Entrenar modelos de ML en Vantage usando funciones analíticas de bases de datos
Información general
Hay situaciones en las que desea validar rápidamente una idea de modelo de aprendizaje automático. Tiene un tipo de modelo en mente. No desea poner en funcionamiento una canalización de ML todavía. Solo quiere probar si la relación que tenía en mente existe. Además, a veces incluso su implementación de producción no requiere un reaprendizaje constante con MLops. En tales casos, puede utilizar funciones analíticas de bases de datos para ingeniería de características, entrenar diferentes modelos de ML, calificar sus modelos y evaluar su modelo en diferentes funciones de evaluación de modelos.
Prerrequisitos
Necesita acceso a una instancia de Teradata Vantage.
Si necesita una instancia de prueba de Vantage, puede obtener una de forma gratuita en https://clearscape.teradata.com
Cargar datos de muestra
Aquí, en este ejemplo, utilizaremos los datos de muestra de la base de datos val. Usaremos las tablas accounts, customer y transactions. Crearemos algunas tablas en el proceso y es posible que surjan algunos problemas al crear tablas en la base de datos val, así que vamos a crear nuestra propia base de datos td_analytics_functions_demo.
Debe tener permisos CREATE TABLE en la base de datos donde desea utilizar las funciones de análisis de la base de datos.
Ahora creemos tablas accounts, customer y transactions en nuestra base de datos td_analytics_functions_demo a partir de las tablas correspondientes en la base de datos val.
Comprender los datos de muestra
Ahora que tenemos nuestras tablas de muestra cargadas en td_analytics_functions_demo, exploremos los datos. Es un conjunto de datos simplista y ficticio de clientes bancarios (700 filas), cuentas (1400 filas) y transacciones (77K filas). Están relacionados entre sí de las siguientes maneras:
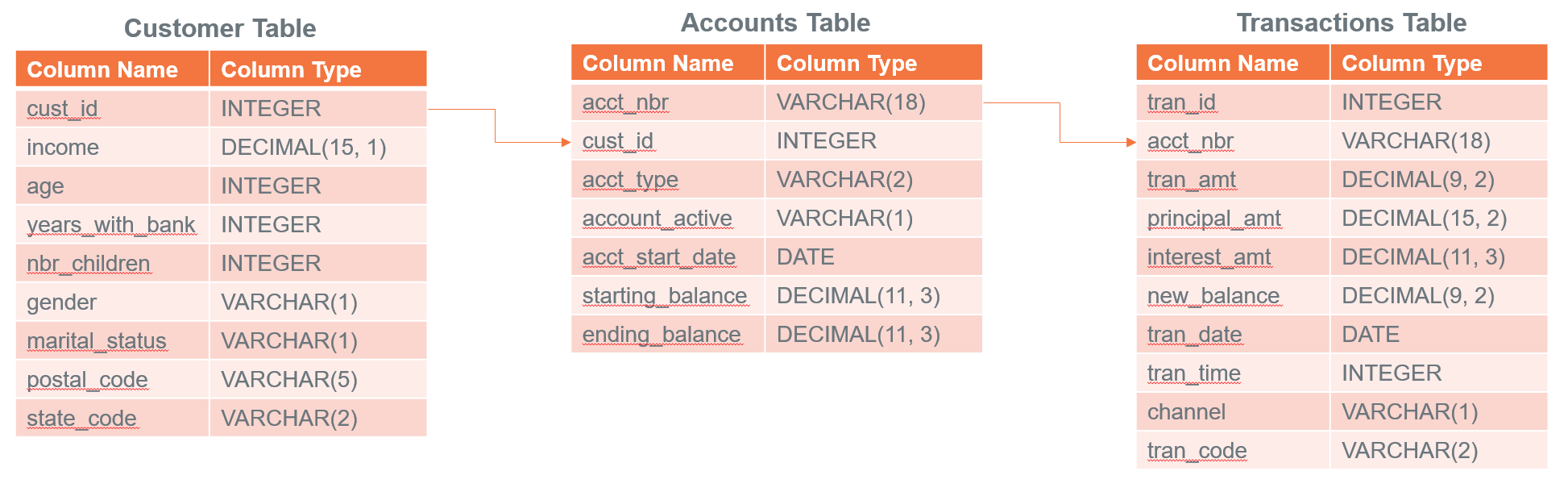
En partes posteriores de este tutorial, exploraremos si podemos construir un modelo que prediga el saldo mensual promedio que un cliente bancario tiene en su tarjeta de crédito en función de todas las variables no relacionadas con la tarjeta de crédito en las tablas.
Preparar el conjunto de datos
Tenemos datos en tres tablas diferentes que queremos unir y crear funciones. Comencemos creando una tabla unida.
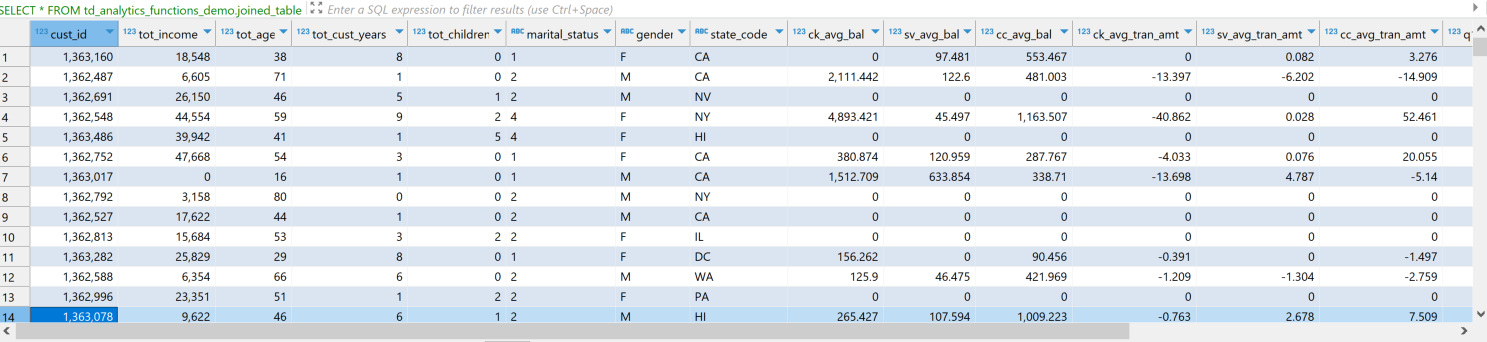
Veamos ahora cómo se ven nuestros datos. El conjunto de datos tiene características tanto categóricas como continuas o variables independientes. En nuestro caso, la variable dependiente es cc_avg_bal, que es el saldo promedio de la tarjeta de crédito del cliente.
Ingeniería de características
Al observar los datos, vemos que hay varias características que podemos tener en cuenta para predecir el cc_avg_bal.
TD_OneHotEncodingFit
Dado que tenemos algunas características categóricas en nuestro conjunto de datos, como gender, marital status y state code, aprovecharemos la función de analíticas de base de datos TD_OneHotEncodingFit para codificar categorías en vectores numéricos one-hot.
TD_ScaleFit
Si miramos los datos, algunas columnas como tot_income, tot_age y ck_avg_bal tienen valores en diferentes rangos. Para los algoritmos de optimización como el descenso de gradiente, es importante normalizar los valores a la misma escala para una convergencia más rápida, una coherencia de escala y un mejor rendimiento del modelo. Aprovecharemos la función TD_ScaleFit para normalizar valores en diferentes escalas.
TD_ColumnTransformer
Las funciones analíticas de bases de datos de Teradata normalmente operan en pares para transformaciones de datos. El paso inicial está dedicado a "ajustar" los datos. Posteriormente, la segunda función utiliza los parámetros derivados del proceso de ajuste para ejecutar la transformación real de los datos. TD_ColumnTransformer lleva las tablas FIT a la función y transforma las columnas de la tabla de entrada en una sola operación.
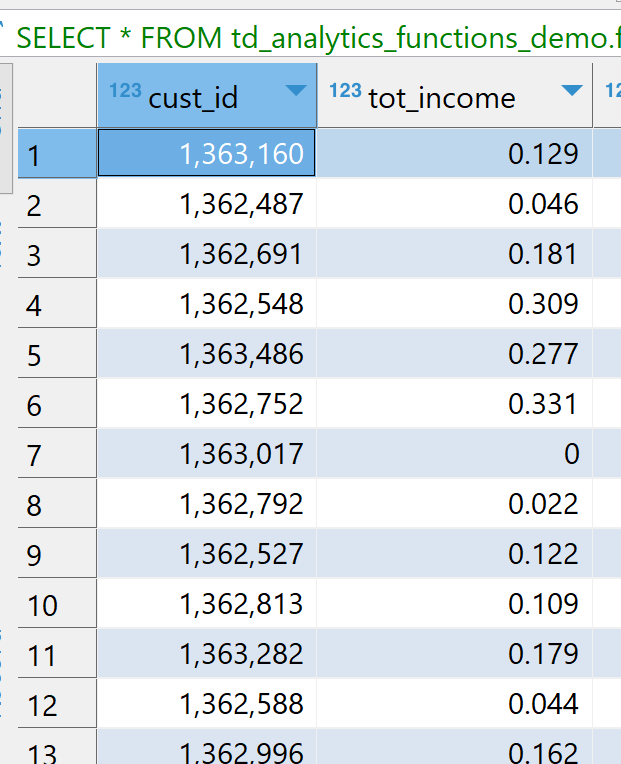
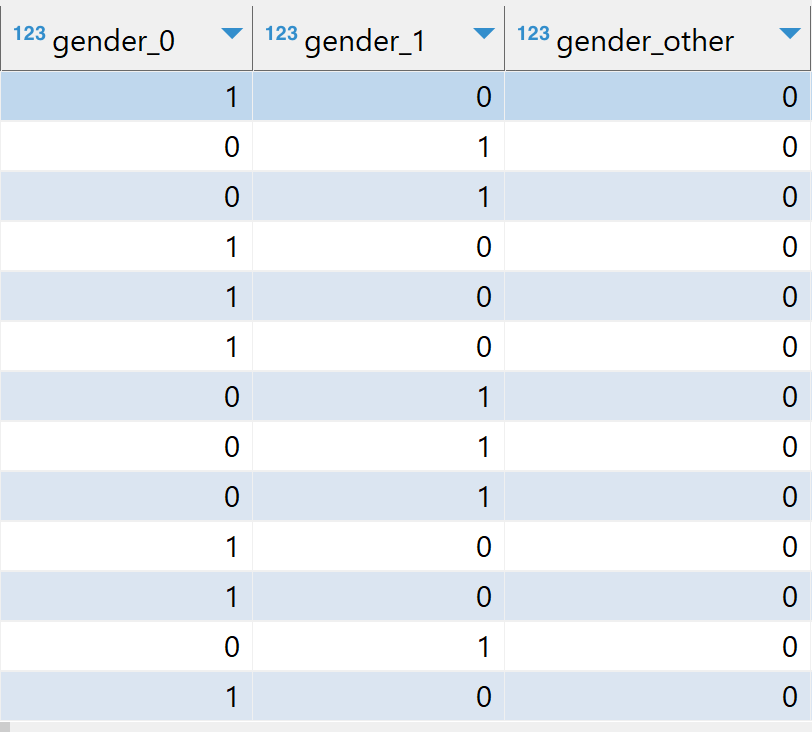
Una vez que realizamos la transformación, podemos ver nuestras columnas categóricas con codificación one-hot y valores numéricos escalados como se puede ver en la imagen a continuación. Por ejemplo: tot_income está en el rango [0,1], gender tiene codificación one-hot en gender_0, gender_1, gender_other.
División en entrenamiento y pruebas
Como tenemos nuestro conjunto de datos listo con funciones escaladas y codificadas, ahora dividamos nuestro conjunto de datos en partes de entrenamiento (75 %) y pruebas (25 %). Las funciones analíticas de bases de datos de Teradata proporcionan la función TD_TrainTestSplit, que aprovecharemos para dividir nuestro conjunto de datos.
Como se puede ver en la imagen a continuación, la función agrega una nueva columna TD_IsTrainRow.
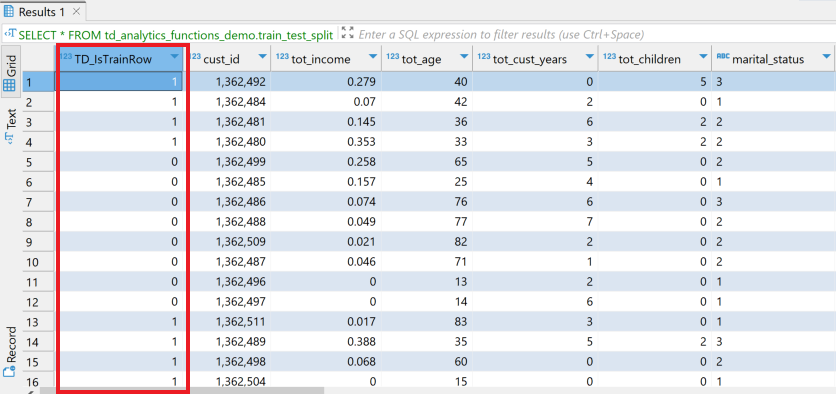
Usaremos TD_IsTrainRow para crear dos tablas, una para entrenamiento y otra para pruebas.
Entrenamiento con modelo lineal generalizado
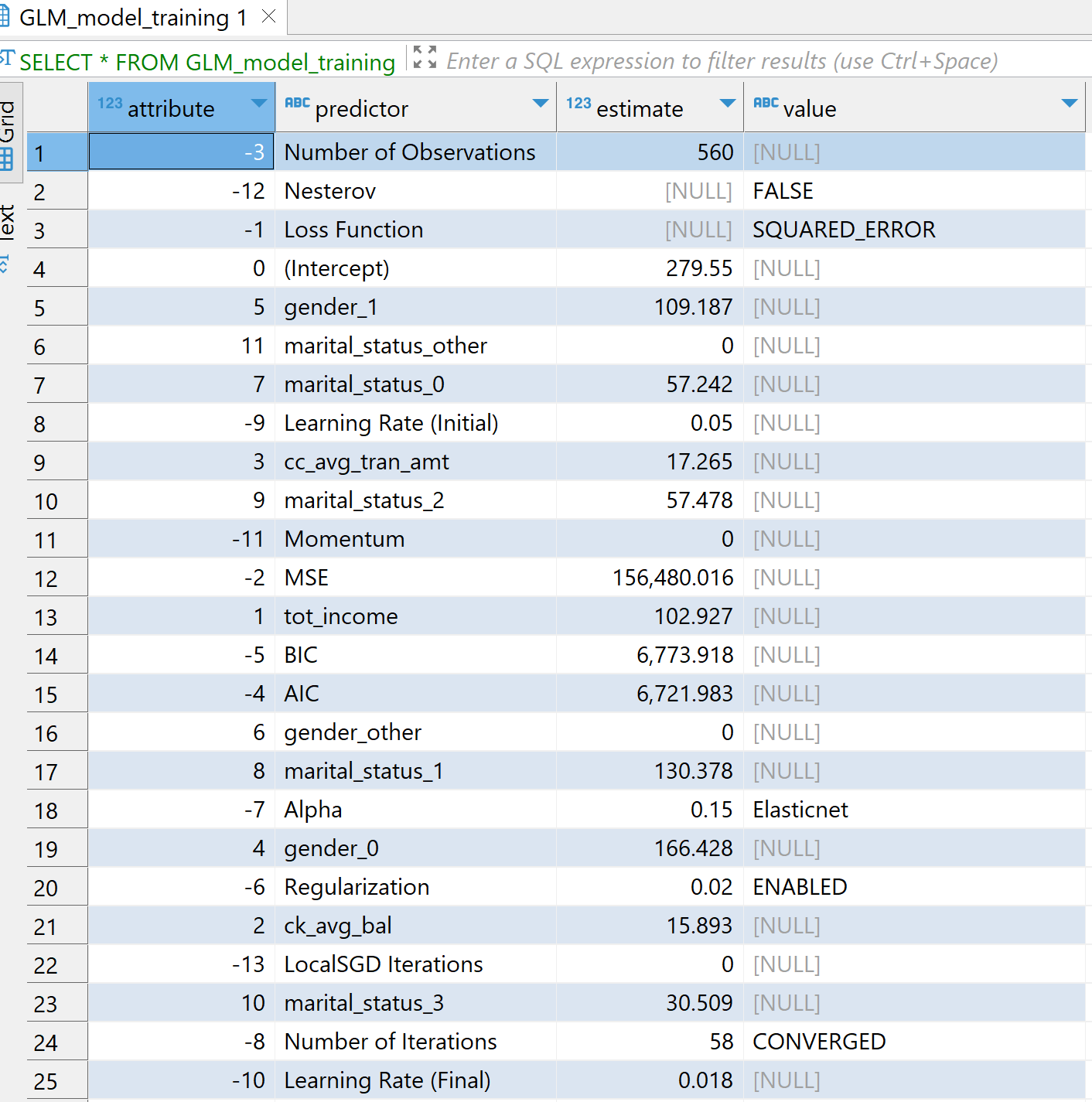
Ahora usaremos la función analítica de base de datos TD_GLM para entrenar en nuestro conjunto de datos de entrenamiento. La función TD_GLM es un modelo lineal generalizado (generalized linear model, GLM) que realiza analíticas de regresión y clasificación en conjuntos de datos. Aquí hemos utilizado un montón de columnas de entrada como tot_income, ck_avg_bal,cc_avg_tran_amt, valores con codificación one-hot para estado civil, género y estados. cc_avg_bal es nuestra columna dependiente o de respuesta que es continua y, por tanto, es un problema de regresión. Usamos Family como Gaussian para regresión y Binomial para clasificación.
El parámetro Tolerance significa la mejora mínima requerida en la precisión de la predicción para que el modelo detenga las iteraciones y MaxIterNum significa el número máximo de iteraciones permitidas. El modelo concluye el entrenamiento según la condición que se cumpla primero. Por ejemplo, en el siguiente ejemplo, el modelo es CONVERGED después de 58 iteraciones.
