Integrate Teradata Vantage with Google Cloud Data Catalog
Overview
This article describes the process to connect Teradata Vantage with Google Cloud Data Catalog using the Data Catalog Teradata Connector on GitHub, and then explore the metadata of the Vantage tables via Data Catalog.
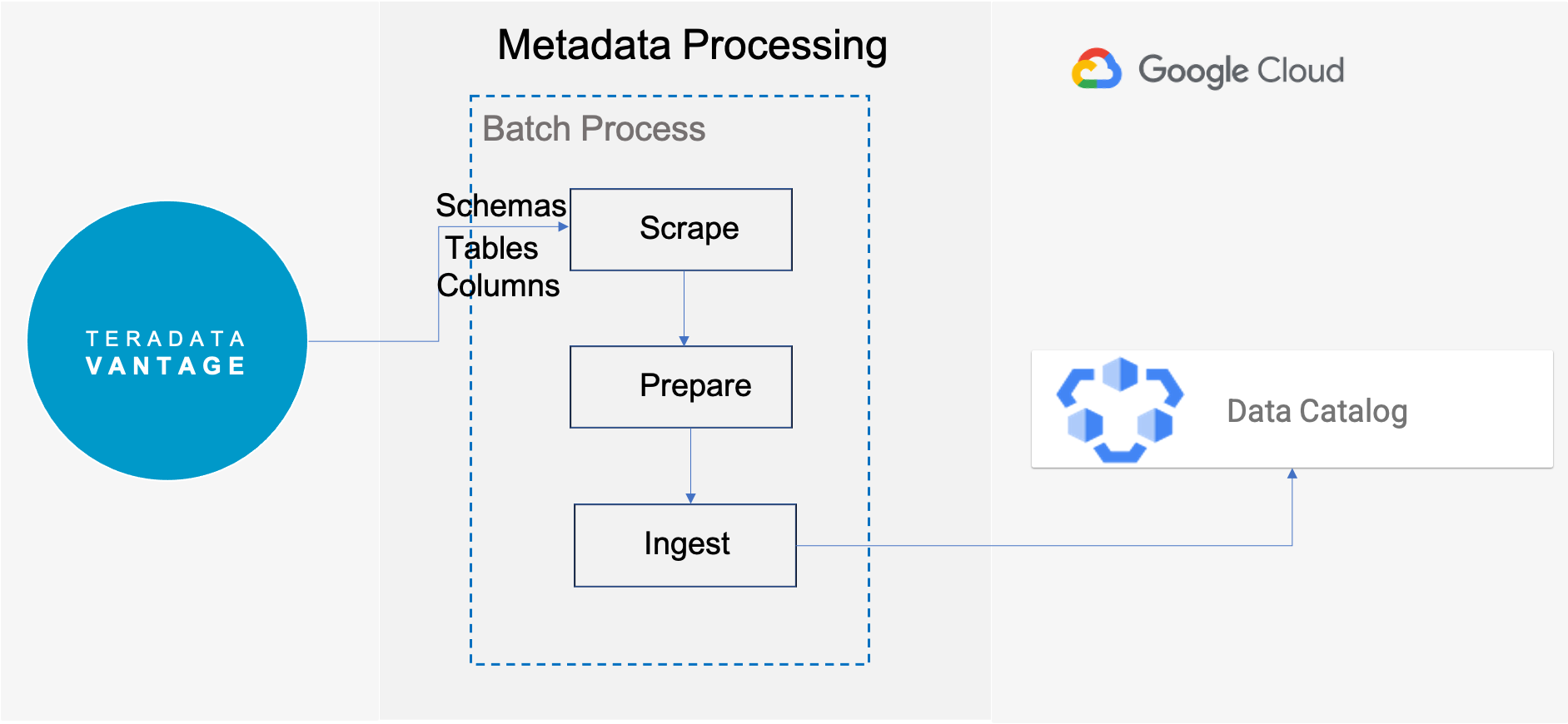
- Scrape: Connect to Teradata Vantage and retrieve all the available metadata
- Prepare: Transform metadata in Data Catalog entities and create Tags
- Ingest: Send the Data Catalog entities to the Google Cloud project
About Google Cloud Data Catalog�
Google Cloud Data Catalog is a fully managed data discovery and metadata management service. Data Catalog can catalog the native metadata on data assets. Data Catalog is serverless, and provides a central catalog to capture both technical metadata as well as business metadata in a structured format.
