Incorporación y catalogación de datos desde Teradata Vantage a Amazon S3 con scripts de AWS Glue
Información general
En este inicio rápido se detalla el proceso de incorporación y catalogación de datos de Teradata Vantage a Amazon S3 con AWS Glue.
Para incorporar datos en Amazon S3 cuando la catalogación no es un requisito, tenga en cuenta las capacidades Write NOS de Teradata.
Prerrequisitos
- Acceso a una cuenta de Amazon AWS
- Acceso a una instancia de Teradata Vantage
Nota
Si necesita una instancia de prueba de Vantage, puede obtener una de forma gratuita en https://clearscape.teradata.com
- Una base de datos cliente para enviar consultas para cargar los datos de prueba
Carga de datos de prueba
- En su cliente de base de datos favorito, ejecute las siguientes consultas
Configuración de Amazon AWS
En esta sección cubriremos en detalle cada uno de los pasos a continuación:
- Creación de un depósito de Amazon S3 para incorporar datos
- Creación de una base de datos de catálogo de AWS Glue para almacenar metadatos
- Almacenar credenciales de Teradata Vantage en AWS Secrets Manager
- Creación de un rol de servicio de AWS Glue para asignarlo a trabajos de ETL
- Crear una conexión a una instancia de Teradata Vantage en AWS Glue
- Crear un trabajo de AWS Glue
- Redactar un script para la incorporación y catalogación automatizadas de datos de Teradata Vantage en Amazon S3
Creación de un depósito de Amazon S3 para incorporar datos
- En Amazon S3, seleccione
Create bucket.
- Asigne un nombre al depósito y anótelo.
- Deje todos los ajustes en sus valores predeterminados.
- Haga clic en
Create bucket.
Creación de una base de datos de catálogo de AWS Glue para almacenar metadatos
- En AWS Glue, seleccione Catálogo de datos, Bases de datos.
- Haga clic en
Add database.
- Defina un nombre para la base de datos y haga clic en
Create database.
Almacenar credenciales de Teradata Vantage en AWS Secrets Manager
- En AWS Secrets Manager, seleccione
Create new secret.
- El secreto debe ser
Other type of secretcon las siguientes claves y valores según su instancia de Teradata Vantage:- USER
- PASSWORD
En el caso de ClearScape Analytics Experience, el usuario siempre es "demo_user" y la contraseña es la que definió al crear su entorno de ClearScape Analytics Experience.
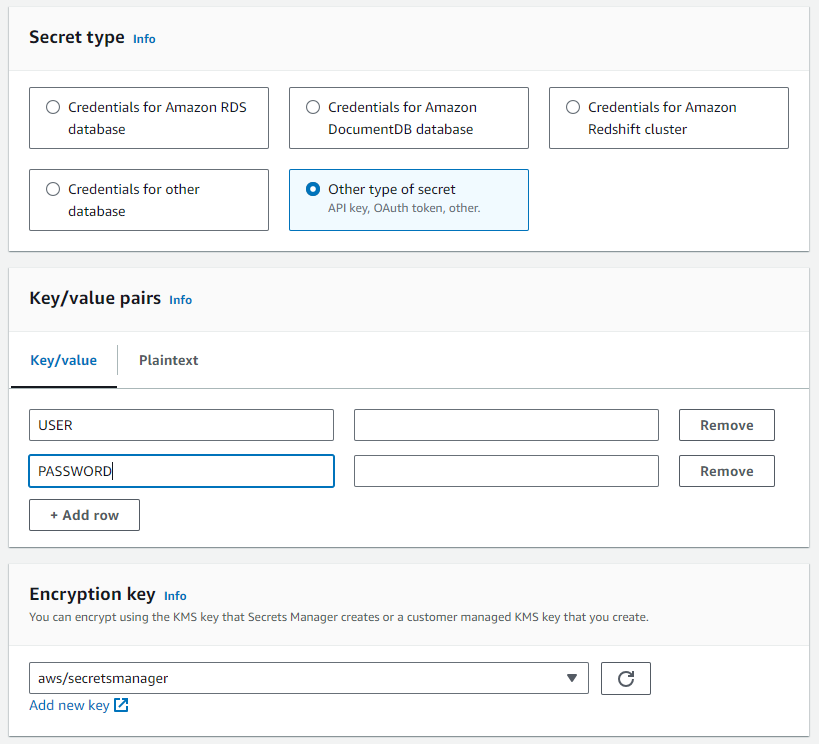
- Asigne un nombre al secreto.