Puntuación en el conjunto de datos de prueba
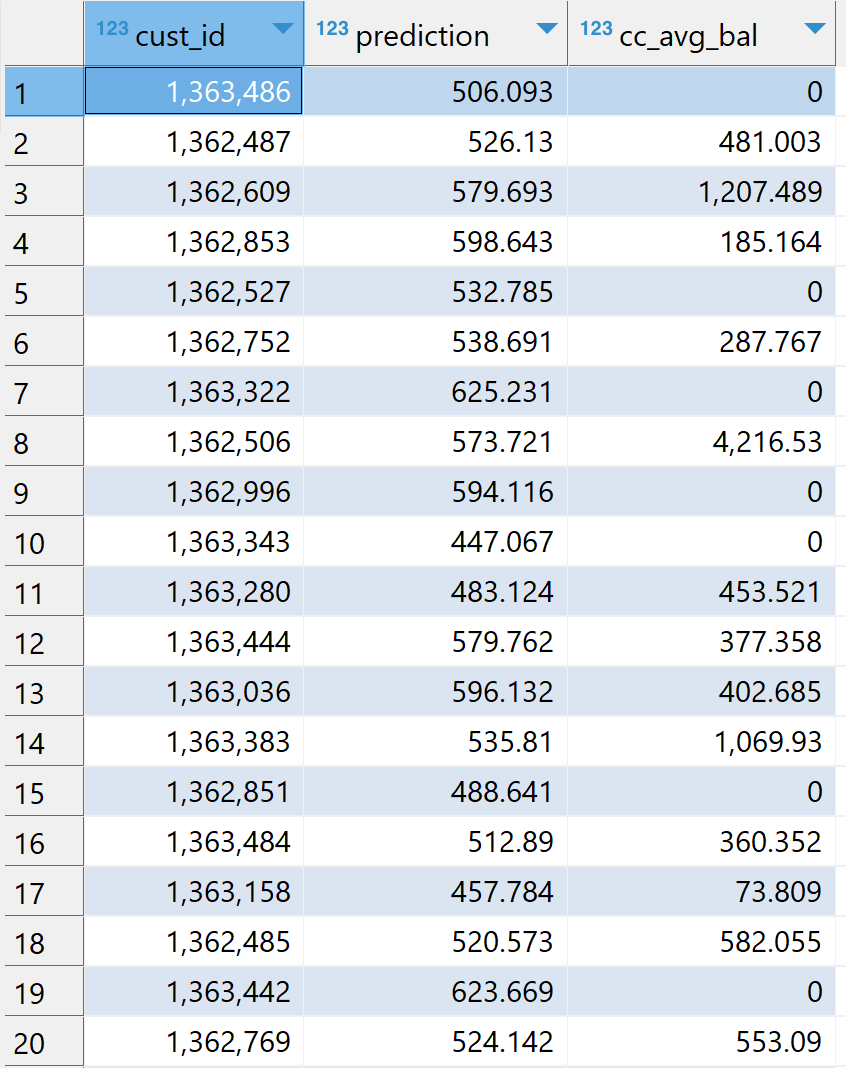
Ahora usaremos nuestro modelo GLM_model_training para puntuar nuestro conjunto de datos de prueba testing_table usando la función analítica de base de datos (enlace: TD_GLMPredict).
Evaluación del modelo
Finalmente, evaluamos nuestro modelo en función de los resultados puntuados. Aquí estamos usando la función TD_RegressionEvaluator. El modelo se puede evaluar en función de parámetros como R2, RMSE, F_score.

El propósito de este tutorial no es describir la ingeniería de funciones, sino demostrar cómo podemos aprovechar diferentes funciones analíticas de bases de datos en Vantage. Es posible que los resultados del modelo no sean óptimos y el proceso para crear el mejor modelo está fuera del alcance de este artículo.
Resumen
En este inicio rápido, hemos aprendido cómo crear modelos de ML utilizando funciones analíticas de base de datos Teradata. Construimos nuestra propia base de datos td_analytics_functions_demo con datos customer,accounts, transactions, val de la base de datos. Realizamos ingeniería de características transformando las columnas usando TD_OneHotEncodingFit, TD_ScaleFit y TD_ColumnTransformer. Luego usamos TD_TrainTestSplit para dividir entre entrenamiento y pruebas. Entrenamos nuestro conjunto de datos de entrenamiento con el modelo TD_GLM y calificamos nuestro conjunto de datos de prueba. Finalmente evaluamos nuestros resultados puntuados usando la función TD_RegressionEvaluator.
Lectura adicional
Si tiene alguna pregunta o necesita más ayuda, visite nuestro foro de la comunidad donde podrá obtener ayuda e interactuar con otros miembros de la comunidad.