About Teradata Vantage
Vantage is the modern cloud platform that unifies data warehouses, data lakes, and analytics into a single connected ecosystem.
Vantage combines descriptive, predictive, prescriptive analytics, autonomous decision-making, ML functions, and visualization tools into a unified, integrated platform that uncovers real-time business intelligence at scale, no matter where the data resides.
Vantage enables companies to start small and elastically scale compute or storage, paying only for what they use, harnessing low-cost object stores and integrating their analytic workloads.
Vantage supports R, Python, Teradata Studio, and any other SQL-based tools. You can deploy Vantage across public clouds, on-premises, on optimized or commodity infrastructure, or as-a-service.
See the documentation for more information on Teradata Vantage.
Prerequisites
-
Access to a Teradata Vantage instance.
-
A Google Service Account with Data Catalog Admin role
-
A Cloud Console Project created for your account (i.e. partner-integration-lab)
-
Billing enabled
-
Google Cloud SDK installed and initialized
-
Python installed
-
Pip installed
Procedure
- Enable Data Catalog APIs
- Install Teradata Data Catalog Connector
- Run
- Explore Teradata Vantage metadata with Data Catalog
Enable Data Catalog API
-
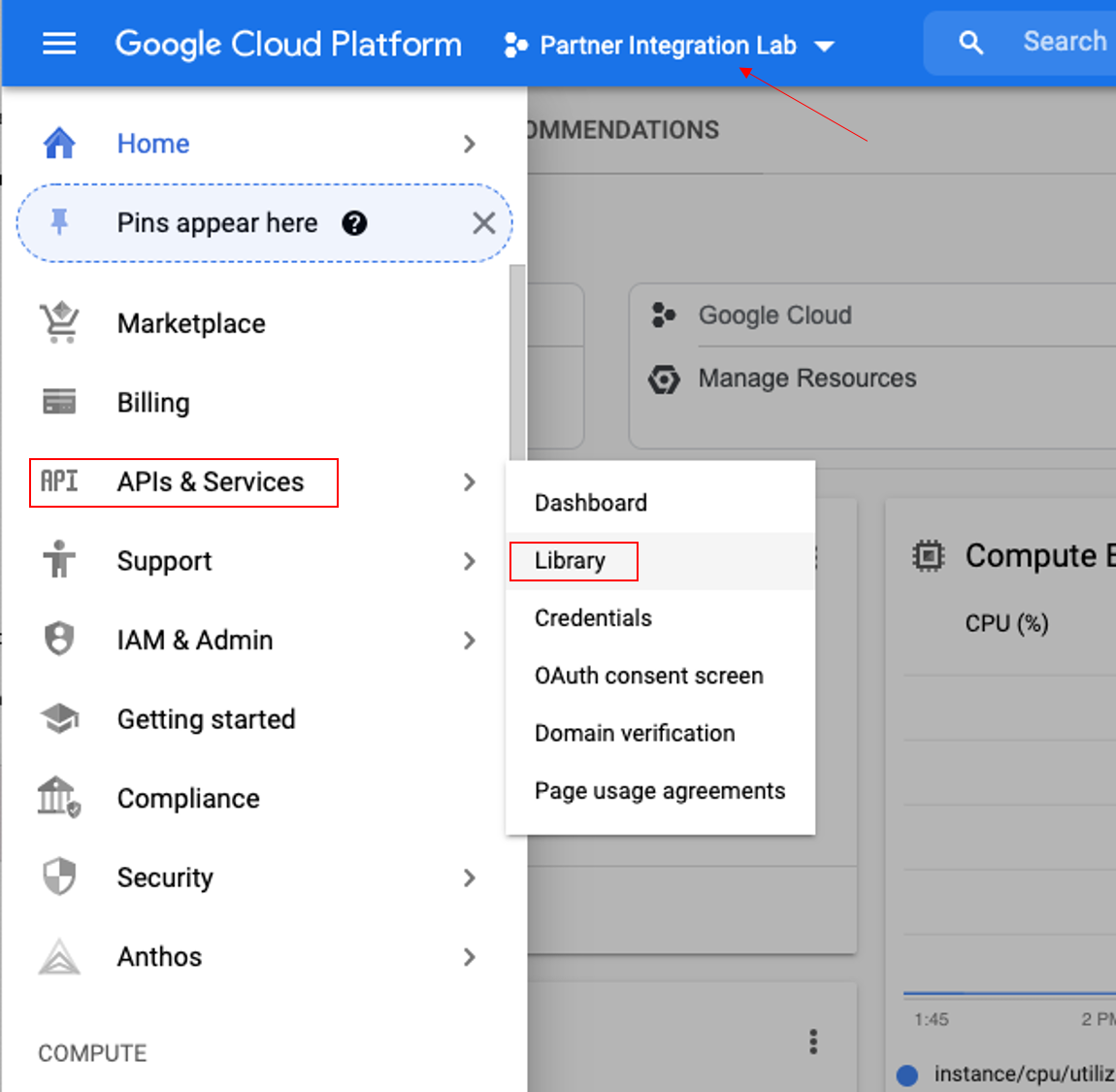
Logon to Google console, choose APIs & Services from the Navigation menu, then click on Library. Make sure your project is selected on the top menu bar.