- El resto de los pasos se pueden dejar con los valores predeterminados.
- Cree el secreto.
Creación de un rol de servicio de AWS Glue para asignarlo a trabajos de ETL
El rol que cree debe tener acceso a los permisos típicos de un rol de servicio de Glue, pero también acceso para leer el secreto y el depósito S3 que haya creado.
- En AWS, vaya al servicio IAM.
- En Gestión de acceso, seleccione
Roles. - En los roles, haga clic en
Create role.
- En la selección de una entidad de confianza, seleccione
AWS servicey elijaGlueen el menú desplegable.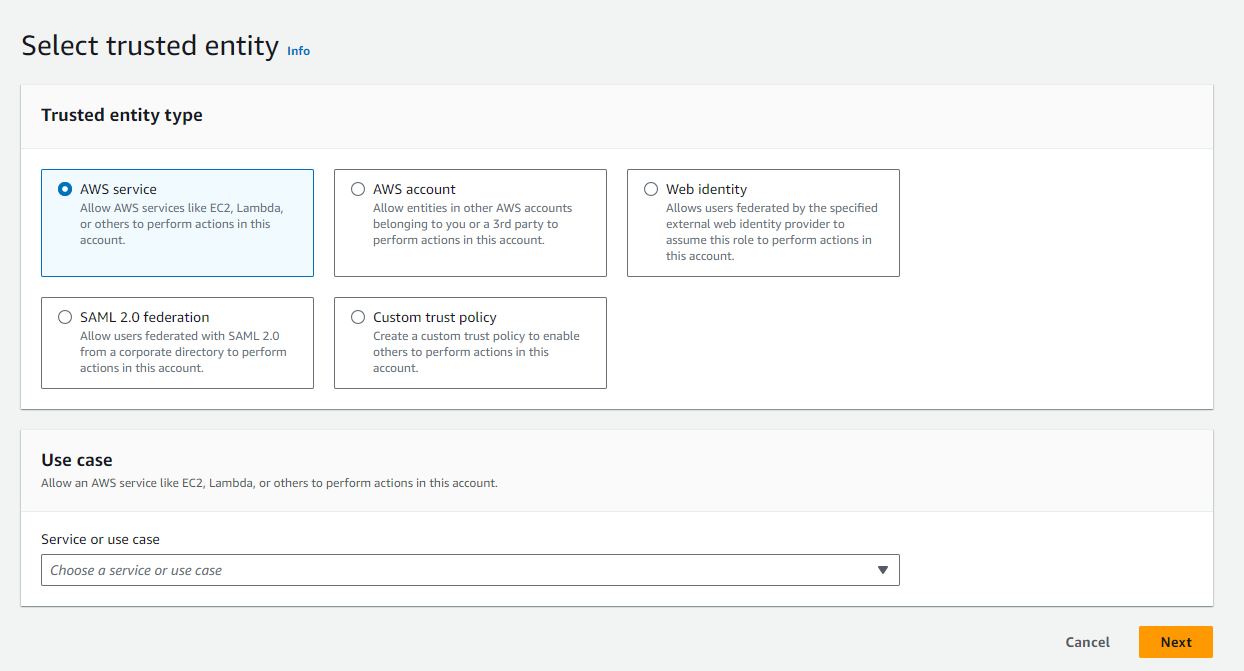
- En la adición de permisos:
- Busque
AWSGlueServiceRole. - Haga clic en la casilla de verificación correspondiente.
- Busque
SecretsManagerReadWrite. - Haga clic en la casilla de verificación correspondiente.
- Busque
- En la opción para asignar nombre, revisar y crear:
- Defina un nombre para el rol.
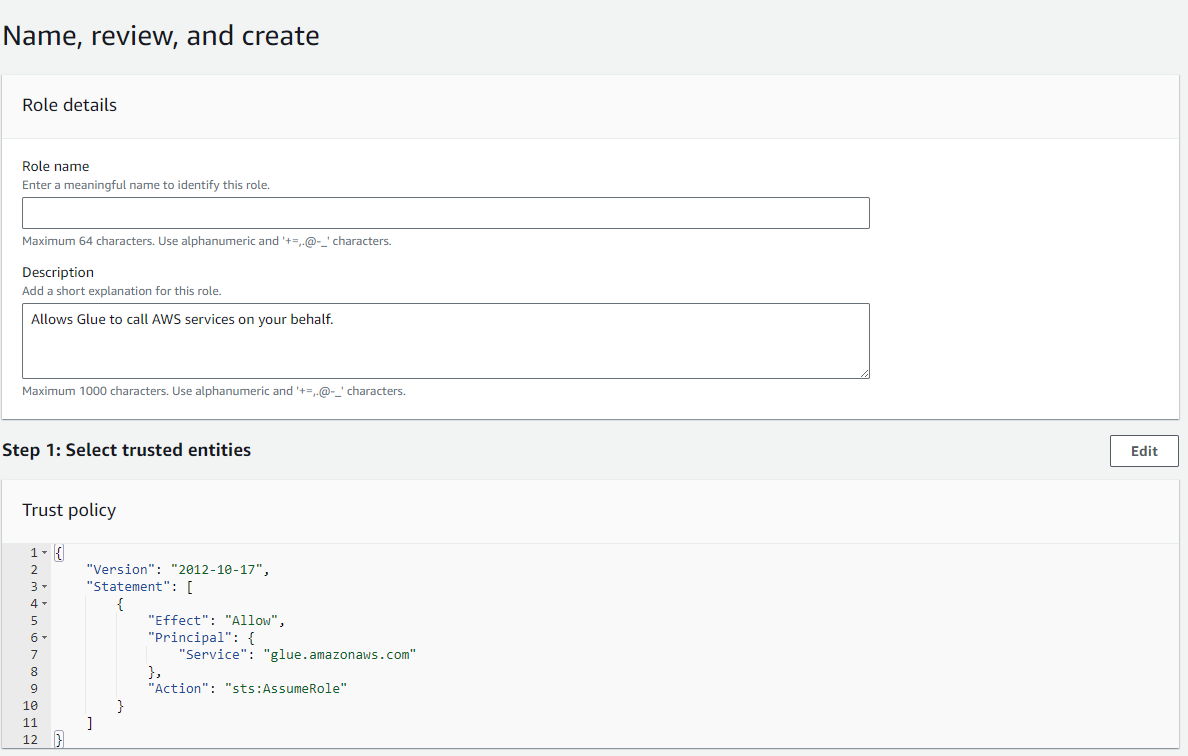
- Defina un nombre para el rol.
- Haga clic en
Create role. - Regrese a Administración de acceso, Roles y busque el rol que acaba de crear.
- Seleccione su rol.
- Haga clic en
Add permissionsy posteriormente enCreate inline policy. - Haga clic en
JSON. - En el editor de políticas, pegue el objeto JSON a continuación, sustituyendo el nombre del depósito que ha creado.
- Haga clic en
Next.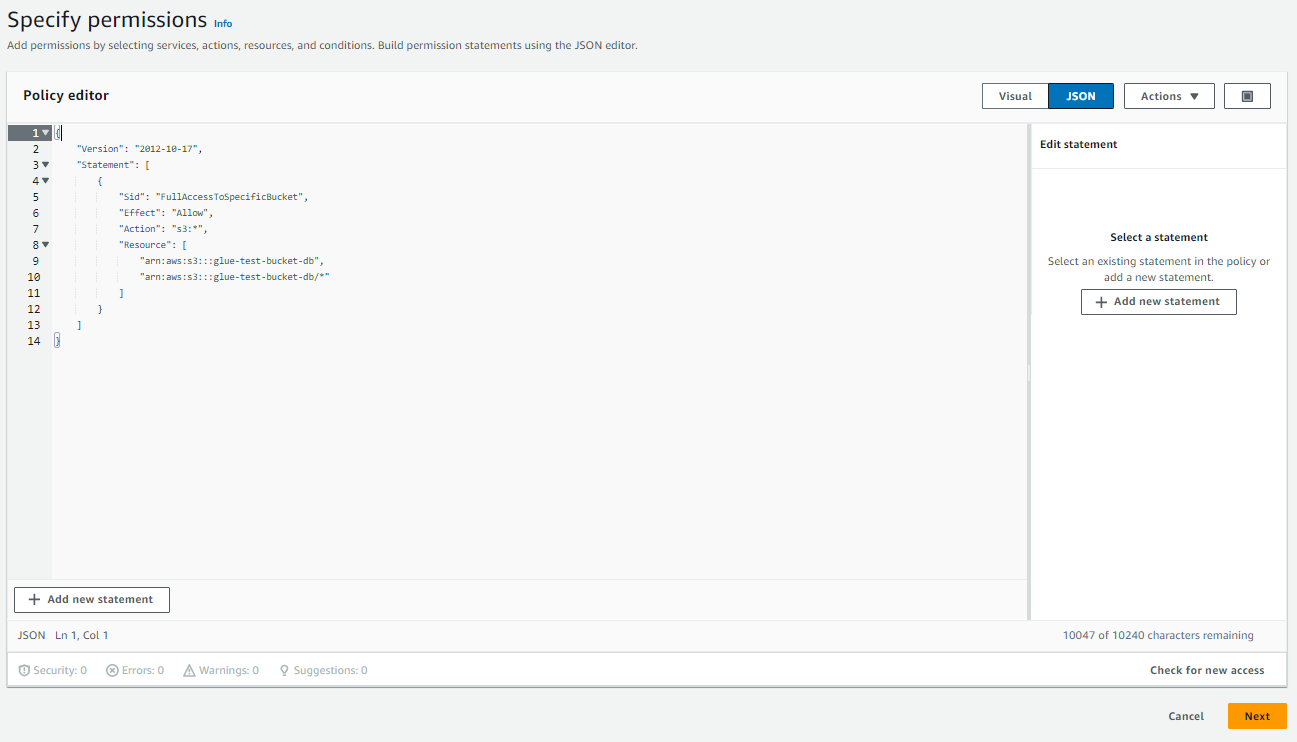
- Asigne un nombre a su política.
- Haga clic en
Create policy.
Crear una conexión a una instancia de Teradata Vantage en AWS Glue
- En AWS Glue, seleccione
Data connections.
- En Conectores, seleccione
Create connection. - Busque y seleccione la fuente de datos Teradata Vantage.
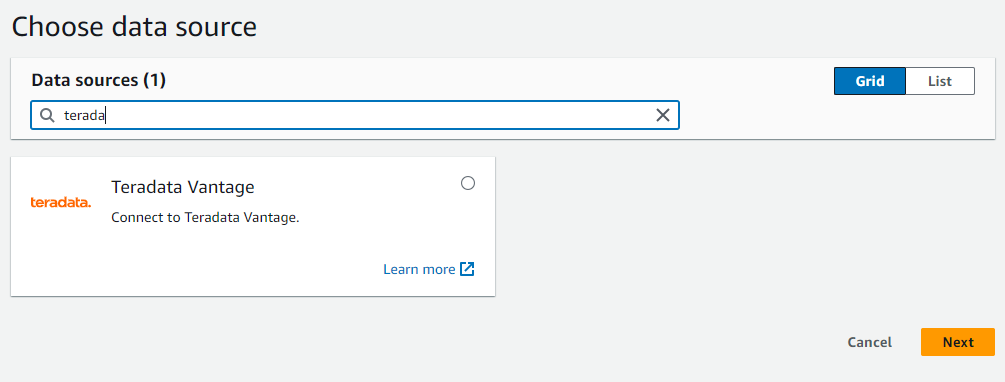
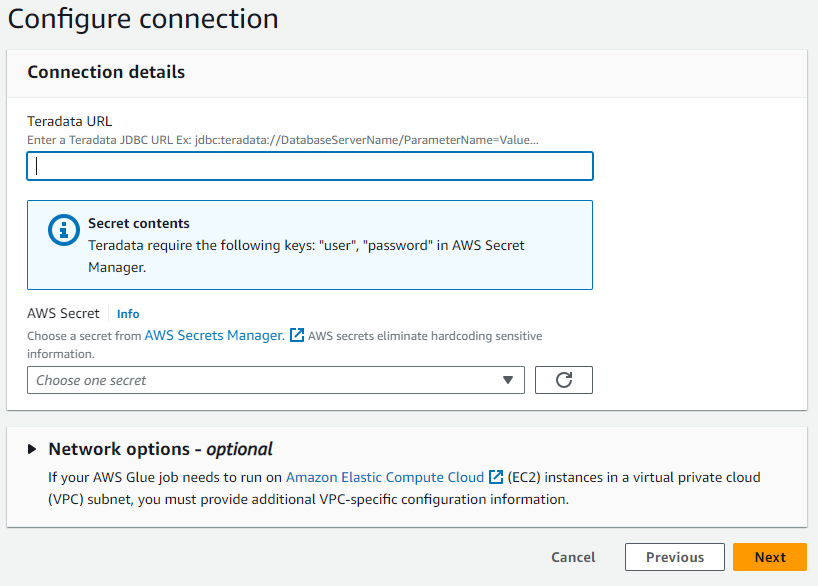
- En el cuadro de diálogo, escriba la URL de su instancia de Teradata Vantage en formato JDBC.
En el caso de ClearScape Analytics Experience, la URL sigue la siguiente estructura:
jdbc:teradata://<URL Host>/DATABASE=demo_user,DBS_PORT=1025
- Seleccione el secreto de AWS creado en el paso anterior.
- Asigne un nombre a su conexión y finalice el proceso de creación.
Crear un trabajo de AWS Glue
- En AWS Glue, seleccione
ETL Jobsy haga clic enScript editor.
- Seleccione
Sparkcomo motor y elija comenzar desde el principio.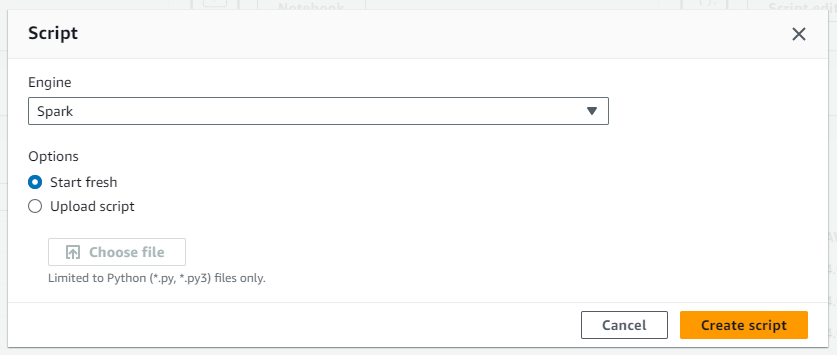
Redactar un script para la incorporación y catalogación automatizadas de datos de Teradata Vantage en Amazon S3
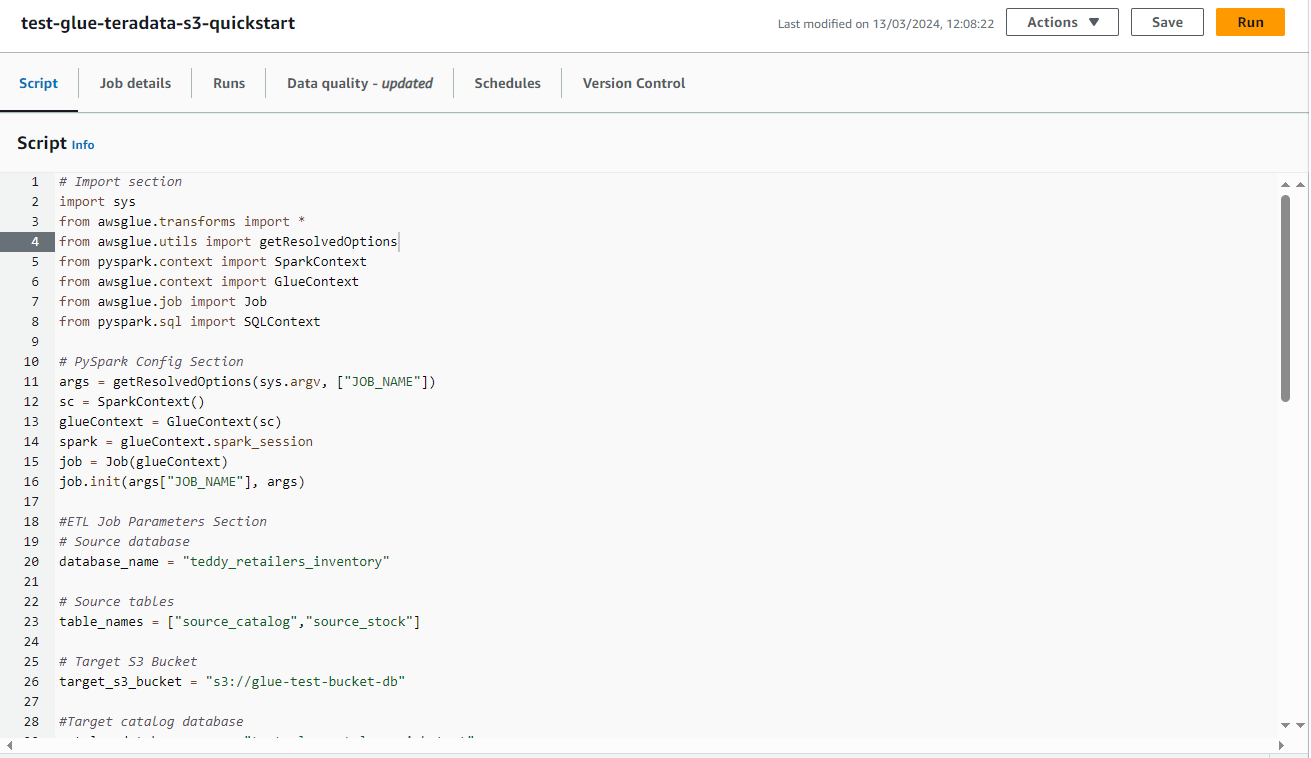
- Copie el siguiente script en el editor.
- El script requiere las siguientes modificaciones:
- Sustituya el nombre del depósito S3.
- Sustituya el nombre del base de datos del catálogo de Glue.
- Si no está siguiendo el ejemplo de la guía, modifique el nombre de la base de datos y las tablas que se van a incorporar y catalogar.
- Para fines de catalogación, en el ejemplo solo se incorpora la primera fila de cada tabla. Esta consulta se puede modificar para incorporar toda la tabla o para filtrar filas seleccionadas.
- El script requiere las siguientes modificaciones:
-
Asignar un nombre al script
-
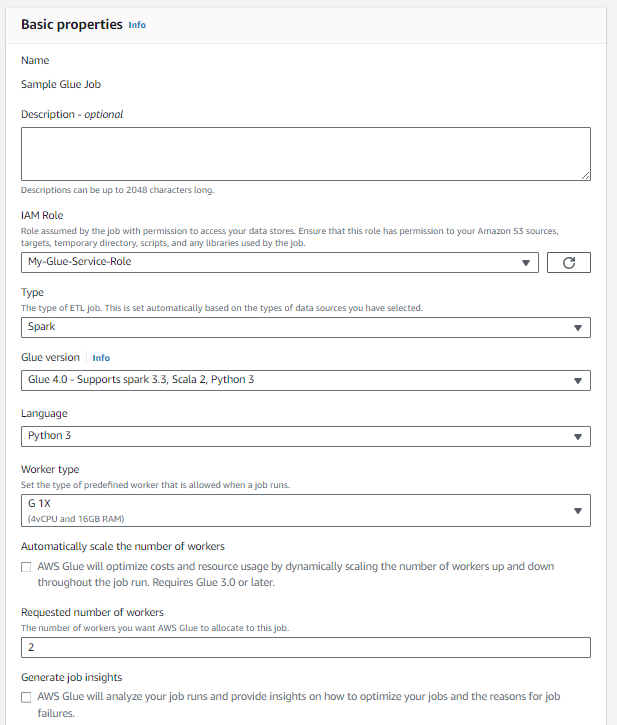
En Detalles del trabajo, Propiedades básicas:
- Seleccione el rol de IAM que creó para el trabajo de ETL.
- Para realizar pruebas, seleccione "2" como número solicitado de trabajadores, es el mínimo permitido.
 * En
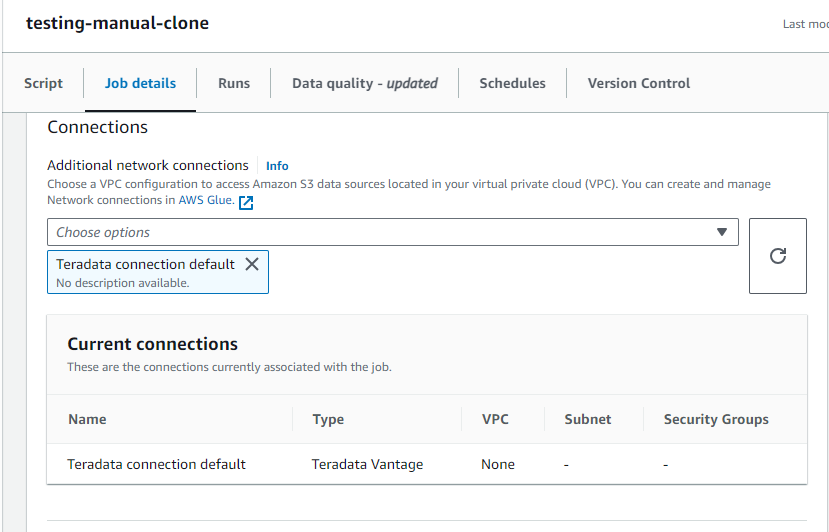
* En Advanced properties,Connectionsseleccione su conexión a Teradata Vantage.
Debe hacerse referencia dos veces a la conexión creada: una en la configuración del trabajo y otra en el propio script.
- Haga clic en
Save. - Haga clic en
Run.- El trabajo de ETL tarda un par de minutos en completarse, la mayor parte de este tiempo está relacionado con el inicio del clúster Spark.
Comprobación de los resultados
-
Una vez finalizado el trabajo:
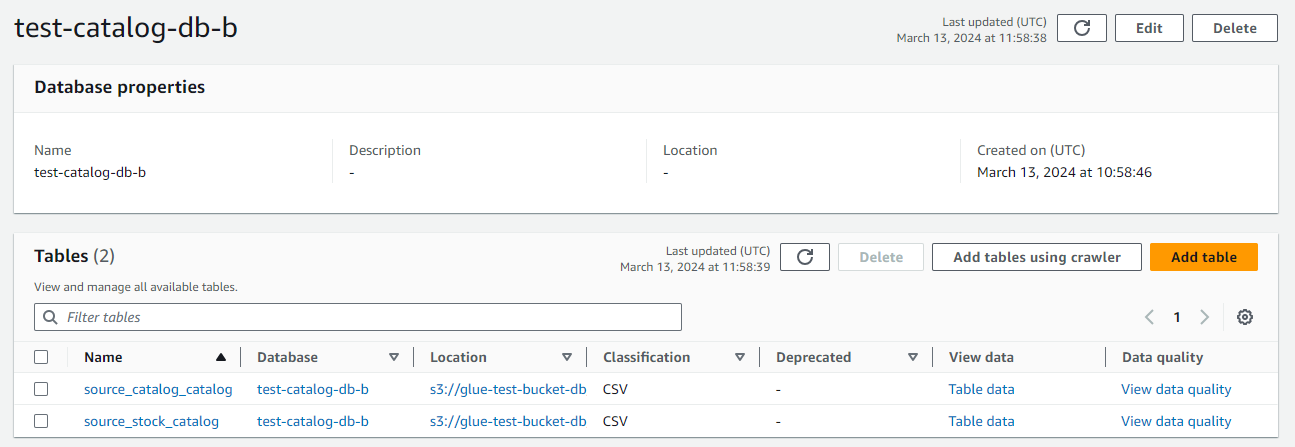
- Vaya a Catálogo de datos, Bases de datos.
- Haga clic en la base de datos del catálogo que ha creado.
- En esta ubicación, verá las tablas extraídas y catalogadas a través de su trabajo de ETL de Glue.
-
Todas las tablas incorporadas también están presentes como archivos comprimidos en S3. En raras ocasiones, estos archivos se consultarán directamente. Se pueden utilizar servicios como AWS Athena para consultar los archivos basándose en los metadatos del catálogo.
Resumen
En este inicio rápido se detalla el proceso de incorporación y catalogación de datos de Teradata Vantage a Amazon S3 con scripts de AWS Glue.
Lectura adicional
Si tiene alguna pregunta o necesita más ayuda, visite nuestro foro de la comunidad donde podrá obtener ayuda e interactuar con otros miembros de la comunidad.