Arquitectura y conceptos del motor de Teradata Vantage
Información general
Este artículo explica los conceptos subyacentes de la arquitectura del motor de Teradata Vantage. Todas las ediciones de Vantage, incluido el clúster primario en VantageCloud Lake, utilizan el mismo motor.
La arquitectura de Teradata está diseñada en torno a una arquitectura de procesamiento masivo paralelo (Massively Parallel Processing, MPP) sin compartir, que permite el procesamiento y análisis de datos de alto rendimiento. La arquitectura MPP distribuye la carga de trabajo en múltiples vprocs o procesadores virtuales. El procesador virtual donde se realiza el procesamiento de consultas se denomina comúnmente procesador de módulo de acceso (Access Module Processor, AMP). Cada AMP está aislado de otros AMP y procesa las consultas en paralelo, lo que permite a Teradata procesar grandes volúmenes de datos rápidamente.
Los principales componentes arquitectónicos del motor de Teradata Vantage incluyen motores de análisis (Parsing Engines, PE), BYNET, procesadores de módulo de acceso (AMP) y discos virtuales (Vdisks). Los discos virtuales se asignan a AMP en plataformas empresariales y al clúster primario en el caso de entornos VantageCloud Lake.
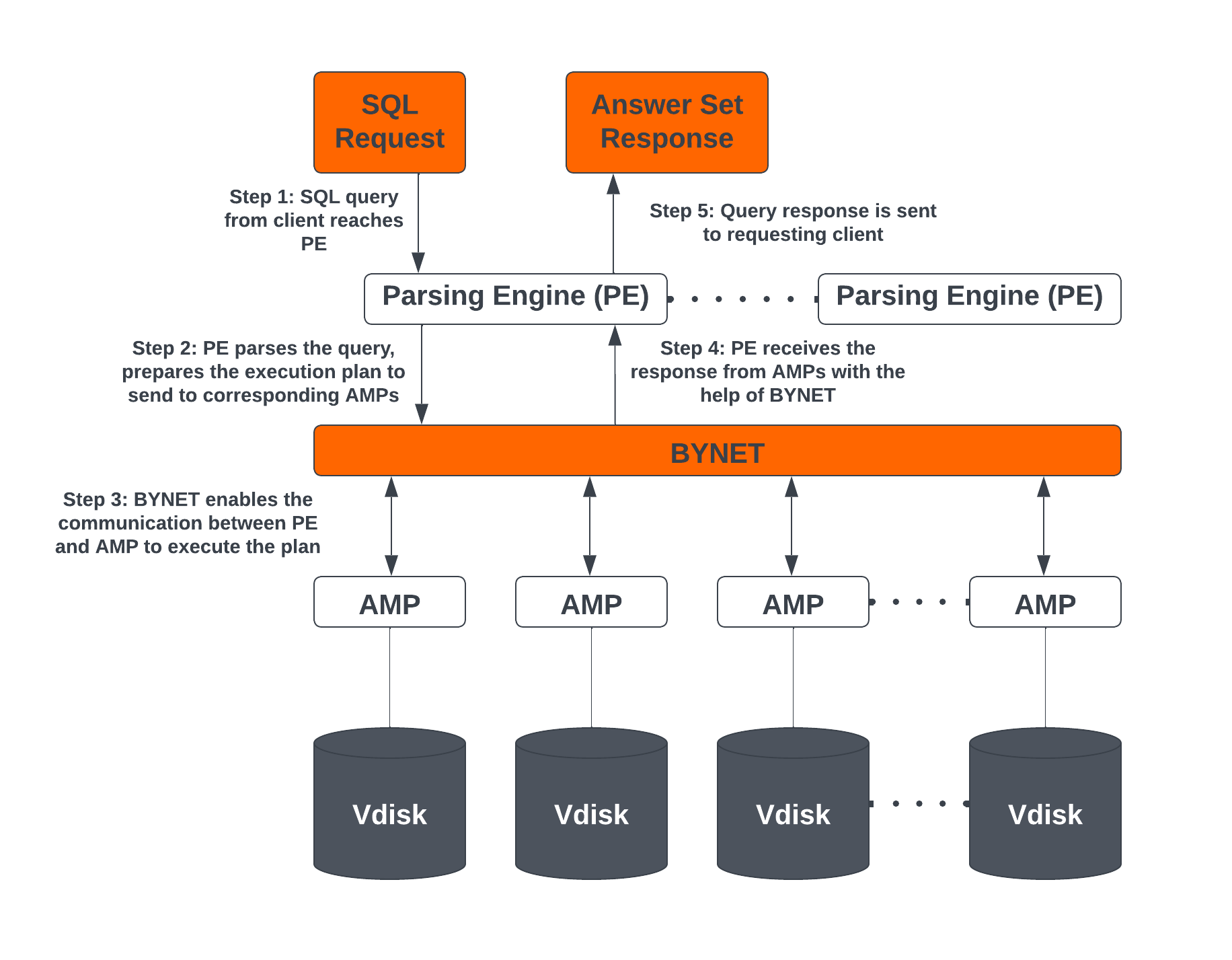
Componentes de la arquitectura del motor de Teradata Vantage
El motor de Teradata Vantage consta de los siguientes componentes:
