Conectar Teradata Vantage a Salesforce mediante Amazon Appflow
Información general
Este tutorial describe el proceso para migrar datos entre Salesforce y Teradata Vantage. Contiene dos casos de uso:
- Recuperar información del cliente de Salesforce y combinarla con información de pedidos y envíos de Vantage para obtener información analítica.
- Actualizar la tabla
newleadsen Vantage con los datos de Salesforce y luego agregar los nuevos clientes potenciales nuevamente a Salesforce usando AppFlow.
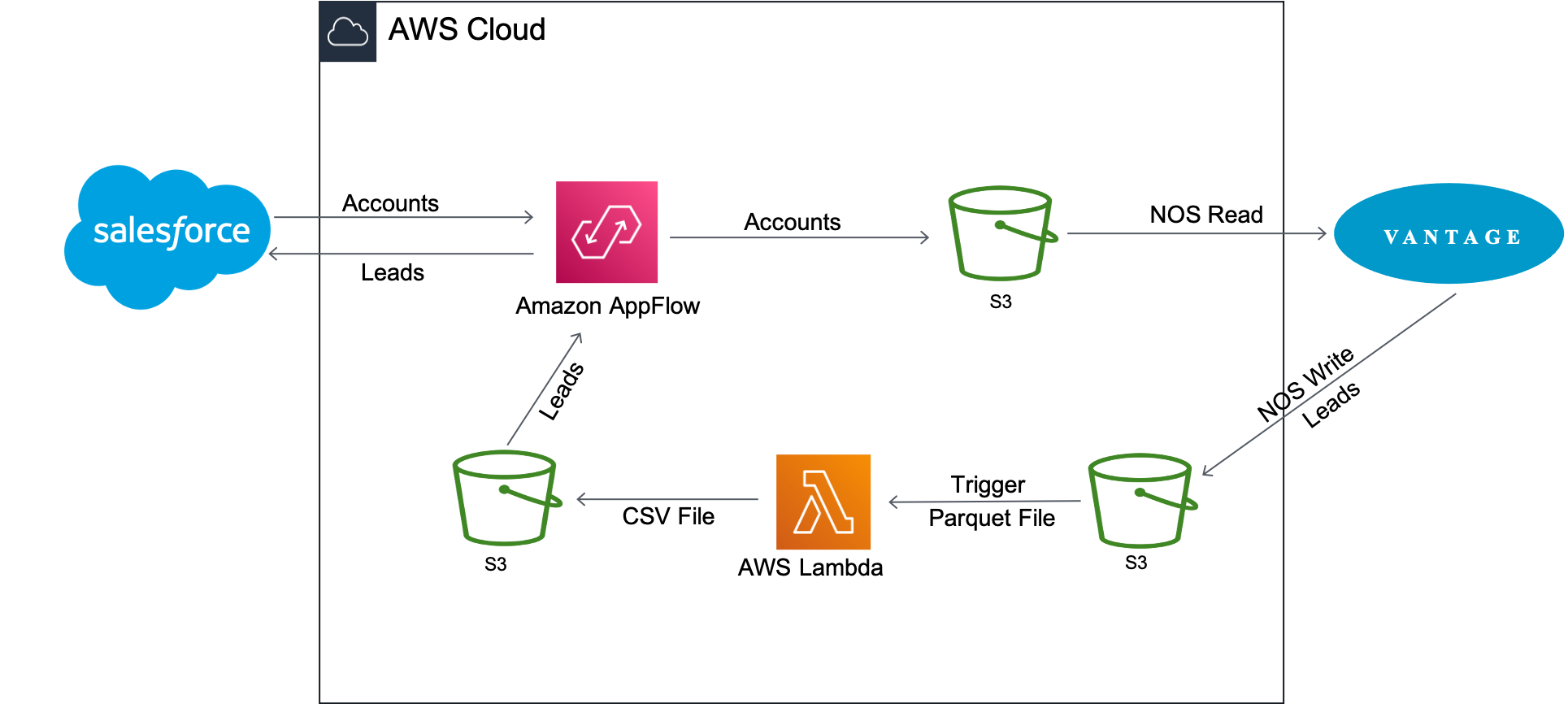
Amazon AppFlow transfiere los datos de la cuenta del cliente de Salesforce a Amazon S3. Luego, Vantage utiliza la funcionalidad de lectura Native Object Store (NOS) para unir los datos de Amazon S3 con los datos de Vantage con una única consulta.
La información de la cuenta se utiliza para actualizar la tabla newleads en Vantage. Una vez actualizada la tabla, Vantage la vuelve a escribir en el depósito de Amazon S3 con NOS Write. Se activa una función Lambda al llegar el nuevo archivo de datos de clientes potenciales para convertir el archivo de datos del formato Parquet al formato CSV, y AppFlow luego inserta los nuevos clientes potenciales nuevamente en Salesforce.
Acerca de Amazon AppFlow
Amazon AppFlow es un servicio de integración totalmente administrado que permite a los usuarios transferir datos de forma segura entre aplicaciones de software como servicio (SaaS) como Salesforce, Marketo, Slack y ServiceNow, y servicios de AWS como Amazon S3 y Amazon Redshift. AppFlow cifra automáticamente los datos en movimiento y permite a los usuarios restringir el flujo de datos a través de la Internet pública para aplicaciones SaaS que están integradas con AWS PrivateLink, lo que reduce la exposición a amenazas de seguridad.
A día de hoy, Amazon AppFlow tiene 16 fuentes para elegir y puede enviar los datos a cuatro destinos.
Acerca de Teradata Vantage
Teradata Vantage es la plataforma de datos multinube conectada para análisis empresarial, que resuelve los desafíos de datos desde el principio hasta la escala.
Vantage permite a las empresas iniciar computación o almacenamiento a pequeña escala y de manera elástica, pagando solo por lo que usan, aprovechando almacenes de objetos de bajo coste e integrando sus cargas de trabajo analíticas. Vantage es compatible con R, Python, Teradata Studio y cualquier otra herramienta basada en SQL.
Vantage combina análisis descriptivos, predictivos y prescriptivos, toma de decisiones autónoma, funciones de aprendizaje automático y herramientas de visualización en una plataforma unificada e integrada que descubre inteligencia empresarial en tiempo real a escala, sin importar dónde residan los datos.
Teradata Vantage Native Object Store (NOS) se puede utilizar para explorar datos en almacenes de objetos externos, como Amazon S3, mediante SQL estándar. No se requiere ninguna infraestructura informática especial del lado del almacenamiento de objetos para utilizar NOS. Los usuarios pueden explorar datos ubicados en un depósito de Amazon S3 simplemente creando una definición de tabla NOS que apunte a su depósito. Con NOS, puede importar datos rápidamente desde Amazon S3 o incluso unirlos con otras tablas en la base de datos Vantage.
Prerrequisitos
Se espera que esté familiarizado con el servicio Amazon AppFlow y Teradata Vantage.
Necesitará las siguientes cuentas y sistemas:
- Acceso a una instancia de Teradata Vantage.
Nota
Si necesita una instancia de prueba de Vantage, puede obtener una de forma gratuita en https://clearscape.teradata.com
- Una cuenta de AWS con el rol que puede crear y ejecutar flujos.
- Un depósito de Amazon S3 para almacenar datos de Salesforce (es decir, ptctsoutput)
- Un depósito de Amazon S3 para almacenar datos de Vantage sin procesar (archivo Parquet) (es decir, vantageparquet). Este depósito debe tener una política que permita el acceso a Amazon AppFlow
- Un depósito de Amazon S3 para almacenar datos de Vantage convertidos (archivo CSV) (es decir, vantagecsv)
- Una cuenta de Salesforce que cumpla con los siguientes requisitos:
- Su cuenta de Salesforce debe estar habilitada para acceder a la API. El acceso a la API está habilitado de forma predeterminada para las ediciones Enterprise, Unlimited, Developer y Performance.
- Su cuenta de Salesforce debe permitirle instalar aplicaciones conectadas. Si esto está deshabilitado, comuníquese con su administrador de Salesforce. Después de crear una conexión de Salesforce en Amazon AppFlow, verifique que la aplicación conectada denominada "Aplicación de inicio de sesión integrada de Amazon AppFlow" esté instalada en su cuenta de Salesforce.
- La política de token de actualización para la "Aplicación de inicio de sesión integrada de Amazon AppFlow" debe establecerse en "El token de actualización es válido hasta que se revoque". De lo contrario, sus flujos fallarán cuando caduque su token de actualización.