-
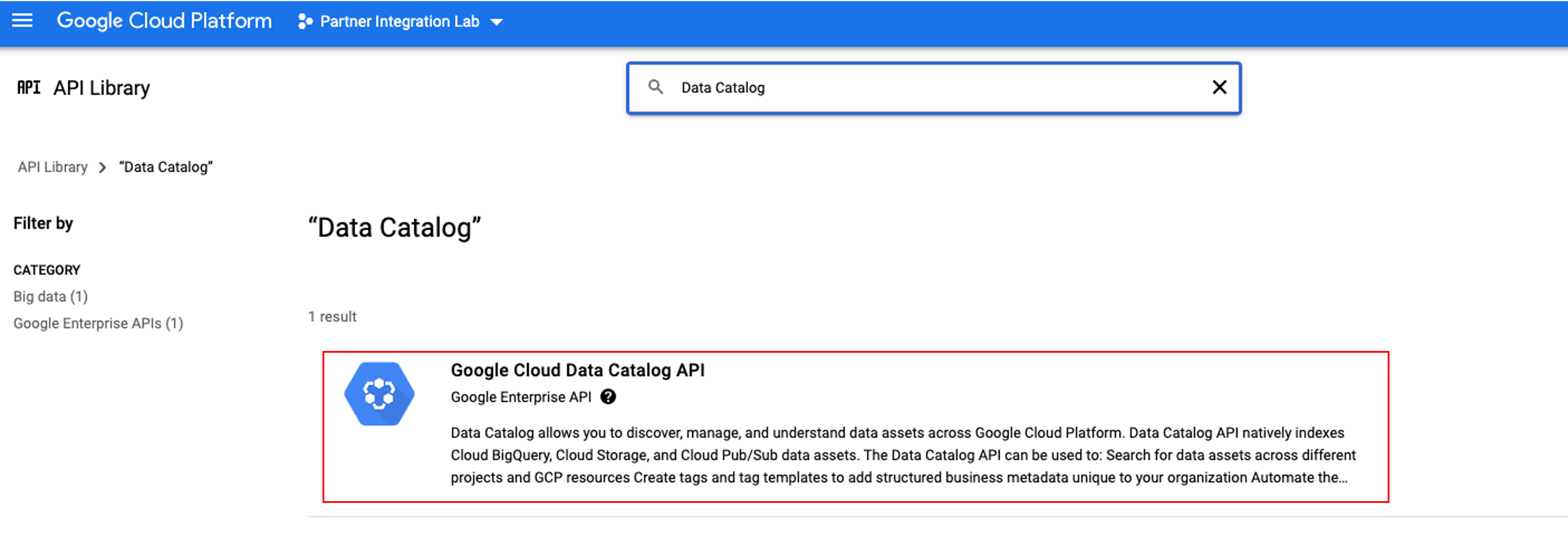
Put Data Catalog in the search box and click on Google Cloud Data Catalog API, click ENABLE
Install Teradata Data Catalog Connector
A Teradata Data Catalog connector is available on GitHub. This connector is written in Python.
-
Run following command to authorize gcloud to access the Cloud Platform with Google user credentials.
-
Choose your Google account when the Google login page opens up and click Allow on the next page.
-
Next, set up default project if you haven’t already done so
Install virtualenv
We recommend you install the Teradata Data Catalog Connector in an isolated Python environment. To do so, install virtualenv first:
-
Windows
Run in Powershell as Administrator:
-
MacOS
-
Linux
Install Data Catalog Teradata Connector
-
Windows
-
MacOS
-
Linux
Set environment variables
Where <google_credential_file> is the key for your service account (json file).