Parsing Engines (PE)
Cuando se ejecuta una consulta SQL en Teradata, primero llega al motor de análisis. Las funciones del motor de análisis son:
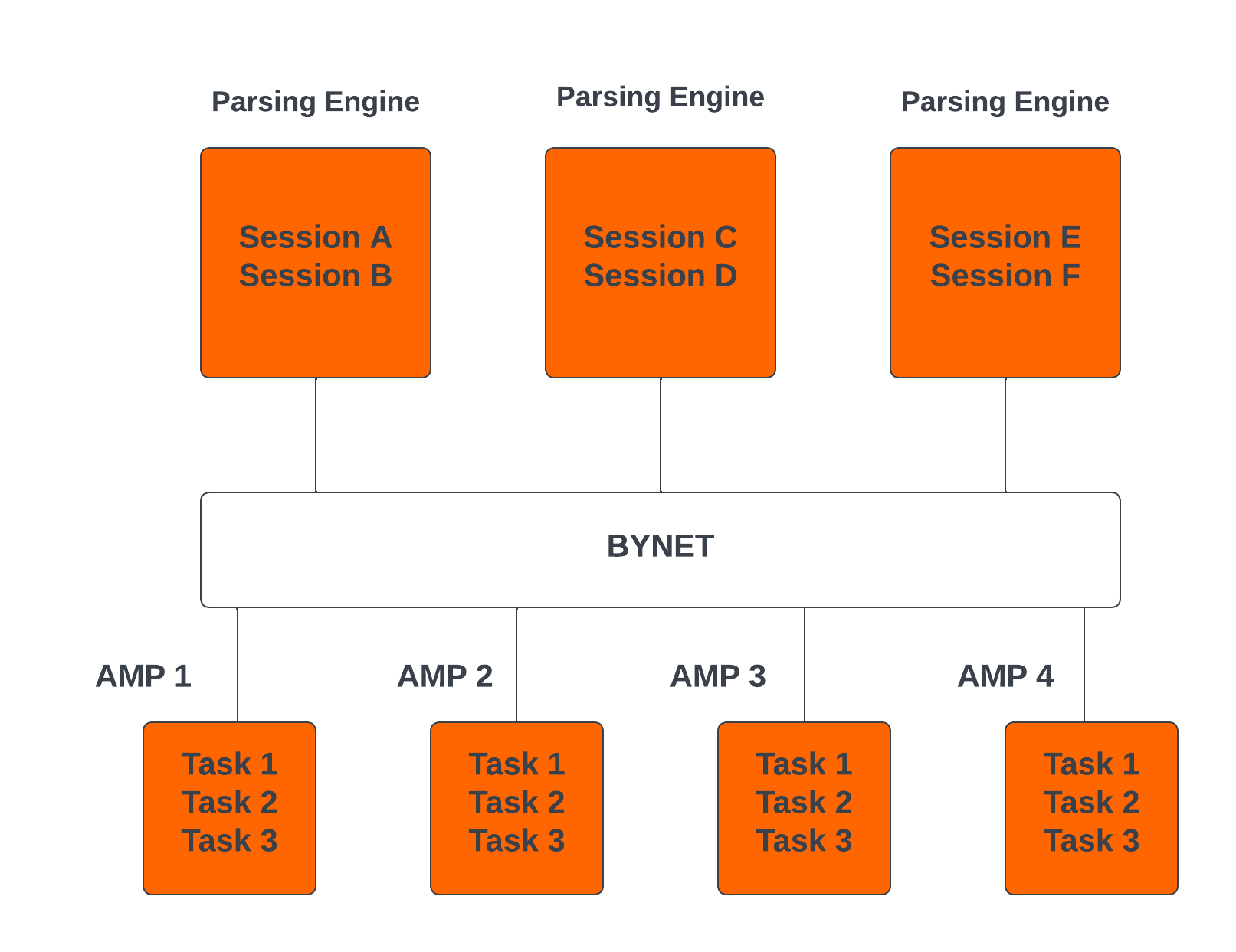
- Administrar sesiones de usuarios individuales (hasta 120).
- Comprobar si existen los objetos utilizados en la consulta SQL.
- Comprobar si el usuario tiene los privilegios necesarios sobre los objetos utilizados en la consulta SQL.
- Analizar y optimizar las consultas SQL.
- Preparar el plan de ejecución para ejecutar la consulta SQL y pasarla a los AMP correspondientes.
- Recibir la respuesta de los AMP y enviarla al cliente solicitante.
BYNET
BYNET es un sistema que permite la comunicación de componentes. El sistema BYNET proporciona funciones de fusión y transmisión bidireccional de alta velocidad, multidifusión y comunicación punto a punto. Realiza tres funciones clave: coordinar consultas de múltiples AMP, leer datos de múltiples AMP, regulando el flujo de mensajes para evitar la congestión, y procesar el rendimiento de la plataforma. Estas funciones de BYNET hacen que Vantage sea altamente escalable y permiten capacidades de procesamiento masivo paralelo (MPP).
Parallel Database Extension (PDE)
Parallel Database Extension (PDE) es una capa de software intermediaria ubicada entre el sistema operativo y la base de datos Teradata Vantage. PDE permite que los sistemas MPP utilicen funciones como BYNET y discos compartidos. Facilita el paralelismo responsable de la velocidad y la escalabilidad lineal de la base de datos Teradata Vantage.
