ModelOps: importar e implemente su primer modelo GIT
Información general
Este es un tutorial para personas no familiarizadas con ClearScape Analytics ModelOps. En el tutorial, podrá crear un nuevo proyecto en ModelOps, cargar los datos necesarios en Vantage y realizar un seguimiento del ciclo de vida completo de un modelo de demostración utilizando plantillas de código y siguiendo la metodología para modelos GIT en ModelOps.
Prerrequisitos
-
Acceso a una instancia de Teradata Vantage con ClearScape Analytics (incluye ModelOps)
-
Capacidad para ejecutar Jupyter Notebooks
Si necesita una instancia de prueba de Vantage, puede obtener una de forma gratuita en https://clearscape.teradata.com
Archivos necesarios
Comencemos descargando los archivos necesarios para este tutorial. Descargue estos 4 archivos adjuntos y cárguelos en el sistema de archivos de su Notebook. Seleccione los archivos según su versión de ModelOps:
ModelOps versión 6 (octubre de 2022):
Descargar el cuaderno de formación de ModelOps
Descargar el archivo de cuaderno BYOM para un caso de uso de demostración
Descargar archivos de datos para un caso de uso de demostración
Descargar archivos de código BYOM para un caso de uso de demostración
Alternativamente, puede clonar con git los siguientes repositorios
ModelOps versión 7 (abril de 2023):
Descargar el cuaderno de formación de ModelOps
Descargar el archivo de cuaderno BYOM para un caso de uso de demostración
Descargar archivos de datos para un caso de uso de demostración
Descargar archivos de código BYOM para un caso de uso de demostración
Configurar la base de datos y el entorno Jupyter
Siga el Jupyter Notebook ModelOps_Training para configurar la base de datos, las tablas y las bibliotecas necesarias para la demostración.
Entender dónde estamos en la metodología

Crear un nuevo proyecto o utilizar uno existente
Agregar un nuevo proyecto
-
Crear proyecto
-
Detalles
-
Nombre: Demostración: your-name
-
Descripción: Demostración de ModelOps
-
Grupo: your-name
-
Credenciales: Sin credenciales
-
Rama: maestro
Aquí puede probar la conexión de git. Si el color es verde, guarde y continúe. Omita la configuración de conexión del servicio por ahora.
Al crear un nuevo proyecto, ModelOps le pedirá una nueva conexión.
Crear una conexión personal
Conexión personal
-
Nombre: Vantage personal your-name
-
Descripción: entorno de demostración Vantage
-
Host: tdprd.td.teradata.com (interno solo para teradata transcend)
-
Base de datos: your-db
-
Base de datos VAL: TRNG_XSP (interna solo para teradata transcend)
-
Base de datos BYOM: TRNG_BYOM (interna solo para teradata transcend)
-
Mec. de inicio de sesión: TDNEGO
-
Username/Password
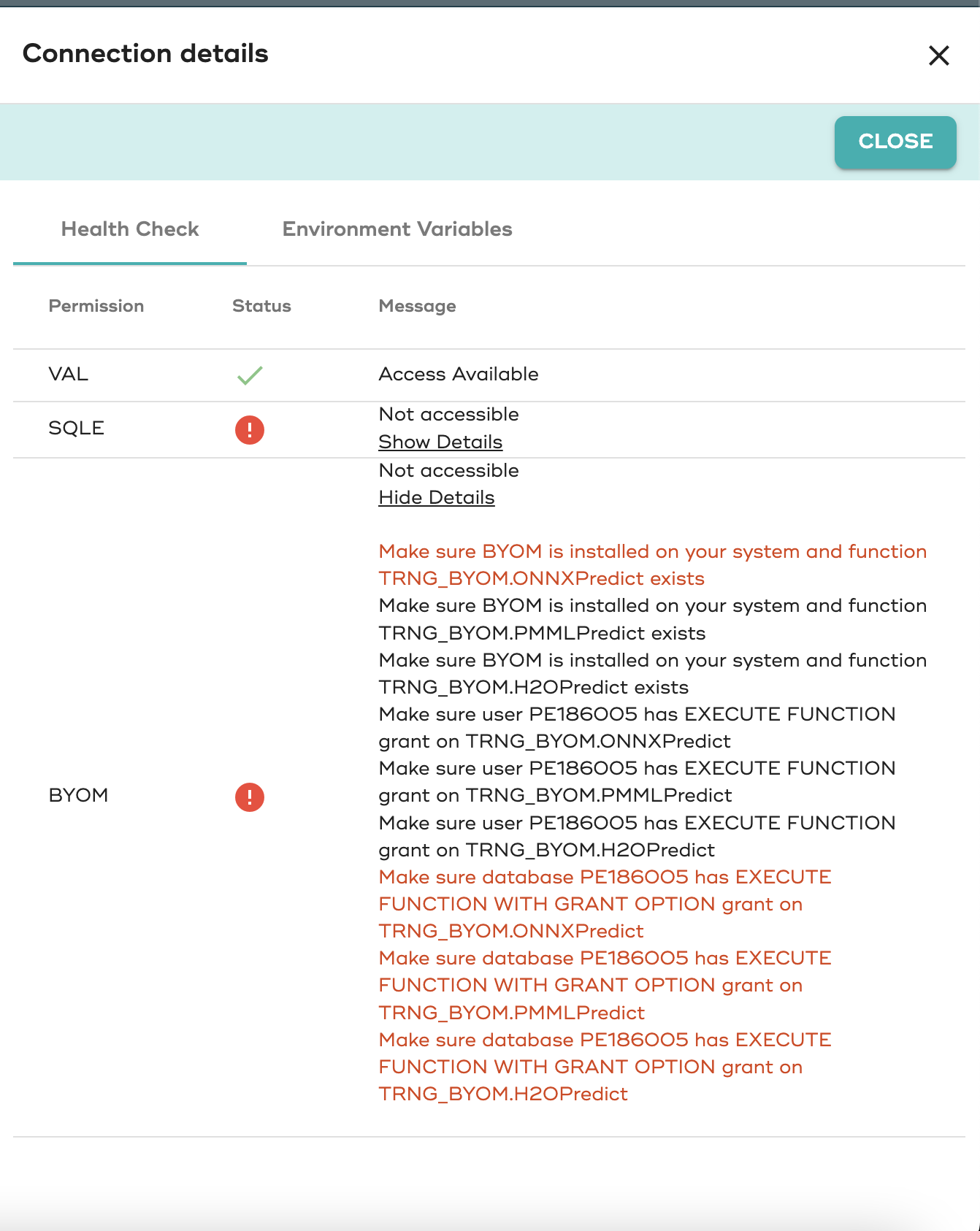
Validar permisos en base de datos SQL para VAL y BYOM
Puede comprobar los permisos con el nuevo panel de control de estado en el panel de conexiones
Agregue un conjunto de datos para identificar tablas Vantage para evaluación y puntuación BYOM
Creemos una nueva plantilla de conjunto de datos, luego 1 conjunto de datos para entrenamiento y 2 conjuntos de datos para evaluación para que podamos supervisar las métricas de calidad del modelo con 2 conjuntos de datos diferentes.
Agregar conjuntos de datos
-
Crear plantilla de conjunto de datos
-
Catalogar
-
Nombre: PIMA
-
Descripción: Diabetes PIMA
-
Catálogo de funciones: Vantage
-
Base de datos: your-db
-
Tabla: aoa_feature_metadata
Consulta de características:
Clave de entidad: PatientId Características: NumTimesPrg, PlGlcConc, BloodP, SkinThick, TwoHourSerIns, BMI, DiPedFunc, Age
Consulta de entidad y destino:
Clave de entidad: PatientId Objetivo: HasDiabetes
Predicciones
-
Base de datos: your-db
-
Tabla: pima_patient_predictions
Selección de entidad:
Consulta:
Solo para v6 (en v7 definirá esto en la pantalla BYOM sin código): Columna de destino BYOM: CAST(CAST(json_report AS JSON).JSONExtractValue('$.predicted_HasDiabetes') AS INT)
Crear conjunto de datos de entrenamiento
Básico
-
Nombre: Train
-
Descripción: Conjunto de datos de entrenamiento
-
Alcance: Entrenamiento
-
Entidad y destino
Consulta:
Crear conjunto de datos de evaluación 1
Básico
-
Nombre: Evaluate
-
Descripción: Conjunto de datos de evaluación
-
Alcance: Evaluación
-
Entidad y destino
Consulta:
Crear conjunto de datos de evaluación 2
Básico
-
Nombre: Evaluate
-
Descripción: Conjunto de datos de evaluación
-
Alcance: Evaluación
-
Entidad y destino
Consulta:
Preparar plantillas de código
Para los modelos Git, debemos completar las plantillas de código disponibles al agregar un nuevo modelo.
Estos scripts de código se almacenarán en el repositorio de git en: model_definitions/your-model/model_modules/
-
init.py: este es un archivo vacío requerido para los módulos de Python
-
training.py: este script contiene la función de entrenamiento
Revise el cuaderno Operationalize para ver cómo puede ejecutar esto desde la CLI o desde el cuaderno como alternativa a la interfaz de usuario de ModelOps.
- evaluation.py: este script contiene la función de evaluación
Revise el cuaderno Operationalize para ver cómo puede ejecutar esto desde la CLI o desde el cuaderno como alternativa a la interfaz de usuario de ModelOps.
- scoring.py: este script contiene la función de puntuación
Revise el cuaderno Operationalize para ver cómo puede ejecutar esto desde la CLI o desde el cuaderno como alternativa a la interfaz de usuario de ModelOps.
- requirements.txt: este archivo contiene los nombres de biblioteca y las versiones necesarias para sus scripts de código. Ejemplo:
- config.json: este archivo ubicado en la carpeta principal (carpeta de su modelo) contiene hiperparámetros predeterminados
Vaya y revise los scripts de código para el modelo de demostración en el repositorio: https://github.com/Teradata/modelops-demo-models/
Vaya a model_definitions->python-diabetes->model_modules
Modelo de ciclo de vida para un nuevo GIT
-
Abra Proyecto para ver los modelos disponibles en GIT
-
Entrenar una nueva versión del modelo
-
vea cómo se rastrea el CommitID del repositorio de código
-
Evaluar
-
Revisar el informe de evaluación, incluidas las estadísticas del conjunto de datos y las métricas del modelo
-
Comparar con otras versiones de modelo
-
Aprobar
-
Implementar en Vantage: motor, publicación, programación. Se requiere un conjunto de datos de puntuación Utilice su conexión y seleccione una base de datos. por ejemplo, "aoa_byom_models"
-
Implementar en Docker Batch: motor, publicar, programar. Se requiere un conjunto de datos de puntuación Utilice su conexión y seleccione una base de datos. por ejemplo, "aoa_byom_models"
-
Implementar en lotes Restful: motor, publicar, programar. Se requiere un conjunto de datos de puntuación Utilice su conexión y seleccione una base de datos. por ejemplo, "aoa_byom_models"
-
Implementaciones/ejecuciones
-
Evalúe nuevamente con el conjunto de datos 2: para supervisar el comportamiento de las métricas del modelo
-
Supervisar el desfase del modelo: datos y métricas
-
Abra el cuaderno BYOM para ejecutar la predicción PMML a partir del código SQL cuando se implemente en Vantage
-
Pruebe Restful desde la interfaz de usuario de ModelOps o desde el comando curl
-
Retirar implementaciones
Resumen
En este inicio rápido, hemos aprendido cómo seguir un ciclo de vida completo de modelos GIT en ModelOps y cómo implementarlo en Vantage o en contenedores Docker para implementaciones Edge. Entonces, ¿cómo podemos programar una puntuación por lotes o probar puntuaciones de restful o bajo demanda y comenzar a supervisar las métricas de desfase de datos y calidad del modelo?
Lectura adicional
Si tiene alguna pregunta o necesita más ayuda, visite nuestro foro de la comunidad donde podrá obtener ayuda e interactuar con otros miembros de la comunidad.