Utilizar AWS SageMaker con Teradata Vantage
Información general
Este tutorial le ayudará a integrar Amazon SageMaker con Teradata Vantage. El enfoque que explica esta guía es uno de los muchos enfoques potenciales para integrarse con el servicio.
Amazon SageMaker proporciona una plataforma de aprendizaje automático totalmente administrada. Hay dos casos de uso para Amazon SageMaker y Teradata:
-
Los datos que residen en Teradata Vantage y Amazon SageMaker se utilizarán tanto para la definición del modelo como para la puntuación posterior. En este caso de uso, Teradata proporcionará datos en el entorno de Amazon S3 para que Amazon SageMaker pueda consumir conjuntos de datos de entrenamiento y prueba con el fin de desarrollar modelos. Teradata además pondría los datos a disposición a través de Amazon S3 para su posterior puntuación por parte de Amazon SageMaker. Según este modelo, Teradata es únicamente un repositorio de datos.
-
Los datos que residen en Teradata Vantage y Amazon SageMaker se utilizarán para la definición del modelo, y Teradata para la puntuación posterior. En este caso de uso, Teradata proporcionará datos en el entorno de Amazon S3 para que Amazon SageMaker pueda consumir conjuntos de datos de entrenamiento y prueba con el fin de desarrollar modelos. Teradata deberá importar el modelo de Amazon SageMaker a una tabla de Teradata para su posterior puntuación por parte de Teradata Vantage. Según este modelo, Teradata es un depósito de datos y un motor de puntuación.
El primer caso de uso se analiza en este documento.
Amazon SageMaker consume datos de prueba y entrenamiento de un depósito de Amazon S3. Este artículo describe cómo cargar conjuntos de datos de análisis de Teradata en un depósito de Amazon S3. Luego, los datos pueden estar disponibles para Amazon SageMaker para crear y entrenar modelos de aprendizaje automático e implementarlos en un entorno de producción.
Prerrequisitos
- Acceso a una instancia de Teradata Vantage.
Nota
Si necesita una instancia de prueba de Vantage, puede obtener una de forma gratuita en https://clearscape.teradata.com
- Permiso de IAM para acceder al depósito de Amazon S3 y utilizar el servicio Amazon SageMaker.
- Un depósito de Amazon S3 para almacenar datos de entrenamiento.
Cargar datos
Amazon SageMaker entrena datos desde un depósito de Amazon S3. Los siguientes son los pasos para cargar datos de entrenamiento desde Vantage a un depósito de Amazon S3:
-
Vaya a la consola de Amazon SageMaker y cree una instancia de cuaderno. Consulte la Guía para desarrolladores de Amazon SageMaker para obtener instrucciones sobre cómo crear una instancia de cuaderno:
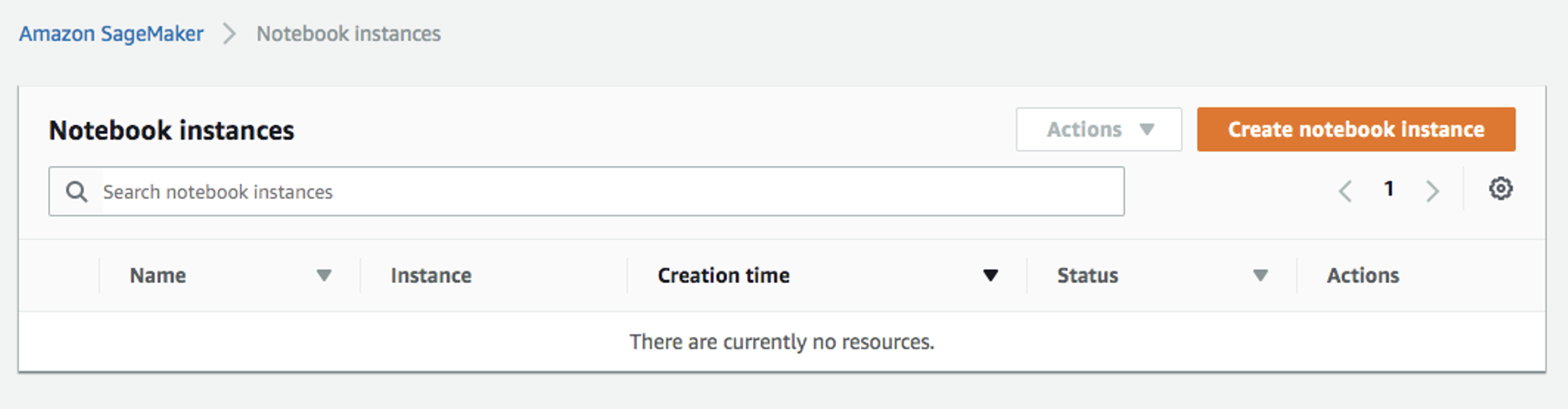
-
Abra la instancia de su cuaderno:
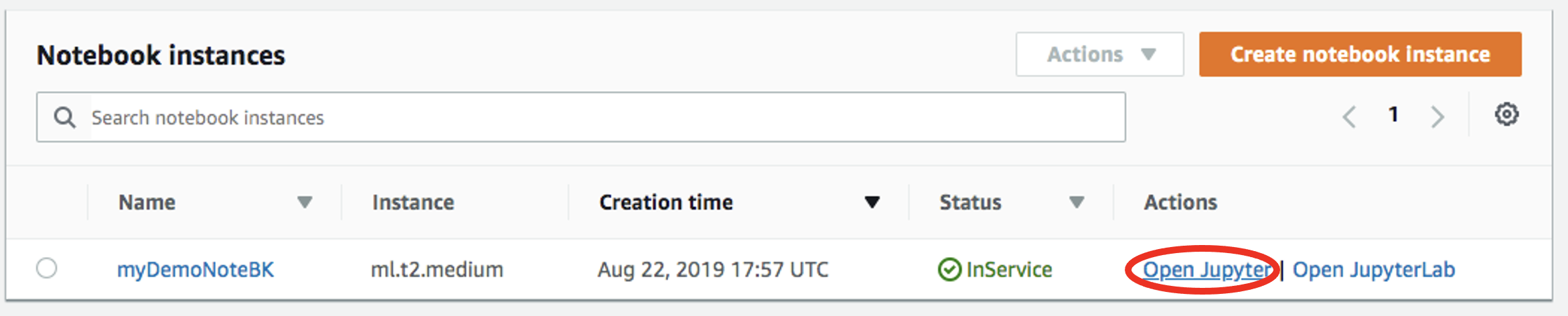
-
Inicie un nuevo archivo haciendo clic en
New -> conda_python3: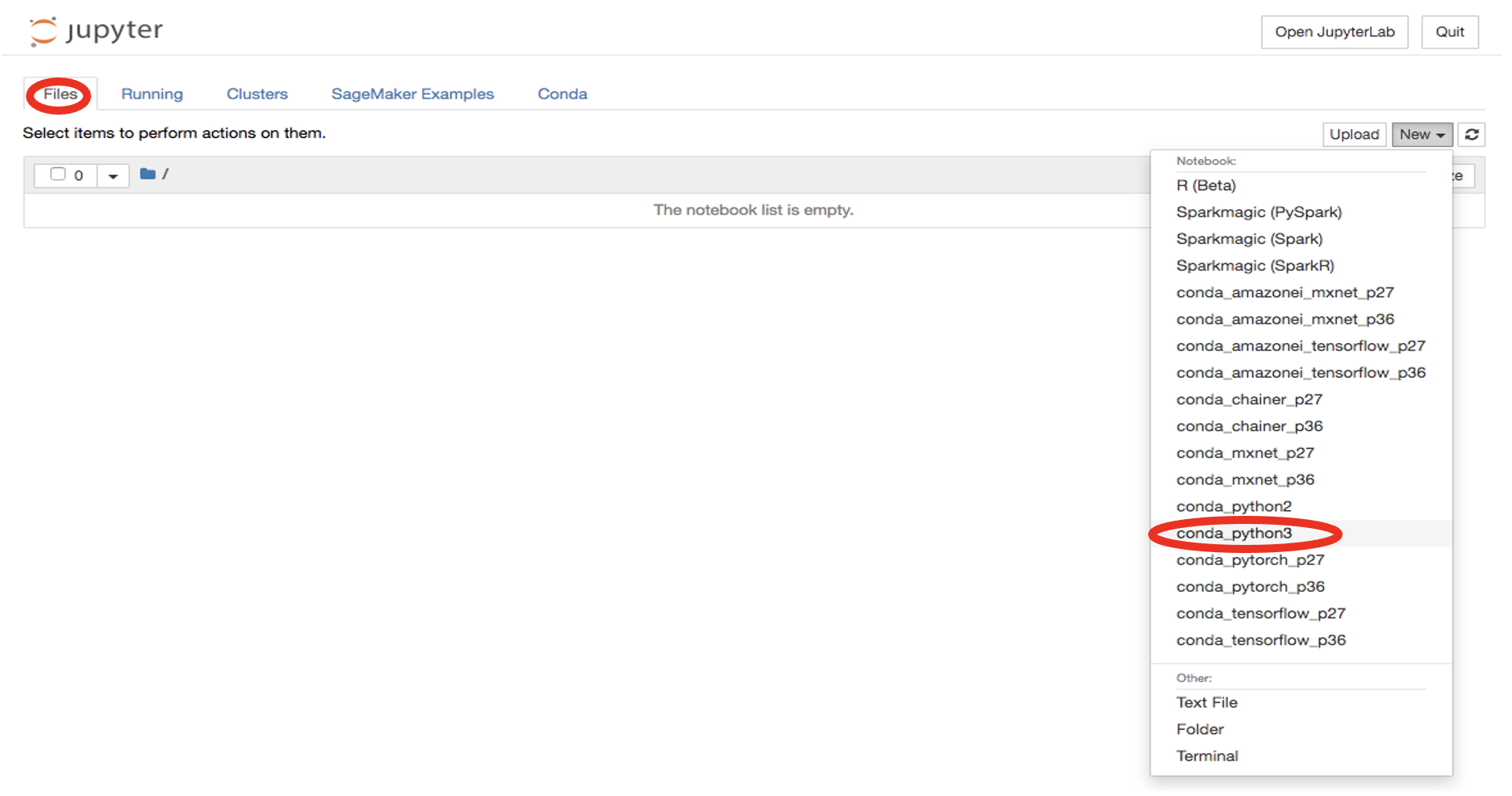
-
Instale la biblioteca Teradata Python:
-
En una nueva celda, importe bibliotecas adicionales:
-
En una celda nueva, conéctese a Teradata Vantage. Reemplace
<hostname>,<database user name>,<database password>para que coincida con su entorno Vantage: -
Recupere datos de la tabla donde reside el conjunto de datos de entrenamiento utilizando la API TeradataML DataFrame:
-
Escriba datos en un archivo local:
-
Cargue el archivo en Amazon S3:
Entrenar el modelo
-
Seleccione
Training jobsen el menú de la izquierda debajo deTrainingy, posteriormente, haga clic enCreate training job: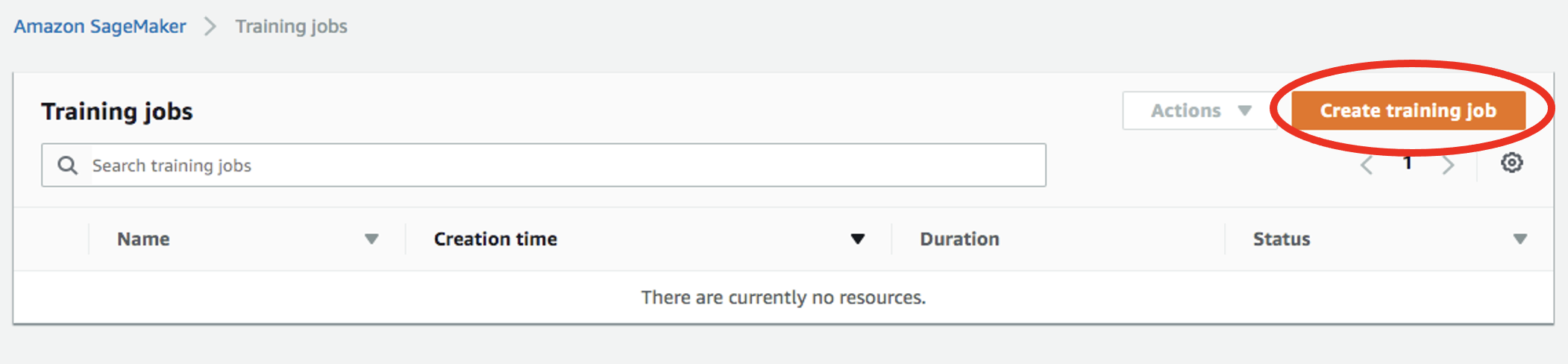
-
En la ventana
Create training job, completeJob name(por ejemplo,xgboost-bank) yCreate a new rolepara el rol de IAM. ElijaAny S3 bucketpara los depósitos de Amazon S3 yCreate role: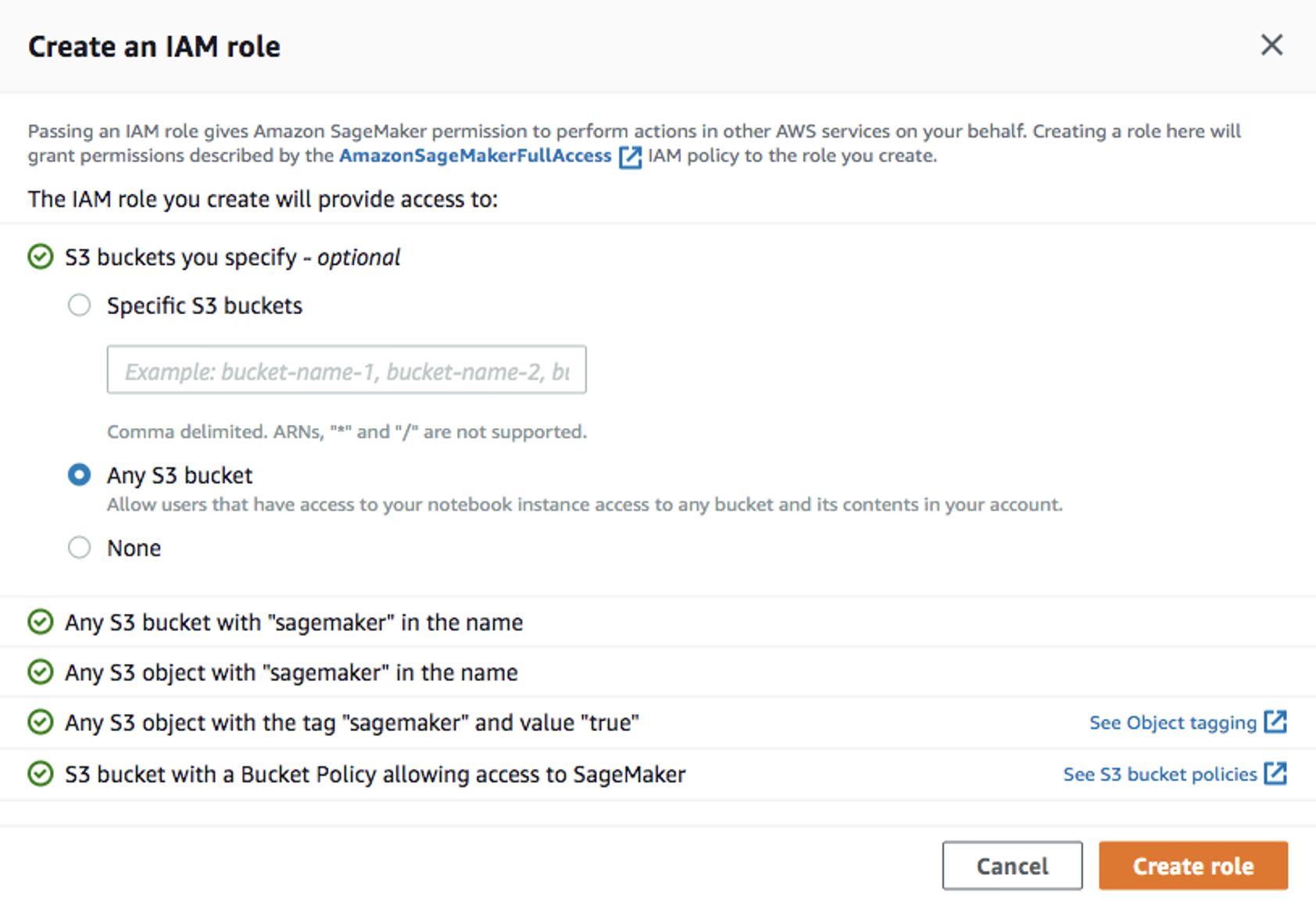
-
De nuevo en la ventana
Create training job, useXGBoostcomo algoritmo: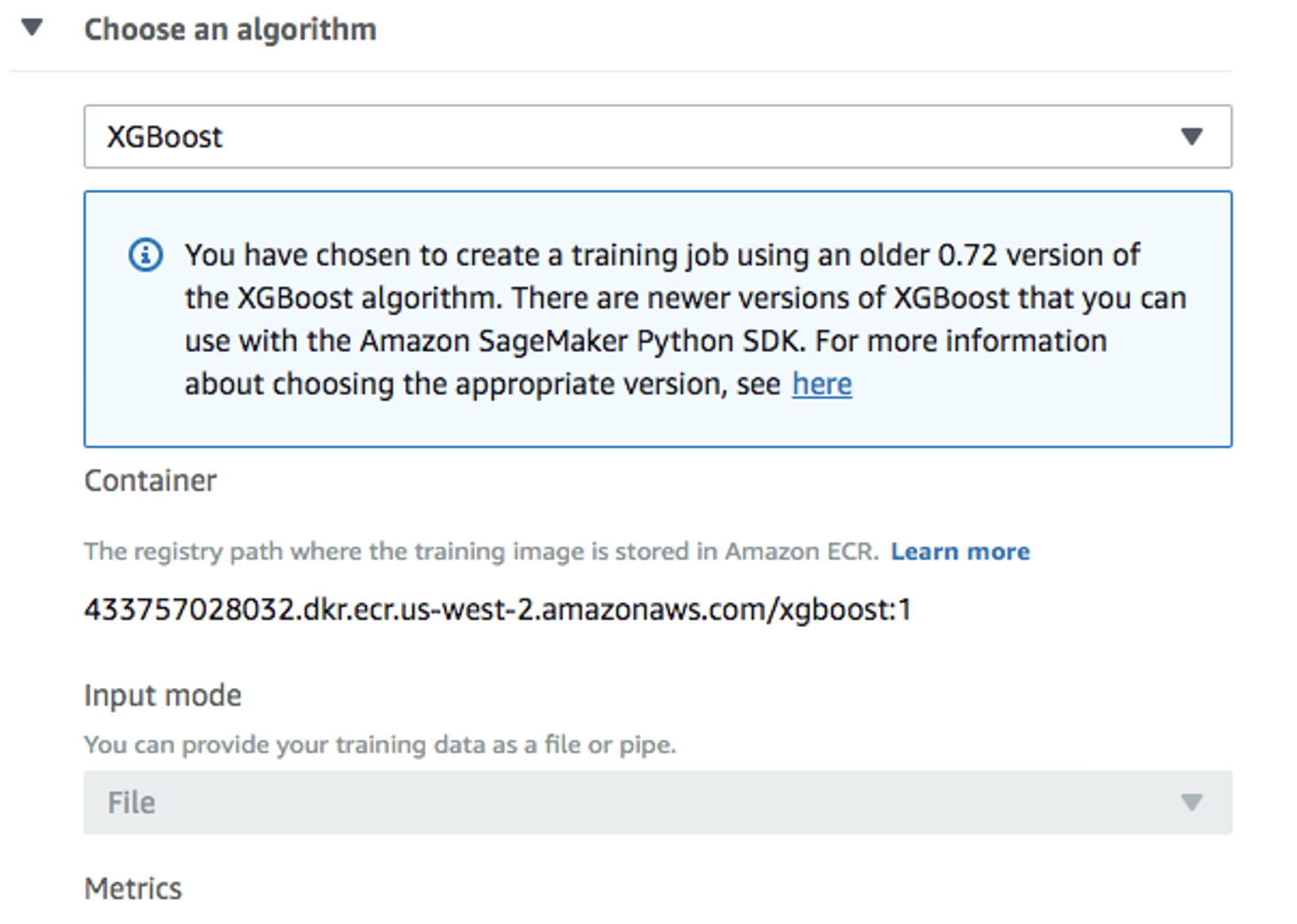
-
Utilice el tipo de instancia
ml.m4.xlargepredeterminado y 30 GB de volumen de almacenamiento adicional por instancia. Este es un trabajo de entrenamiento corto, no debería llevar más de 10 minutos. 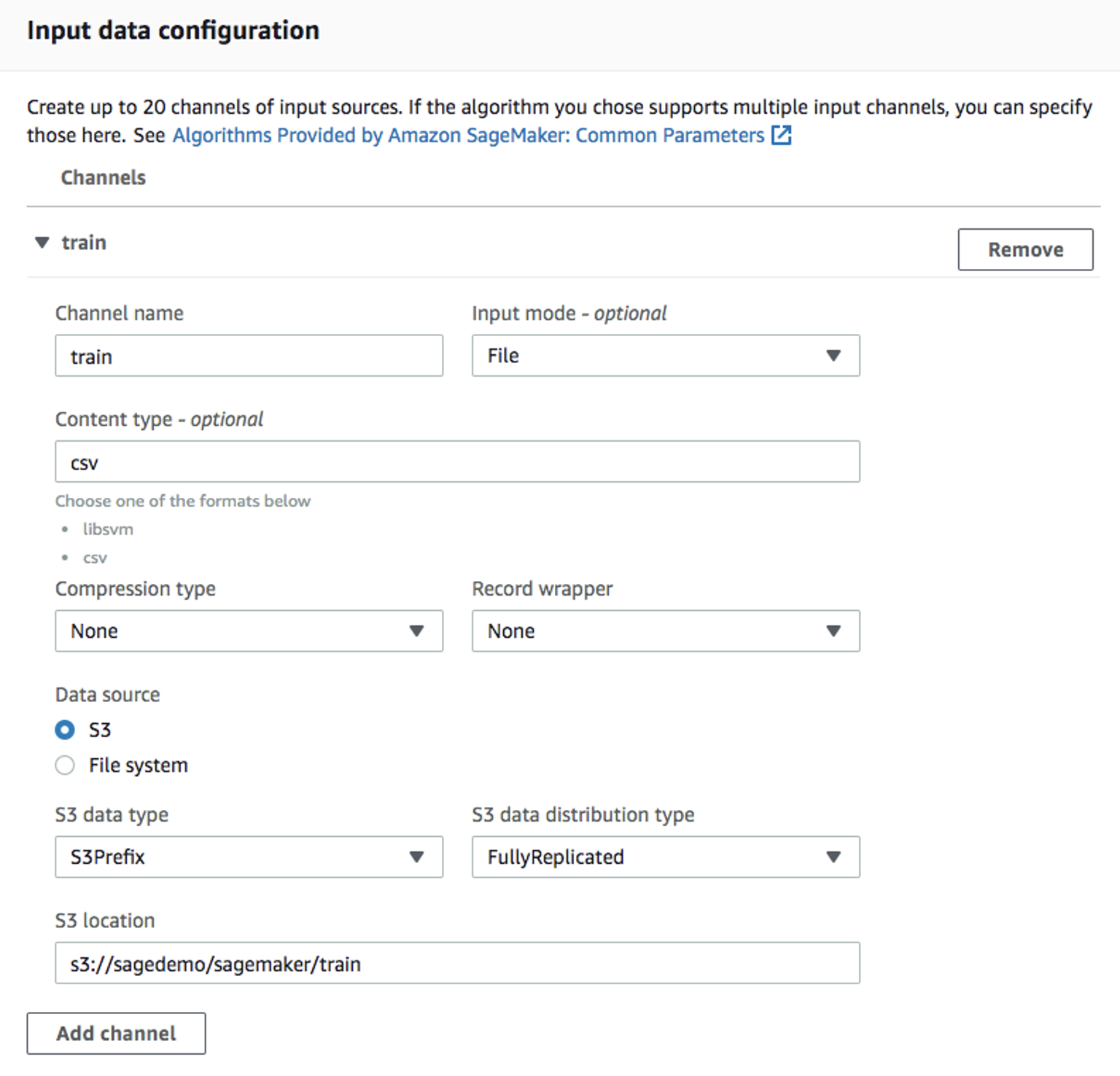
-
Para
Output data configuration, introduzca la ruta donde se almacenarán los datos de salida: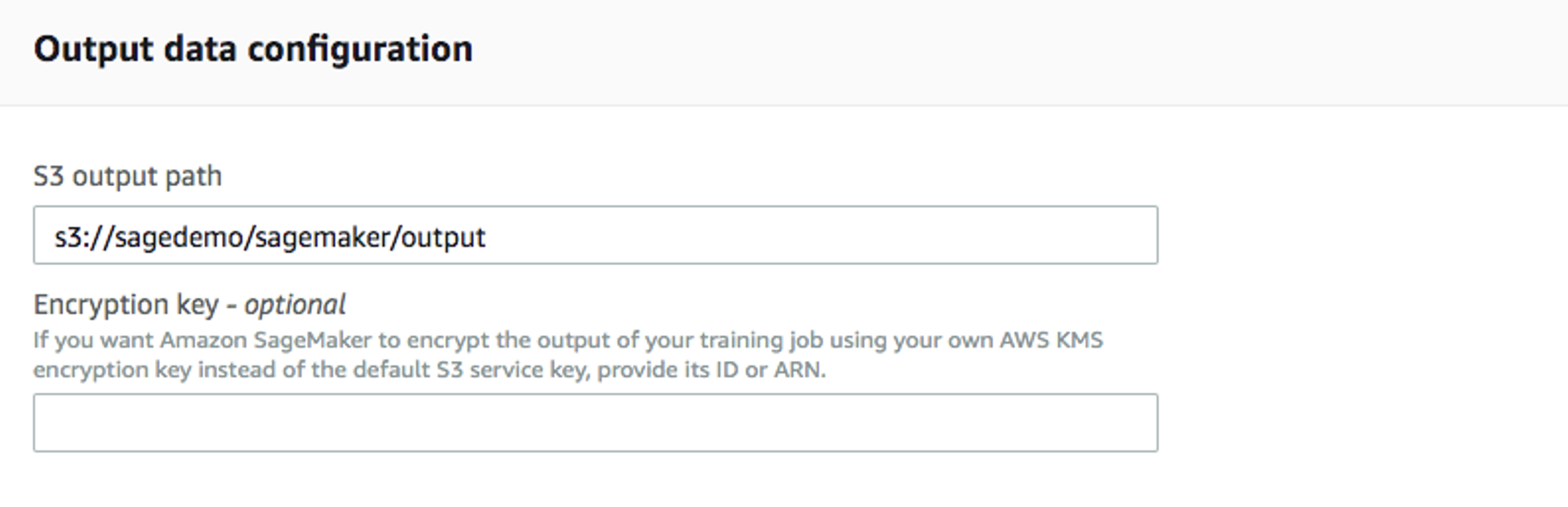
-
Deje los valores predeterminados para todo lo demás y haga clic en "Crear trabajo de entrenamiento". Puede encontrar instrucciones detalladas sobre cómo configurar el trabajo de entrenamiento en la [Guía para desarrolladores de Amazon SageMaker] (https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-mkt-algo-train.html#sagemaker-mkt-algo-train-console).
Una vez creado el trabajo de entrenamiento, Amazon SageMaker lanza las instancias de ML para entrenar el modelo y almacena los artefactos del modelo resultantes y otros resultados en Output data configuration (path/<training job name>/output de forma predeterminada).
Implementar el modelo
Después de entrenar su modelo, impleméntelo usando un punto final persistente
Crear un modelo
- Seleccione
ModelsenInferenceen el panel izquierdo, luegoCreate model. Complete el nombre del modelo (por ejemplo,xgboost-bank), y elija el rol de IAM que creó en el paso anterior. - Para
Container definition 1, utilice433757028032.dkr.ecr.us-west-2.amazonaws.com/xgboost:latestcomoLocation of inference code image.Location of model artifactses la ruta de salida de su trabajo de entrenamiento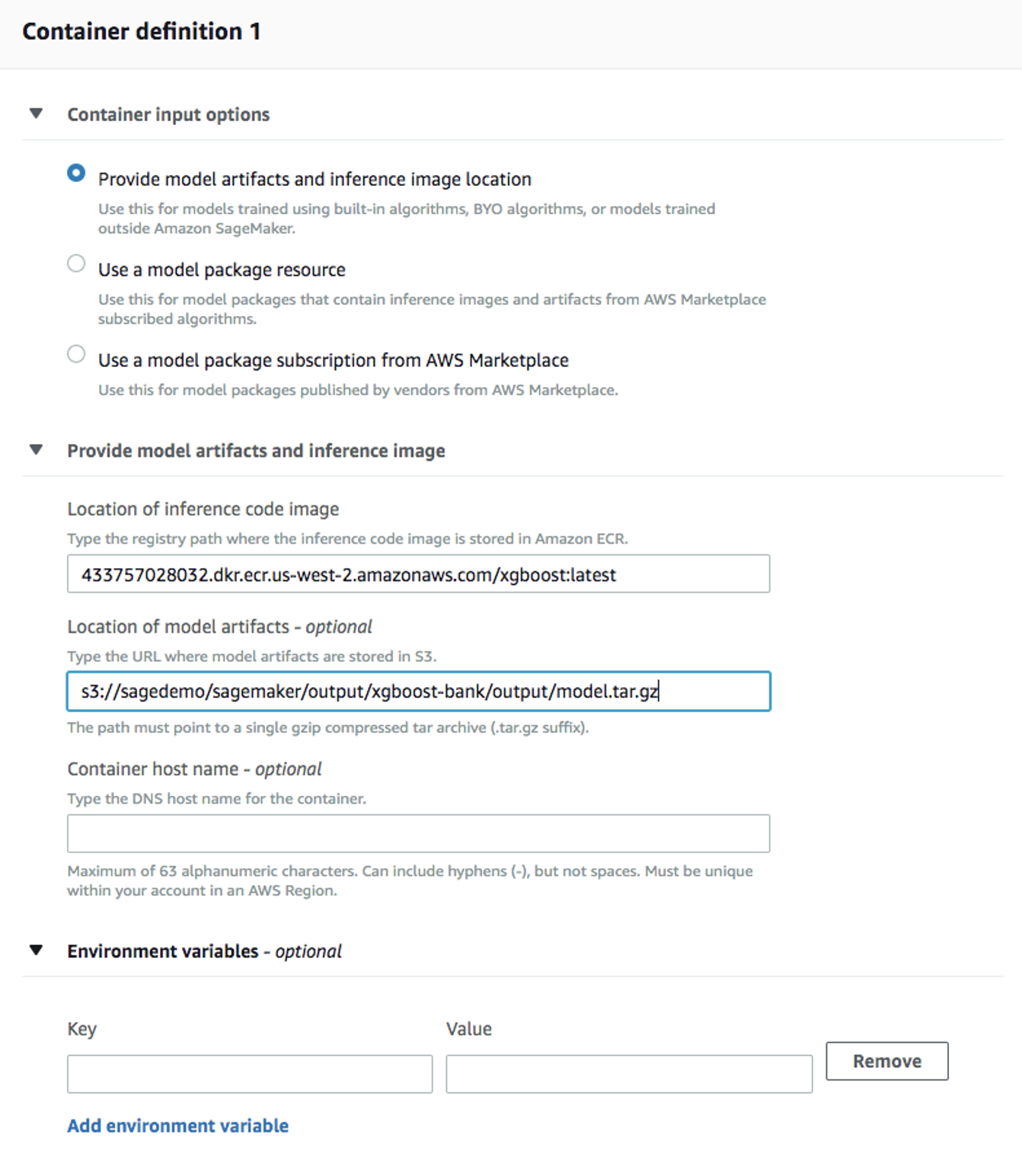
- Deje los valores predeterminados para todo lo demás, luego
Create model.
Crear una configuración de punto final
-
Seleccione el modelo que acaba de crear y luego haga clic en
Create endpoint configuration: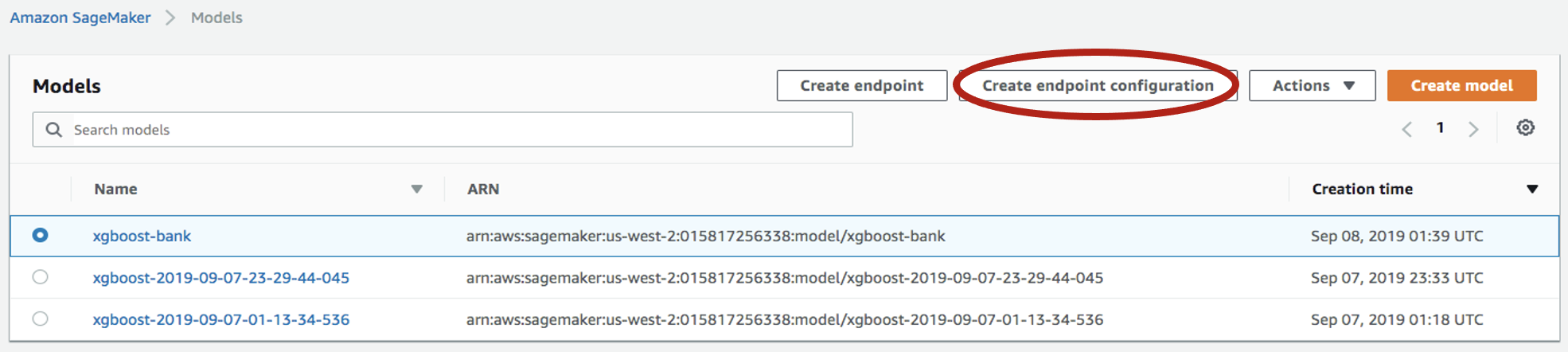
-
Complete el nombre (por ejemplo,
xgboost-bank) y use los valores predeterminados para todo lo demás. El nombre del modelo y el trabajo de entrenamiento deberían completarse automáticamente. Haga clic enCreate endpoint configuration.
Create endpoint
-
Seleccione
Inference->Modelsen el panel izquierdo, seleccione el modelo nuevamente y haga clic enCreate endpointesta vez: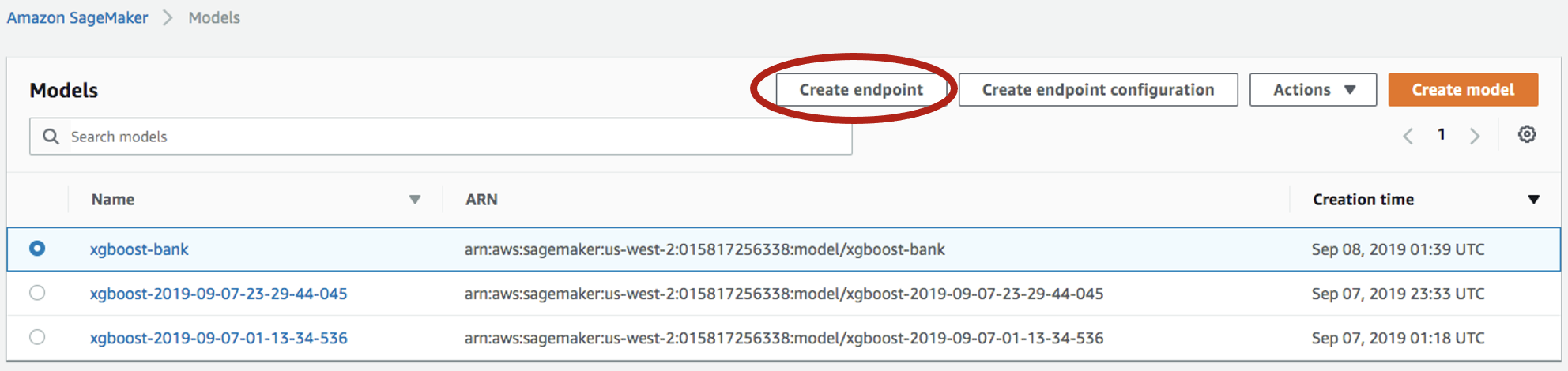
-
Complete el nombre (por ejemplo,
xgboost-bank) y seleccioneUse an existing endpoint configuration: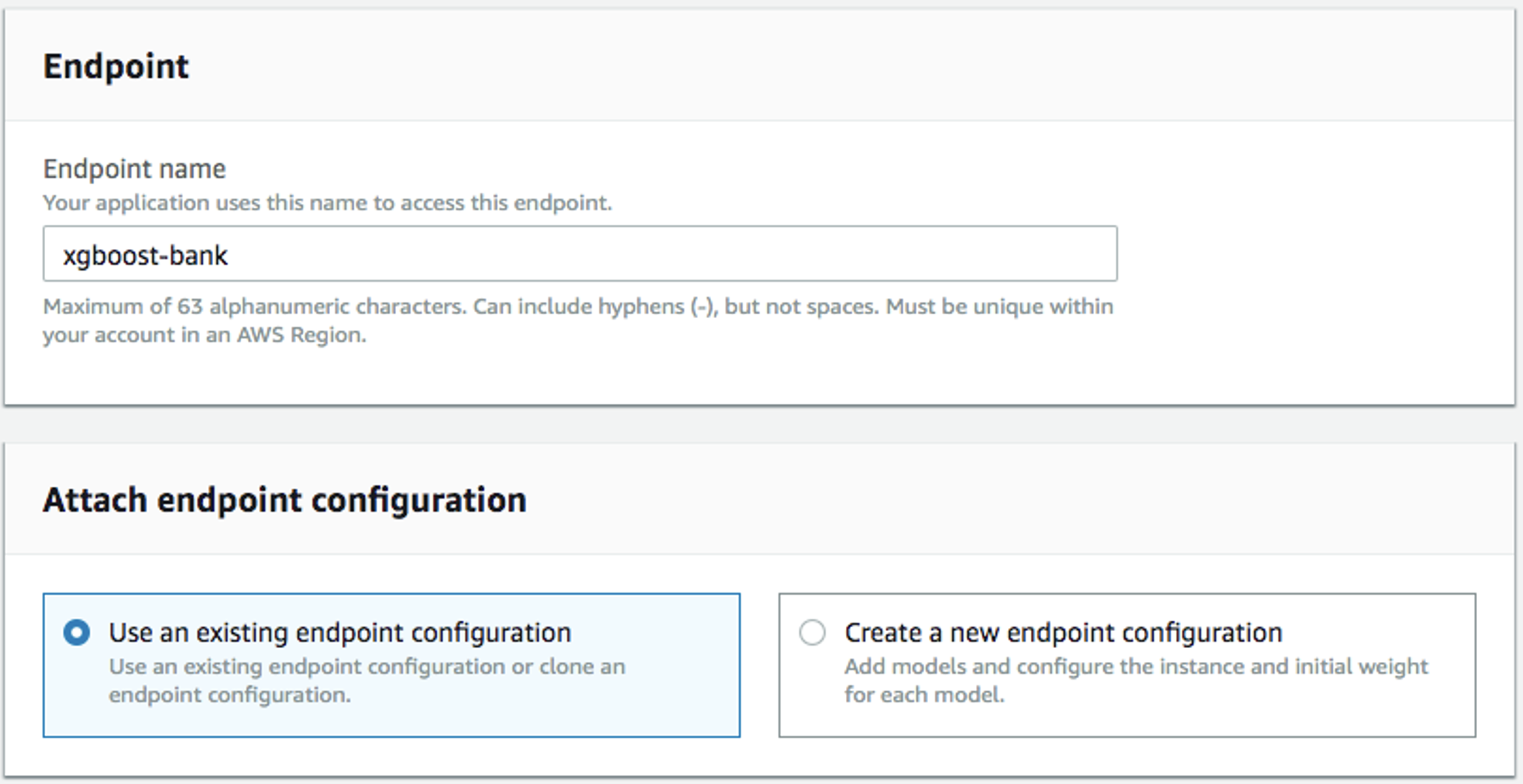
-
Seleccione la configuración del punto final creada en el último paso y haga clic en
Select endpoint configuration:
-
Deje los valores predeterminados para todo lo demás y haga clic en
Create endpoint.
Ahora el modelo se implementa en el punto final y las aplicaciones cliente pueden utilizarlo.
Resumen
Este tutorial demostró cómo extraer datos de entrenamiento de Vantage y usarlos para entrenar un modelo en Amazon SageMaker. La solución utilizó un cuaderno Jupyter para extraer datos de Vantage y escribirlos en un depósito de S3. Un trabajo de entrenamiento de SageMaker leyó datos del depósito de S3 y creó un modelo. El modelo se implementó en AWS como punto final de servicio.
Lectura adicional
- Guía de integración de API para AWS SageMaker
- Integrar las extensiones de Teradata Jupyter con una instancia de cuaderno de SageMaker
Si tiene alguna pregunta o necesita más ayuda, visite nuestro foro de la comunidad donde podrá obtener ayuda e interactuar con otros miembros de la comunidad.