Access Module Processor (AMP)
Los AMP son responsables del almacenamiento y la recuperación de los datos. Cada AMP está asociado con su propio conjunto de discos virtuales (Vdisks) donde se almacenan los datos, y ningún otro AMP puede acceder a ese contenido de acuerdo con la arquitectura de nada compartido. Las funciones de AMP son:
- Acceder al almacenamiento utilizando el software Block File System de Vantage
- Gestionar los bloqueos
- Ordenar filas
- Agregar columnas
- Procesar uniones
- Convertir salidas
- Gestionar el espacio en disco
- Contabilidad
- Procesar la recuperación
Los AMP en VantageCore IntelliFlex, VantageCore VMware, VantageCloud Enterprise y el clúster primario en el caso de VantageCloud Lake almacenan datos en un formato de sistema de archivos de bloque (BFS) en discos virtuales. Los AMP en Compute Clusters y Compute Worker Nodes en VantageCloud Lake no tienen BFS, solo pueden acceder a los datos en el almacenamiento de objetos utilizando el Object File System (OFS).
Virtual Disks (Vdisks)
Estas son unidades de espacio de almacenamiento propiedad de un AMP. Los discos virtuales se utilizan para almacenar datos de usuario (filas dentro de tablas). Los discos virtuales se asignan al espacio físico de un disco.
Nodo
Un nodo, en el contexto de los sistemas Teradata, representa un servidor individual que funciona como plataforma de hardware para el software de base de datos. Sirve como una unidad de procesamiento donde las operaciones de la base de datos se ejecutan bajo el control de un único sistema operativo. Cuando Teradata se implementa en una nube, sigue la misma arquitectura MPP, sin compartir, pero los nodos físicos se reemplazan con máquinas virtuales (Virtual Machine, VM).
Conceptos de la arquitectura de Teradata Vantage
Los conceptos siguientes son aplicables a Teradata Vantage.
Crecimiento lineal y capacidad de expansión
Teradata es un RDBMS linealmente expandible. A medida que aumentan la carga de trabajo y el volumen de datos, agregar más recursos de hardware, como servidores o nodos, da como resultado un aumento proporcional en el rendimiento y la capacidad. La escalabilidad lineal permite una mayor carga de trabajo sin disminuir el rendimiento.
Paralelismo de Teradata
El paralelismo de Teradata se refiere a la capacidad inherente de Teradata Database para realizar procesamiento paralelo de datos y consultas en múltiples nodos o componentes simultáneamente.
- Cada motor de análisis (PE) en Teradata tiene la capacidad de manejar hasta 120 sesiones simultáneamente.
- BYNET en Teradata permite el manejo paralelo de toda la actividad de mensajes, incluida la redistribución de datos para tareas posteriores.
- Todos los procesadores de módulos de acceso (AMP) de Teradata pueden colaborar en paralelo para atender cualquier solicitud entrante.
- Cada AMP puede funcionar en múltiples solicitudes al mismo tiempo, lo que permite un procesamiento paralelo eficiente.
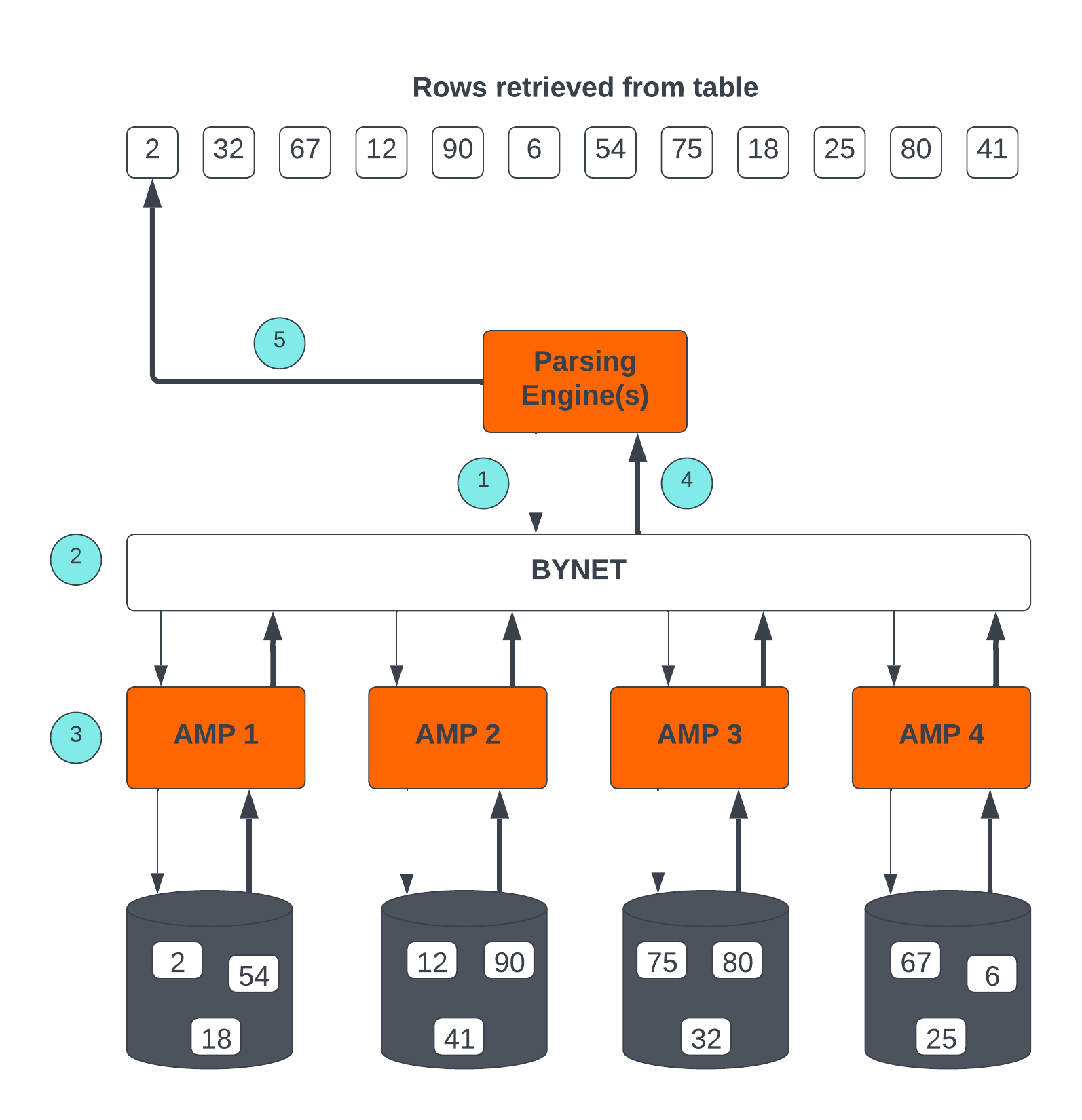
Arquitectura de recuperación de Teradata
Los pasos clave involucrados en la Arquitectura de recuperación de Teradata son:
- El motor de análisis envía una solicitud para recuperar una o más filas.
- BYNET activa los AMP relevantes para su procesamiento.
- Los AMP localizan y recuperan simultáneamente las filas deseadas a través del acceso paralelo.
- BYNET devuelve las filas recuperadas al motor de análisis.
- Luego, el motor de análisis devuelve las filas a la aplicación cliente solicitante.
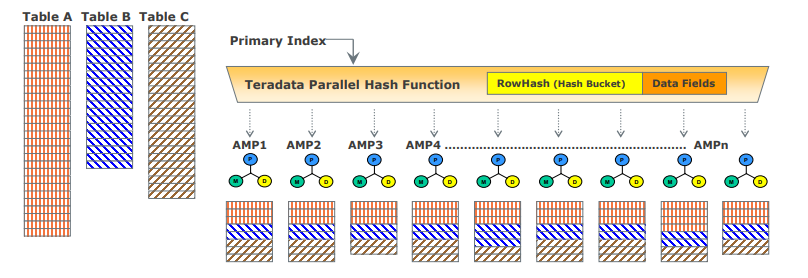
Distribución de datos de Teradata
La arquitectura MPP de Teradata requiere un medio eficiente para distribuir y recuperar datos y lo hace mediante particiones hash. La mayoría de las tablas en Vantage usan hash para distribuir datos para las tablas según el valor del índice primario (PI) de la fila al almacenamiento en disco en el sistema de archivos en bloque (BFS) y pueden escanear toda la tabla o usar índices para acceder a los datos. Este enfoque garantiza un rendimiento escalable y un acceso eficiente a los datos.
- Si el índice primario es único, las filas de las tablas se distribuyen automáticamente de manera uniforme mediante particiones hash.
- Las columnas del índice primario designadas tienen un hash para generar códigos hash coherentes para los mismos valores.
- No se requiere reorganización, repartición ni gestión del espacio.
- Cada AMP normalmente contiene filas de todas las tablas, lo que garantiza un acceso y procesamiento de datos eficiente.
Conclusión
En este artículo, cubrimos los principales componentes arquitectónicos de Teradata Vantage, como los motores de análisis (PE), BYNET, los procesadores del módulo de acceso (AMP), el disco virtual (Vdisk) y otros componentes arquitectónicos como la extensión de base de datos paralela (PDE), Node y los conceptos esenciales de Teradata Vantage, como crecimiento lineal y capacidad de expansión, paralelismo, recuperación de datos y distribución de datos.