Run
Execute google-datacatalog-teradata-connector command to establish entry point to Vantage database.
Sample output from the google-datacatalog-teradata-connector command:
Explore Teradata Vantage metadata with Data Catalog
-
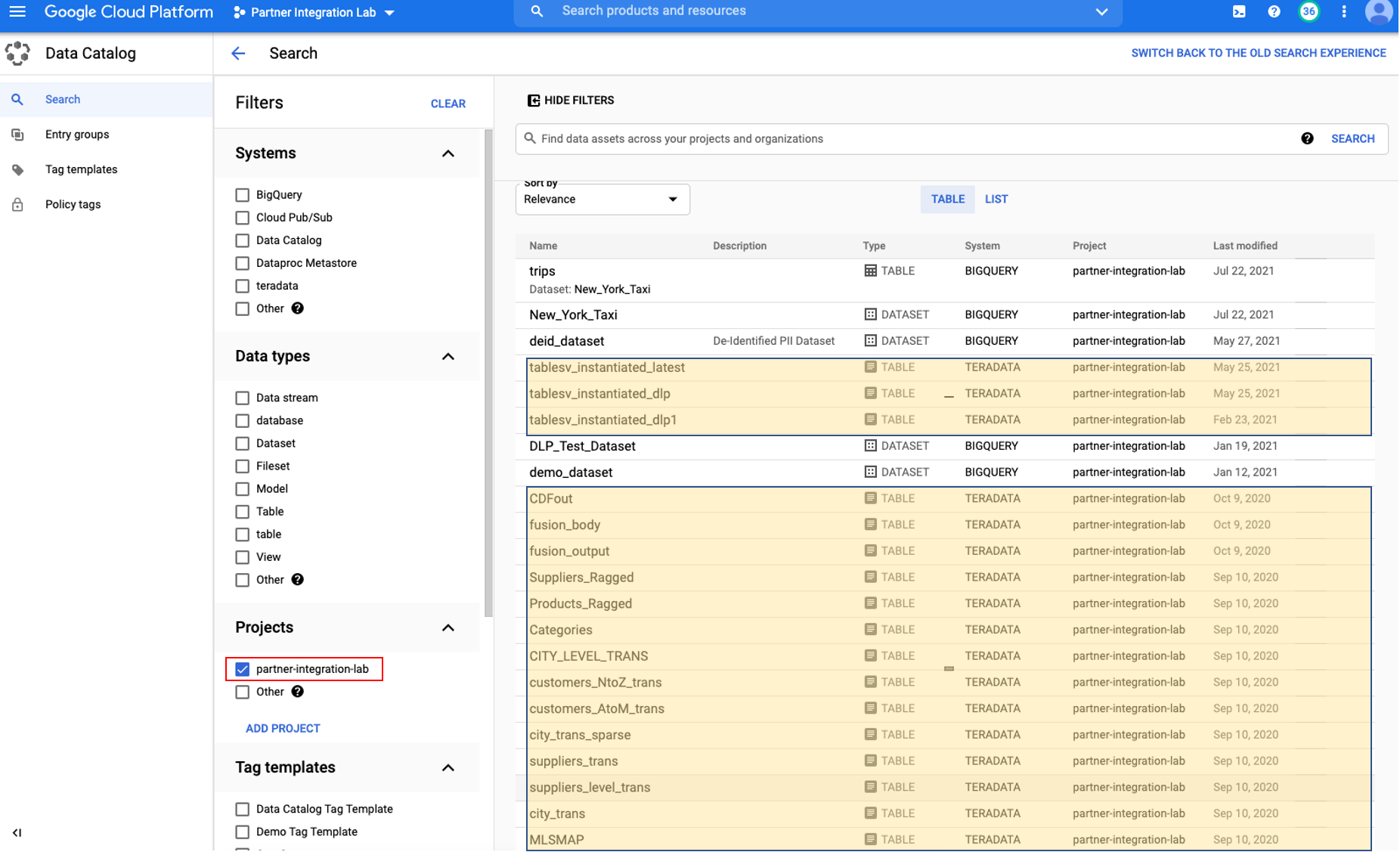
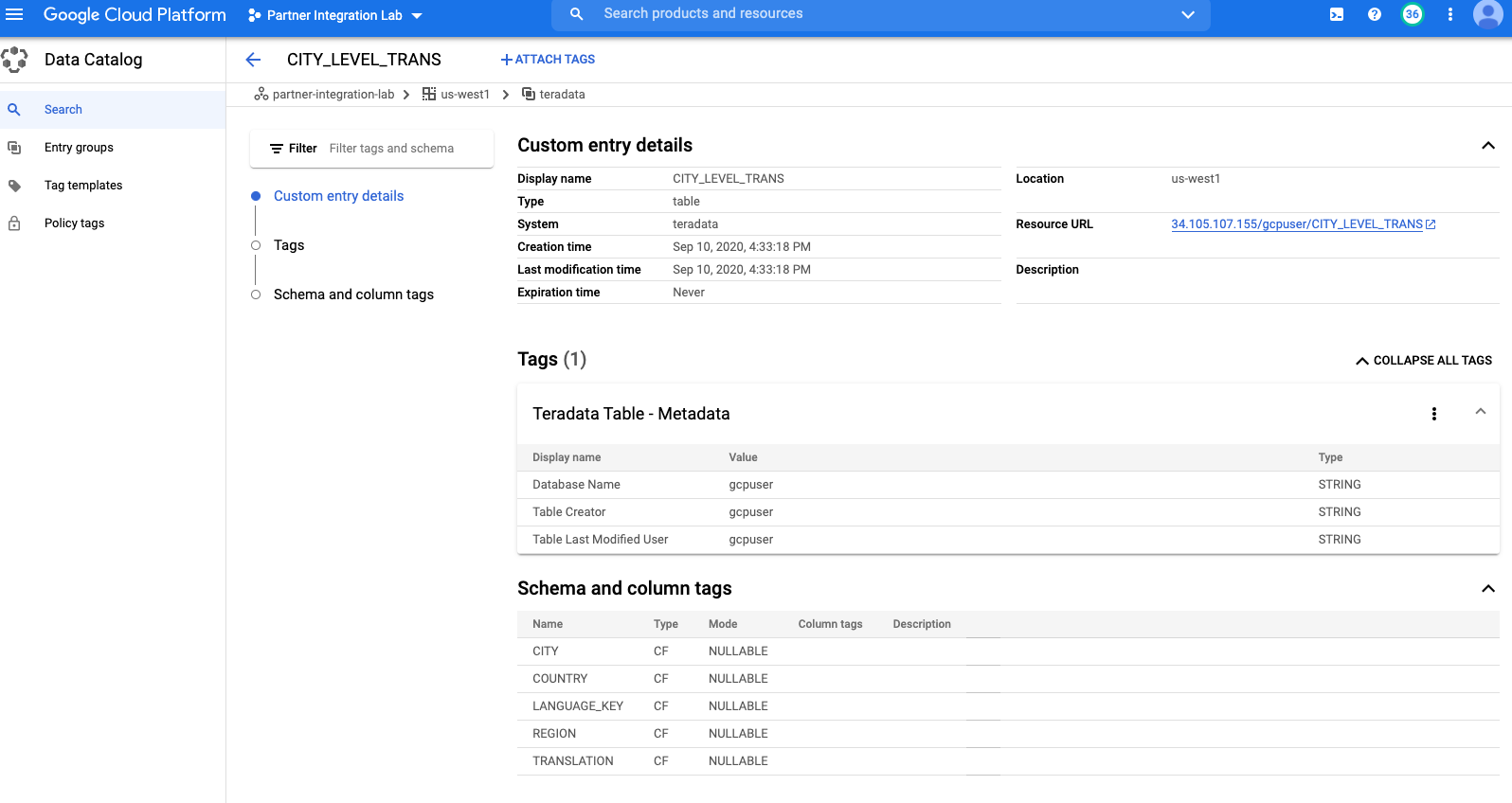
Go to Data Catalog console, click on the project (i.e. partner-integration-lab) under Projects. The Teradata tables are showing on the right panel.
-
Click on the table to your interest (i.e. CITY_LEVEL_TRANS), and you’ll see the metadata about this table:
Cleanup (optional)
-
Clean up metadata from Data Catalog. To do that, copy https://github.com/GoogleCloudPlatform/datacatalog-connectors-rdbms/blob/master/google-datacatalog-teradata-connector/tools/cleanup_datacatalog.py to local directory.
-
Change directory to where the file is and then run following command: