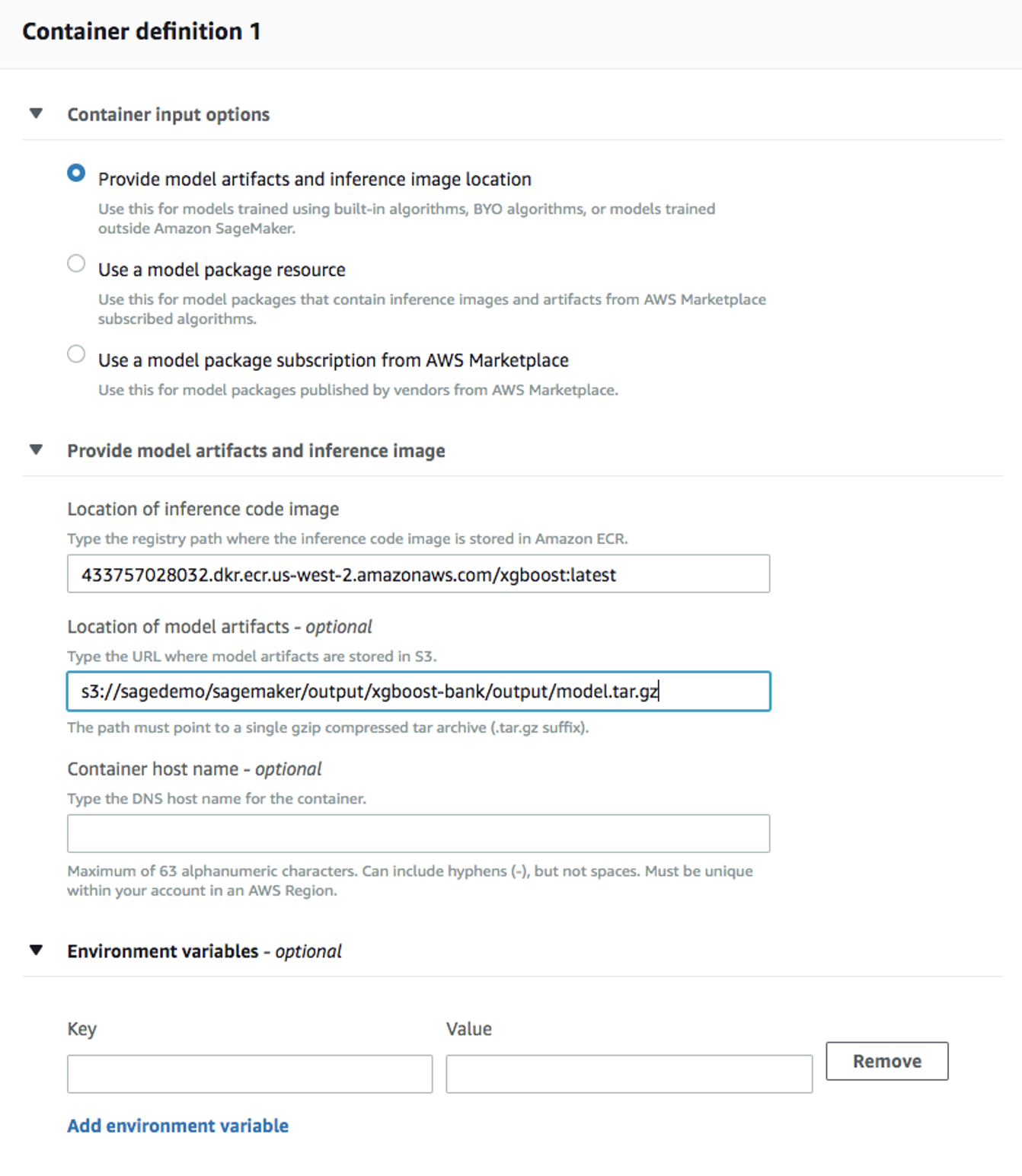
- Leave everything else as default, then
Create model.
Create an endpoint configuration
-
Select the model you just created, then click on
Create endpoint configuration: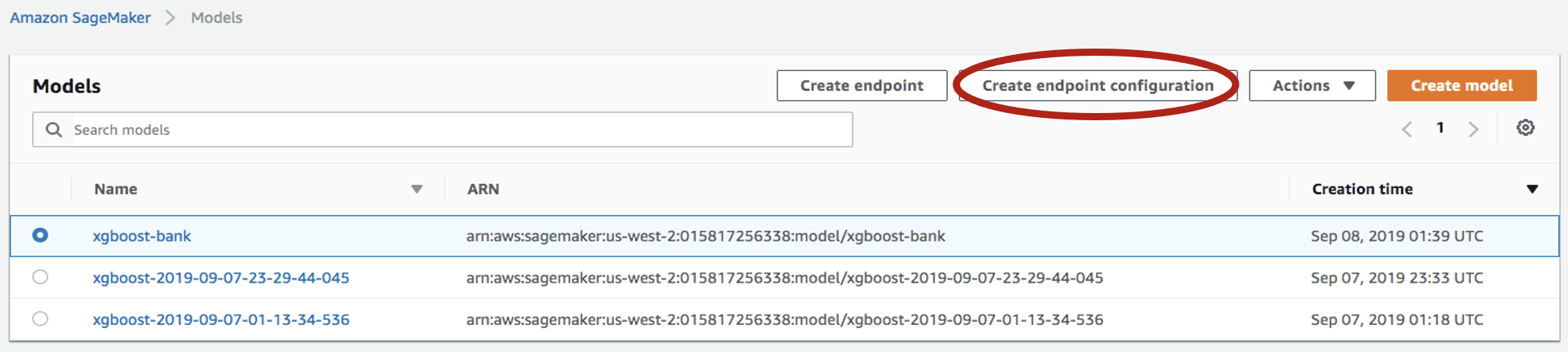
-
Fill in the name (e.g.
xgboost-bank) and use default for everything else. The model name and training job should be automatically populated for you. Click onCreate endpoint configuration.
Create endpoint
-
Select
Inference->Modelsfrom the left panel, select the model again, and click onCreate endpointthis time: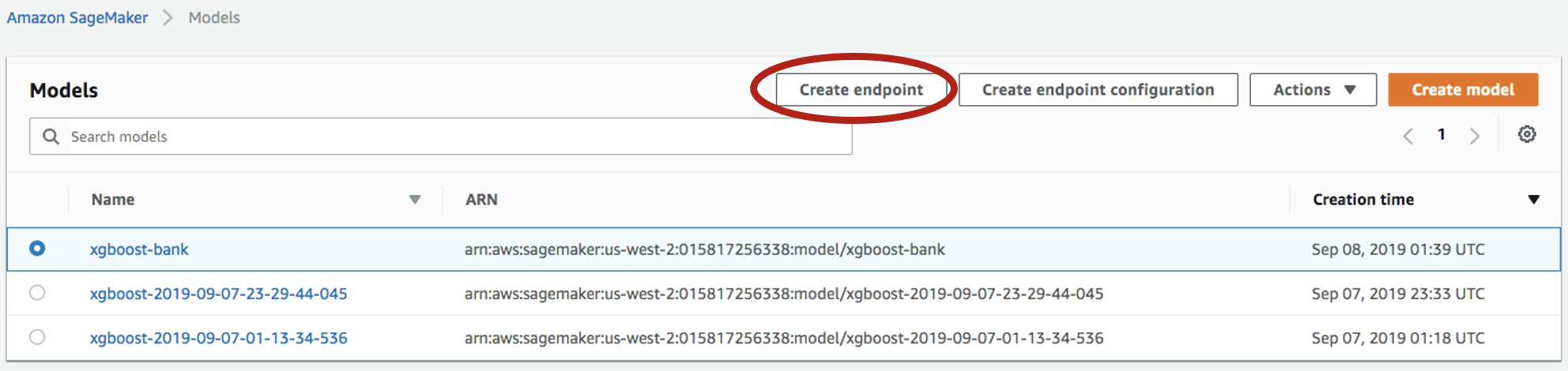
-
Fill in the name (e.g.
xgboost-bank), and selectUse an existing endpoint configuration: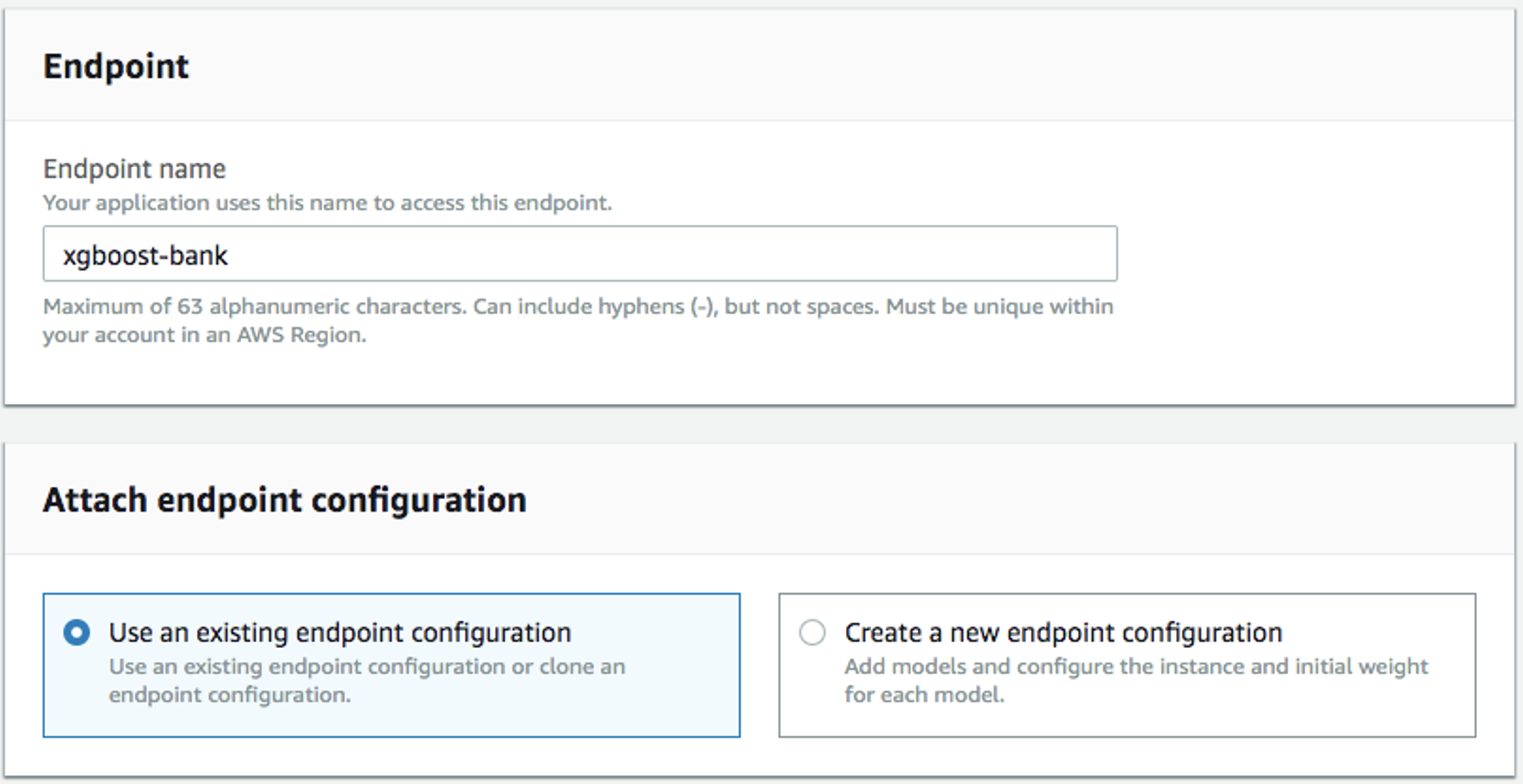
-
Select the endpoint configuration created from last step, and click on
Select endpoint configuration:
-
Leave everything else as default and click on
Create endpoint.
Now the model is deployed to the endpoint and can be used by client applications.
Summary
This how-to demonstrated how to extract training data from Vantage and use it to train a model in Amazon SageMaker. The solution used a Jupyter notebook to extract data from Vantage and write it to an S3 bucket. A SageMaker training job read data from the S3 bucket and produced a model. The model was deployed to AWS as a service endpoint.
Further reading
- API integration guide for AWS SageMaker
- Integrate Teradata Jupyter extensions with SageMaker notebook instance
If you have any questions or need further assistance, please visit our community forum where you can get support and interact with other community members.