Utilizar Teradata Vantage con Azure Machine Learning Studio
Información general
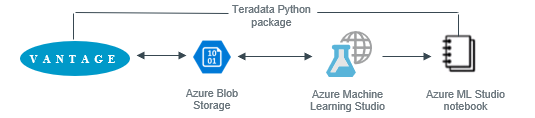
Azure Machine Learning (ML) Studio es una herramienta colaborativa de tipo arrastrar y soltar que puede usar para crear, probar e implementar soluciones de analíticas predictivas en sus datos. ML Studio puede consumir datos de Azure Blob Storage. Esta guía de introducción le mostrará cómo copiar conjuntos de datos de Teradata Vantage a un Blob Storage utilizando la función Jupter Notebook "integrada" de ML Studio. Luego, ML Studio puede utilizar los datos para crear y entrenar modelos de aprendizaje automático e implementarlos en un entorno de producción.
Prerrequisitos
- Acceso a una instancia de Teradata Vantage.
Nota
Si necesita una instancia de prueba de Vantage, puede obtener una de forma gratuita en https://clearscape.teradata.com
- Suscripción a Azure o crear una cuenta gratuita
- Espacio de trabajo de Azure ML Studio
- (Opcional) Descargar una base de datos de AdventureWorks DW 2016 (es decir, la sección 'Entrenar el modelo')
- Restaurar y copiar la tabla 'vTargetMail' de SQL Server a Teradata Vantage
Procedimiento
Configuración inicial
-
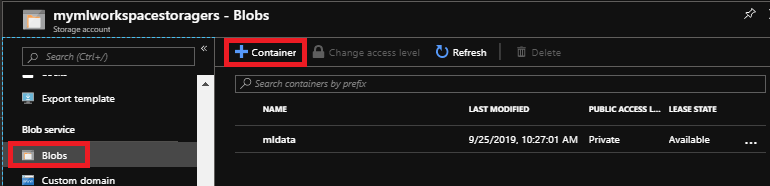
Durante la creación del espacio de trabajo de ML Studio, es posible que deba crear una "nueva" cuenta de almacenamiento a menos que tenga una en las ubicaciones de disponibilidad actual y elija DEVTEST Standard para Plan de servicios web para esta guía de introducción. Inicie sesión en Azure Portal, abra su cuenta de almacenamiento y cree un contenedor si aún no existe una.
-
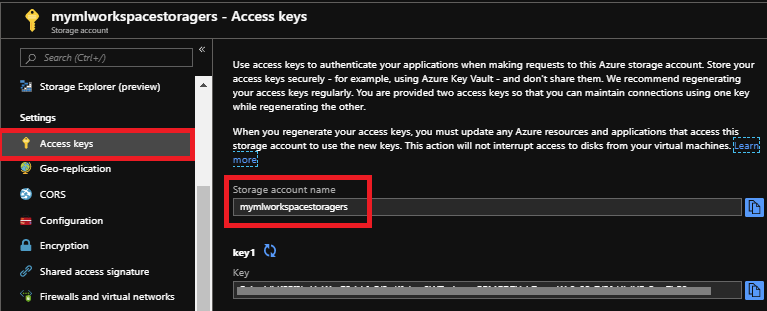
Copie su nombre de la cuenta de almacenamiento y Key en el bloc de notas que usaremos para que Python3 Notebook acceda a su cuenta de Azure Blob Storage.
-
Finalmente, abra la propiedad Configuration y establezca 'Se requiere transferencia segura' en Deshabilitado para permitir que el módulo de importación de datos de ML Studio acceda a la cuenta de Blob Storage.

Cargar datos
Para llevar los datos a ML Studio, primero debemos cargar los datos de Teradata Vantage en Azure Blob Storage. Crearemos un ML Jupyter Notebook, instalaremos paquetes de Python para conectarnos a Teradata y guardaremos datos en Azure Blob Storage.
Inicie sesión en Azure Portal, vaya a espacio de trabajo de ML Studio y Azure Machine Learning Studio y inicie sesión.
-
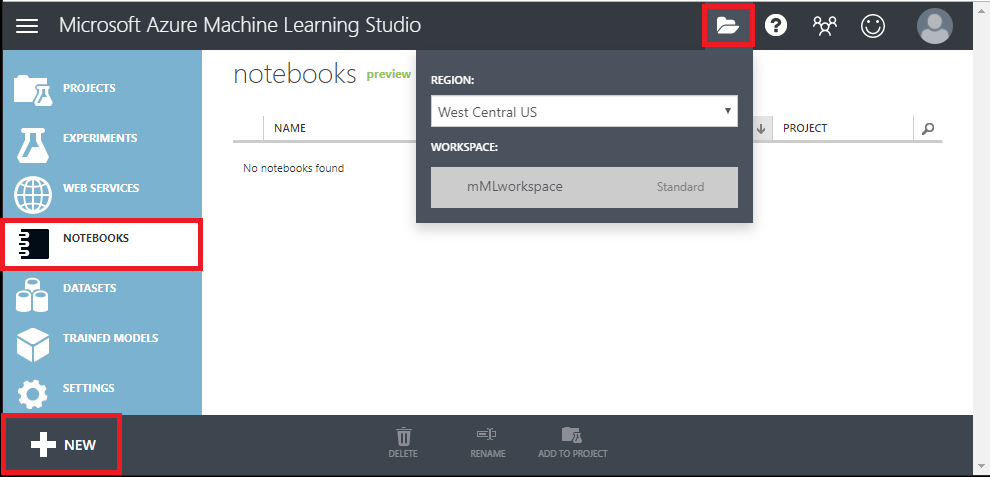
Debería ver la siguiente pantalla y hacer clic en Cuadernos, asegúrese de estar en la región/espacio de trabajo correcto y haga clic en Notebook Nuevo
-
Elija Python3 y Nombre a su instancia de cuaderno
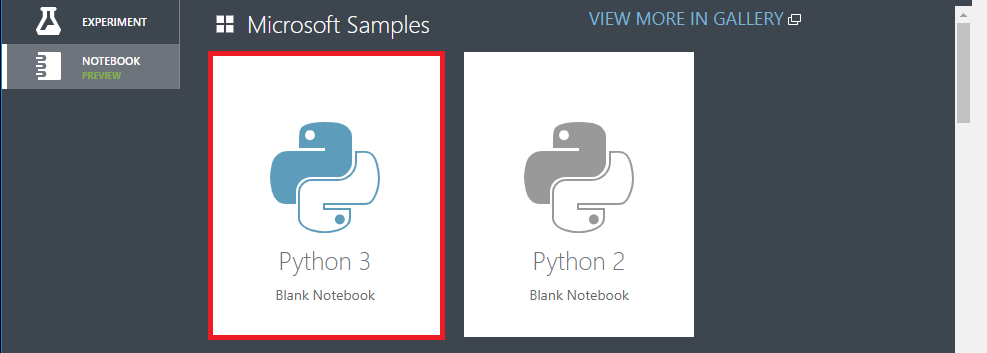
-
En su instancia de Jupyter Notebook, instale Paquete Python de Teradata Vantage para analíticas avanzadas:
NotaNo existe validación entre Microsoft Azure ML Studio y el paquete Teradata Vantage Python.
-
Instalar Microsoft Azure Storage Blob Client Library for Python:
-
Importe las siguientes bibliotecas:
-
Conéctese a Teradata usando el comando:
-
Recupere los datos utilizando el módulo Teradata Python DataFrame:
-
Convierta Teradata DataFrame a Panda DataFrame:
-
Convierta los datos a CSV:
-
Asigne variables para el nombre de la cuenta, la clave y el nombre del contenedor de Azure Blob Storage:
-
Cargue el archivo en Azure Blob Storage:
-
Inicie sesión en Azure Portal, abra la cuenta de Blob Storage para ver el archivo cargado:

Entrenar el modelo
Usaremos el artículo Analizar datos con Azure Machine Learning existente para crear un modelo de aprendizaje automático predictivo basado en datos de Azure Blob Storage. Crearemos una campaña de marketing dirigida para Adventure Works, la tienda de bicicletas, prediciendo si es probable que un cliente compre una bicicleta o no.
Importar datos
Los datos están en el archivo de Azure Blob Storage llamado vTargetMail.csv que copiamos en la sección anterior.
- Inicie sesión en Azure Machine Learning studio y haga clic en Experimentos.
- Haga clic en +NEW en la parte inferior izquierda de la pantalla y seleccione Experimento en blanco.
- Introduzca un nombre para su experimento: Marketing dirigido.
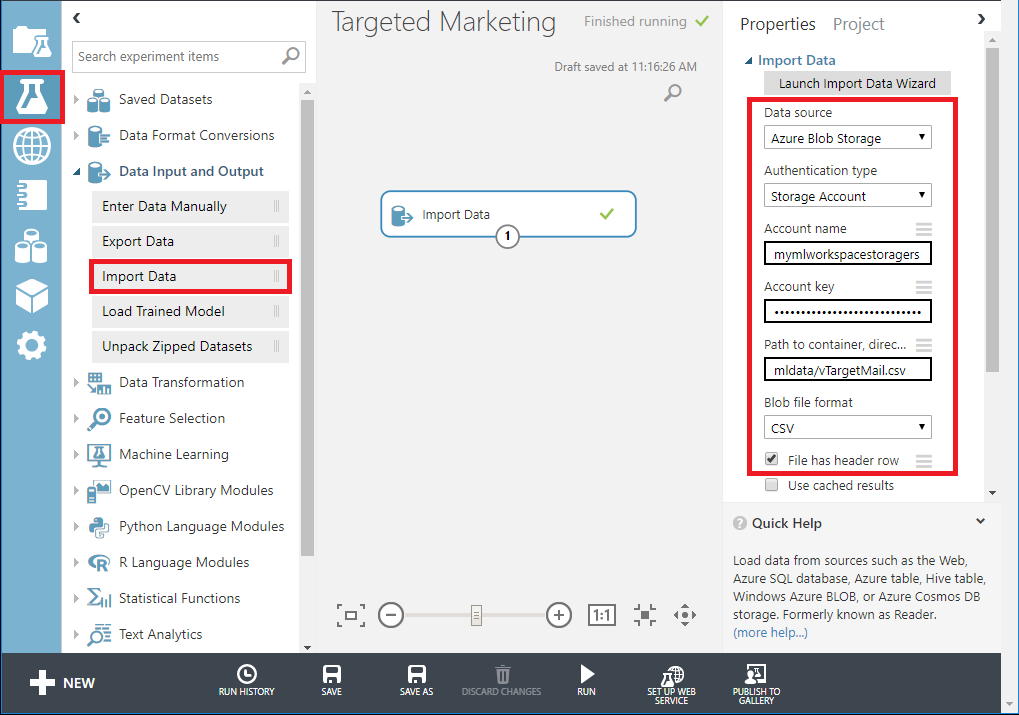
- Arrastre el módulo Importar datos debajo de Entrada y salida de datos desde el panel de módulos al lienzo.
- Especifique los detalles de su Azure Blob Storage (nombre de cuenta, clave y nombre de contenedor) en el panel Propiedades.
Ejecute el experimento haciendo clic en Ejecutar debajo del lienzo del experimento.
Una vez que el experimento termine de ejecutarse exitosamente, haga clic en el puerto de salida en la parte inferior del módulo Importar datos y seleccione Visualizar para ver los datos importados.
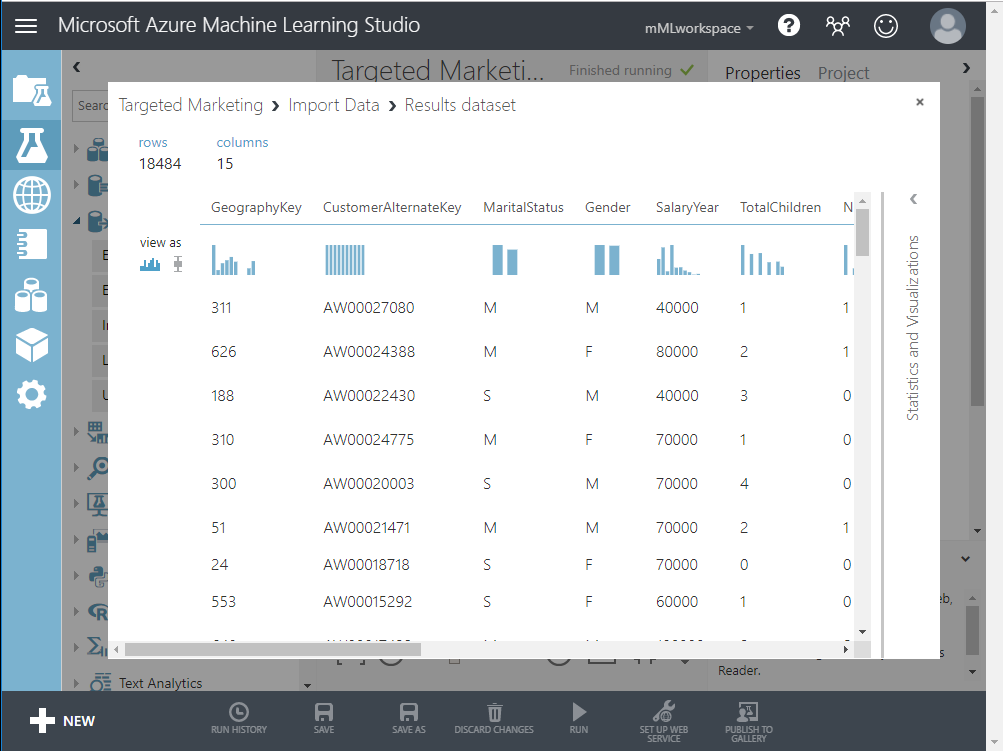
Limpiar los datos
Para limpiar los datos, elimine algunas columnas que no sean relevantes para el modelo. Para ello:
- Arrastre el módulo Seleccionar columnas en el conjunto de datos que se encuentra debajo de Transformación de datos < Manipulación al lienzo. Conecte este módulo al módulo Importar datos.
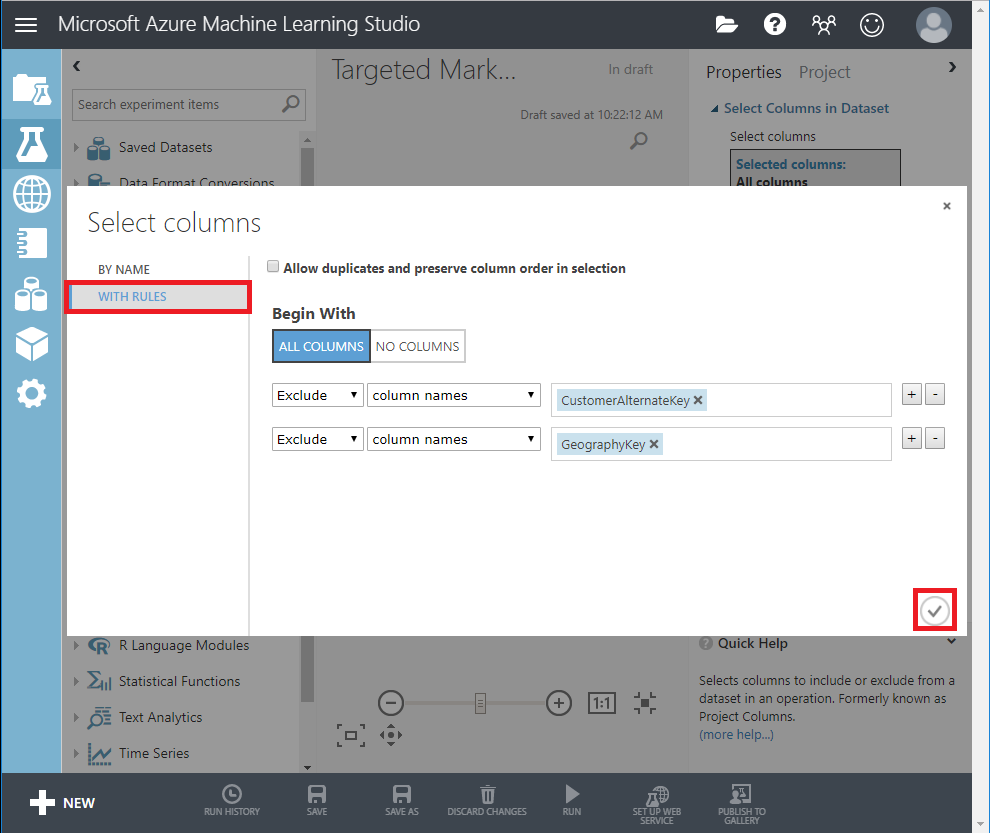
- Haga clic en Selector de columnas de inicio en el panel Propiedades para especificar qué columnas quiere eliminar.
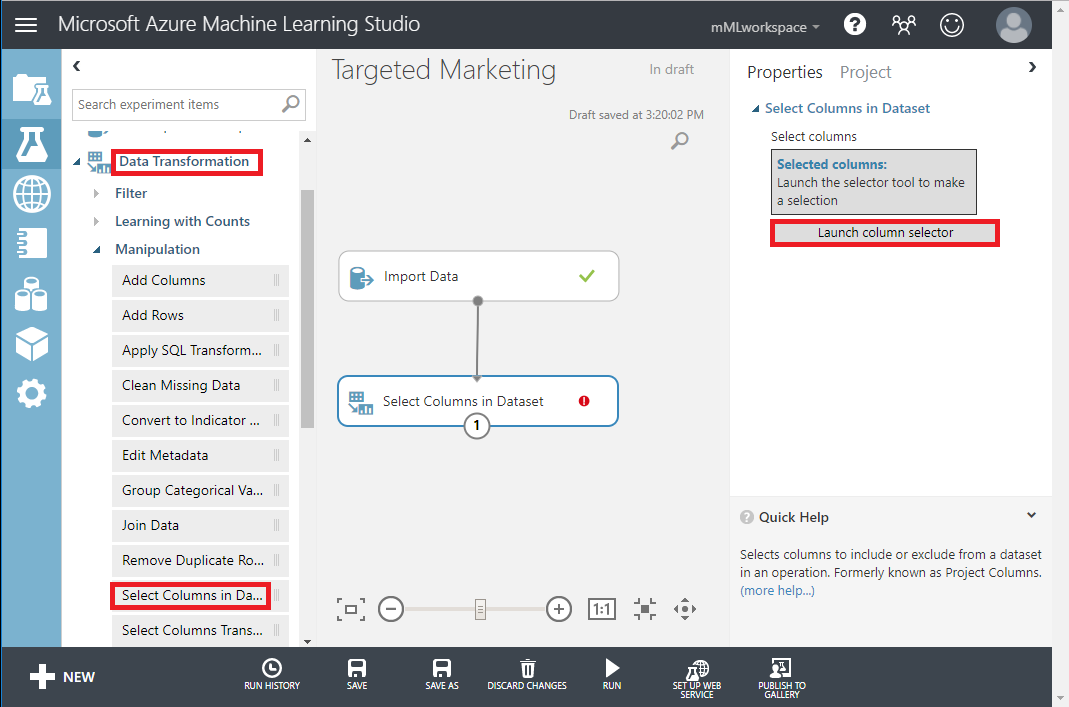
- Excluya dos columnas: CustomerAlternateKey y GeographyKey.
Construir el modelo
Dividiremos los datos 80-20: 80 % para entrenar un modelo de aprendizaje automático y 20 % para probar el modelo. Usaremos los algoritmos de "dos clases" para este problema de clasificación binaria.
-
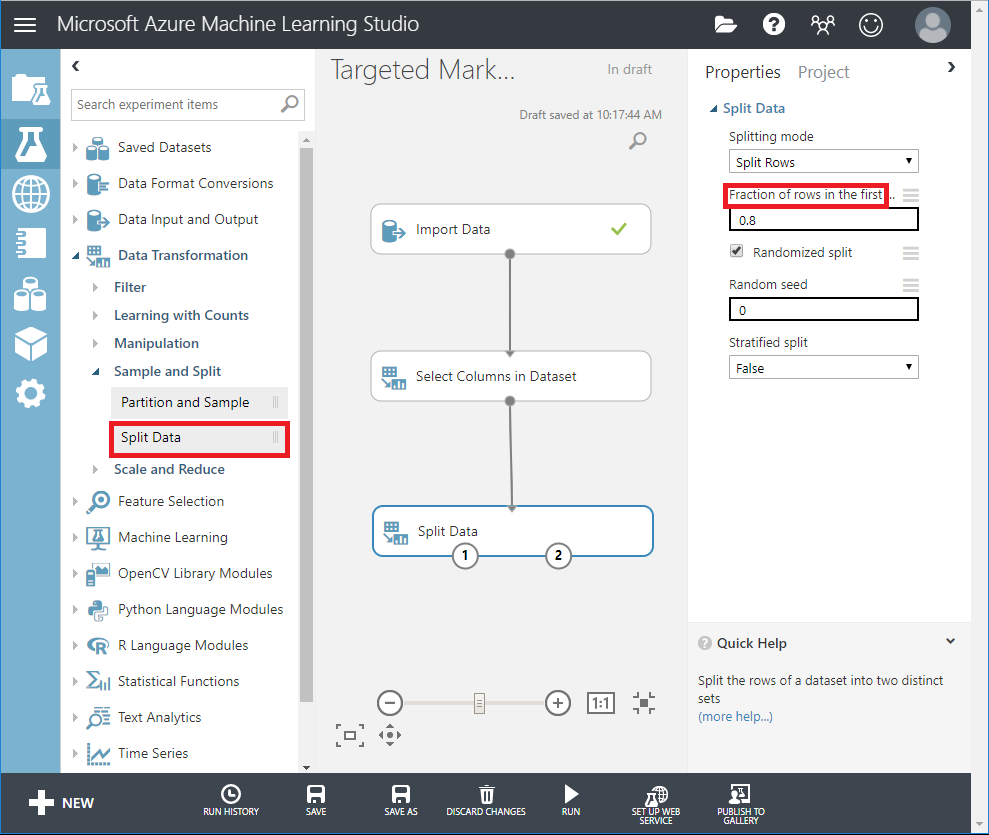
Arrastre el módulo Dividir datos hasta el lienzo y conéctelo con 'Seleccionar columnas en el conjunto de datos'.
-
En el panel de propiedades, introduzca 0,8 para Fracción de filas en el primer conjunto de datos de salida.
-
Busque y arrastre el módulo Árbol de decisión potenciado con dos clases hasta el lienzo.
-
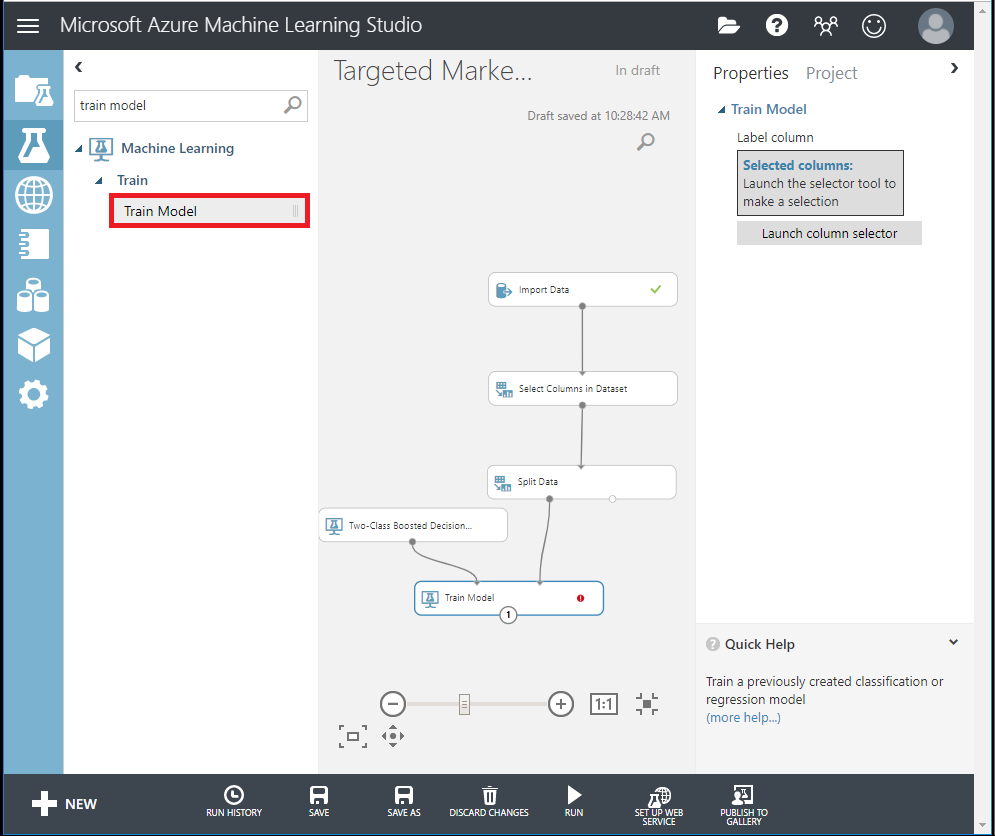
Busque y arrastre el módulo Entrenar modelo hasta el lienzo y especifique las entradas conectándolo a los módulos Árbol de decisión potenciado con dos clases (algoritmo ML) y Dividir datos (datos para entrenar el algoritmo).
-
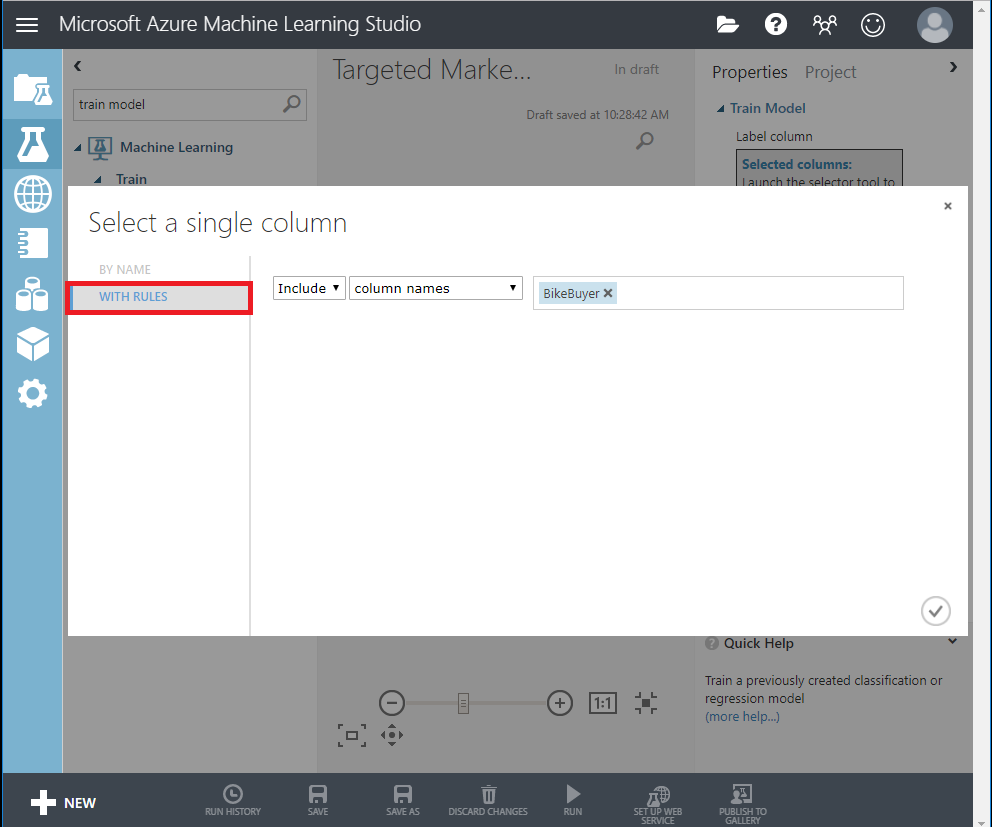
Posteriormente, haga clic en Selector de columnas de inicio en el panel Propiedades. Seleccione la columna BikeBuyer como columna para predecir.
Puntuar el modelo
Ahora, probaremos cómo se desempeña el modelo con los datos de prueba. Compararemos el algoritmo de nuestra elección con un algoritmo diferente para ver cuál funciona mejor.
- Arrastre el módulo Puntuar modelo hasta el lienzo y conéctelo a los módulos Entrenar modelo y Dividir datos.
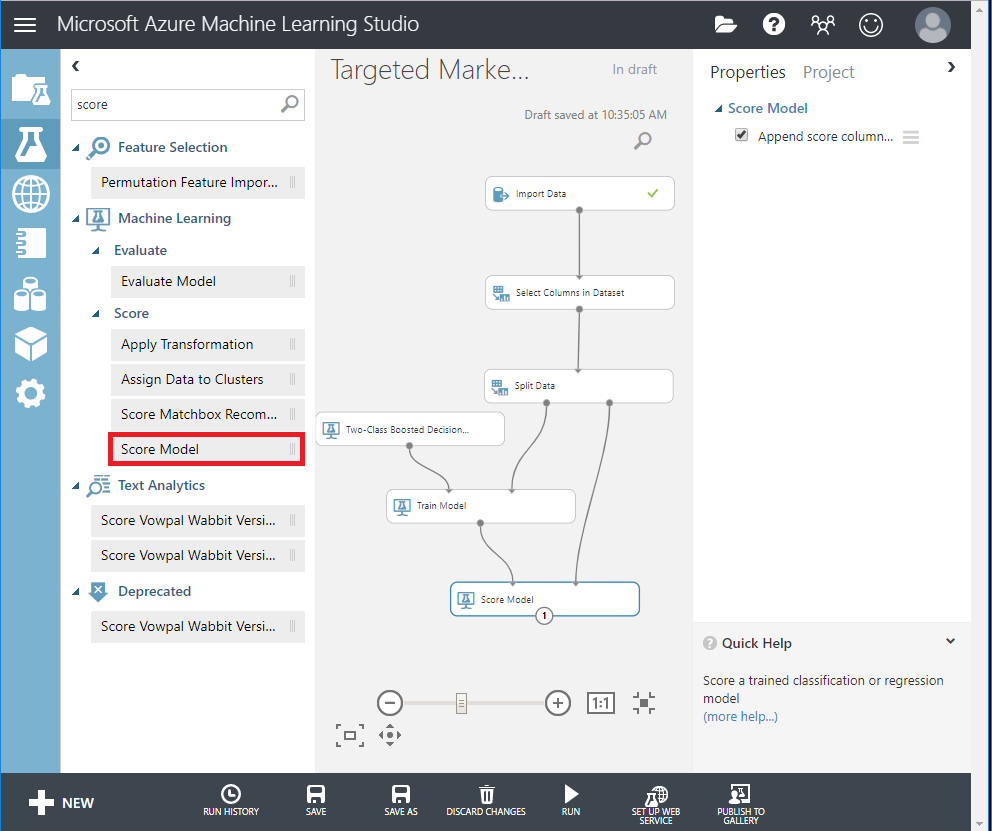
- Busque y arrastre Máquina de punto Bayes de dos clases hasta el lienzo del experimento. Compararemos el rendimiento de este algoritmo en comparación con el árbol de decisión potenciado de dos clases.
- Copie y pegue los módulos Train Model y Score Model en el lienzo.
- Busque y arrastre el módulo Evaluar modelo hasta el lienzo para comparar los dos algoritmos.
- Ejecutar el experimento.
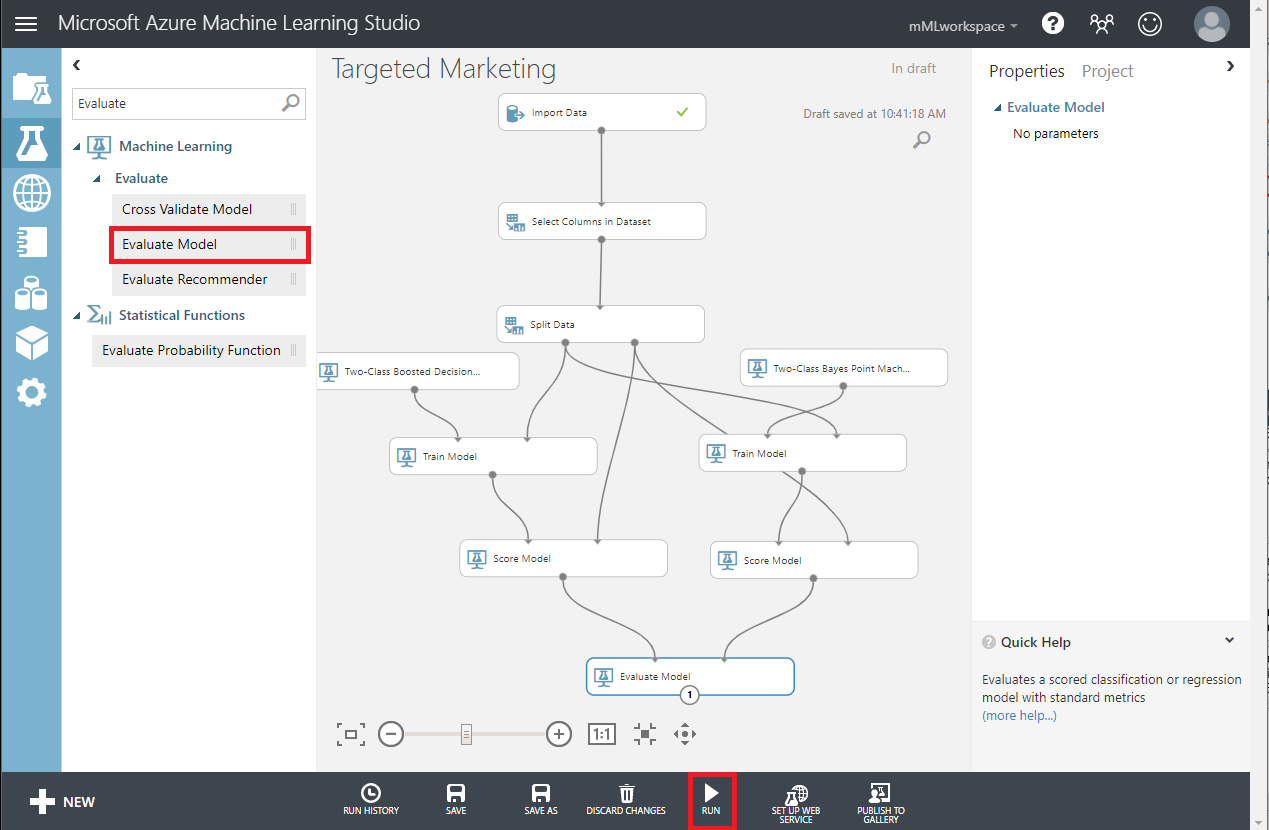
- Haga clic en el puerto de salida en la parte inferior del módulo Evaluate Model y haga clic en Visualizar.
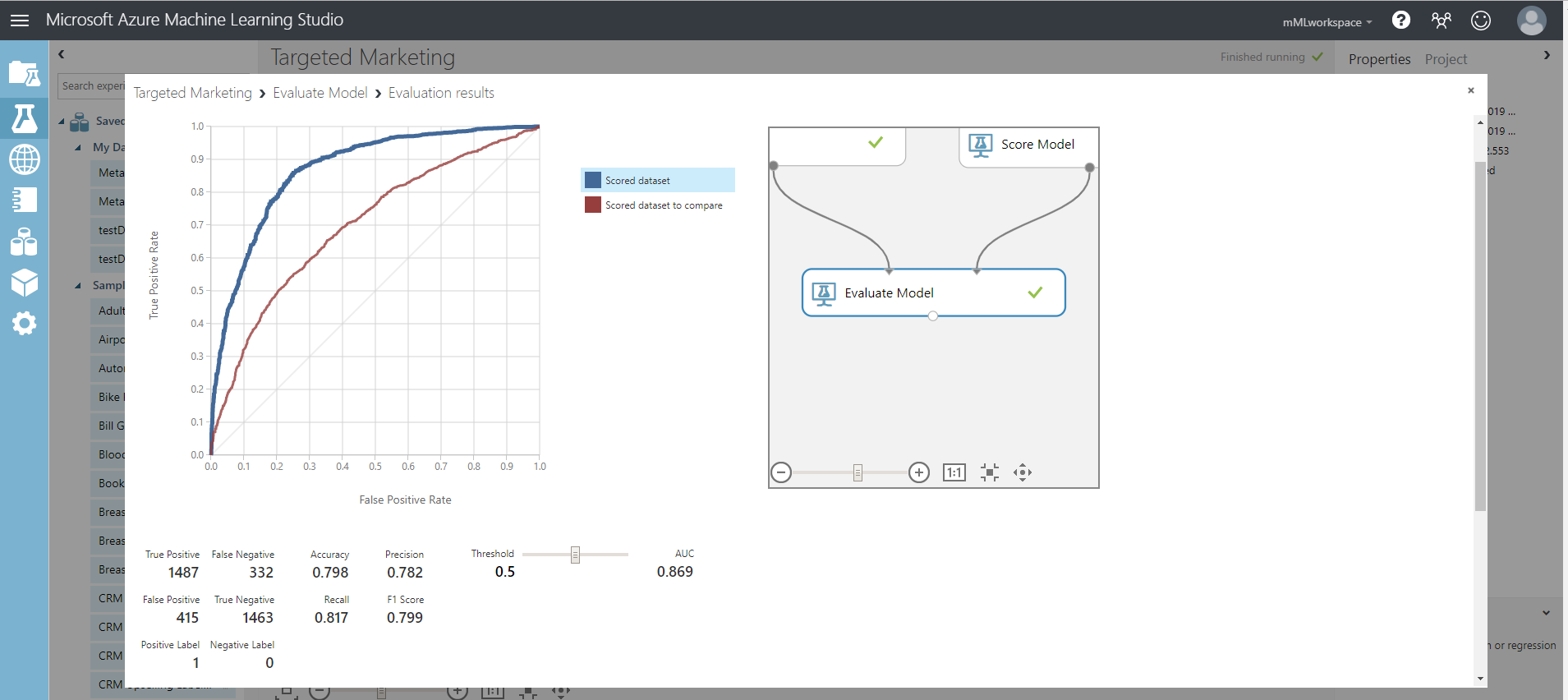
Las métricas proporcionadas son la curva ROC, el diagrama de recuperación de precisión y la curva de elevación. Al observar estas métricas, podemos ver que el primer modelo funcionó mejor que el segundo. Para ver lo que predijo el primer modelo, haga clic en el puerto de salida del Score Model y haga clic en Visualizar.
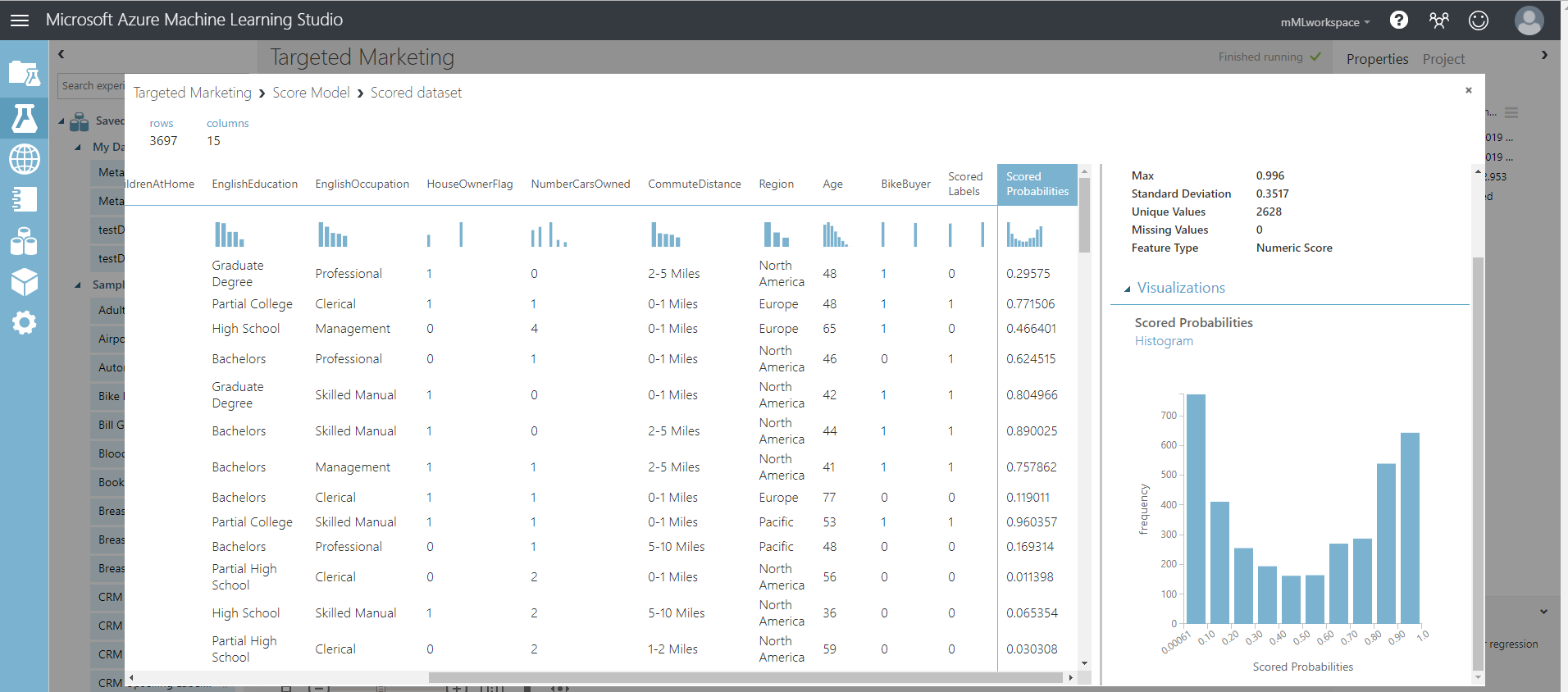
Verá dos columnas más agregadas a su conjunto de datos de prueba.
- Score Probabilities: la probabilidad de que un cliente sea un comprador de bicicletas.
- Scored Labels: la clasificación realizada por el modelo - comprador de bicicleta (1) o no (0). Este umbral de probabilidad de etiquetado se establece en 50 % y se puede ajustar.
Comparando la columna BikeBuyer (real) con Scored Labels (predicción), puede ver lo bien que se ha desempeñado el modelo. Como siguientes pasos, puede utilizar este modelo para hacer predicciones para nuevos clientes y publicar este modelo como un servicio web o escribir los resultados en SQL Data Warehouse.
Lectura adicional
- Para obtener más información sobre la creación de modelos predictivos de aprendizaje automático, consulte Introducción al aprendizaje automático en Azure.
- Para copias de conjuntos de datos grandes, considere la posibilidad de usar el Módulo de acceso de Teradata para Azure que interactúa entre los operadores de carga/descarga de Teradata Parallel Transporter y Azure Blob Storage.
Si tiene alguna pregunta o necesita más ayuda, visite nuestro foro de la comunidad donde podrá obtener ayuda e interactuar con otros miembros de la comunidad.