- Debe habilitar la captura de datos modificados en Salesforce para utilizar desencadenadores de flujo controlados por eventos. Desde Configuración, introduzca "Cambiar captura de datos" en Búsqueda rápida.
- Si su aplicación Salesforce aplica restricciones de direcciones IP, debe incluir en la lista blanca las direcciones que utiliza Amazon AppFlow. Para obtener más información, consulte Rangos de direcciones IP de AWS en Referencia general de Amazon Web Services.
- Si va a transferir más de un millón de registros de Salesforce, no puede elegir ningún campo compuesto de Salesforce. Amazon AppFlow utiliza las API Bulk de Salesforce para la transferencia, lo que no permite la transferencia de campos compuestos.
- Para crear conexiones privadas utilizando AWS PrivateLink, debe habilitar los permisos de usuario "Administrador de metadatos" y "Administrar conexiones externas" en su cuenta de Salesforce. Actualmente, las conexiones privadas están disponibles en las regiones de AWS us-east-1 y us-west-2.
- Algunos objetos de Salesforce no se pueden actualizar, como los objetos de historial. Para estos objetos, Amazon AppFlow no admite la exportación incremental (la opción "Transferir solo datos nuevos") para flujos activados por programación. En su lugar, puede elegir la opción "Transferir todos los datos" y luego seleccionar el filtro apropiado para limitar los registros que transfiere.
Procedimiento
Una vez que haya cumplido los requisitos previos, siga estos pasos:
- Creación de un flujo de Salesforce a Amazon S3
- Exploración de datos mediante NOS
- Exporte los datos de Vantage a Amazon S3 usando NOS
- Crear un flujo de Amazon S3 a Salesforce
Creación de un flujo de Salesforce a Amazon S3
Este paso crea un flujo utilizando Amazon AppFlow. Para este ejemplo, utilizamos una cuenta de desarrollador de Salesforce para conectarnos a Salesforce.
Vaya a la consola de AppFlow, inicie sesión con sus credenciales de inicio de sesión de AWS y haga clic en Crear flujo. Asegúrese de estar en la región correcta y de que se cree el depósito para almacenar datos de Salesforce.
Paso 1: Especificar los detalles del flujo
Este paso proporciona información básica para su flujo.
Complete Nombre del flujo (es decir, salesforce) y Descripción del flujo (opcional), deje Personalizar la configuración de cifrado (avanzado) sin marcar. Haga clic en Siguiente.
Paso 2: Configurar el flujo
Este paso proporciona información sobre el origen y el destino de su flujo. En este ejemplo, utilizaremos Salesforce como origen y Amazon S3 como destino.
-
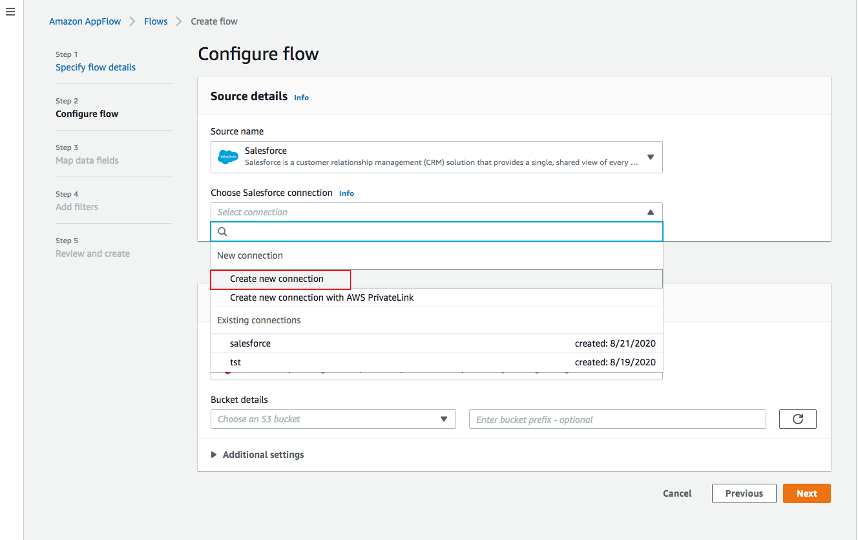
Para Nombre de la fuente, elija Salesforce, posteriormente Crear una nueva conexión para Elegir la conexión de Salesforce.
-
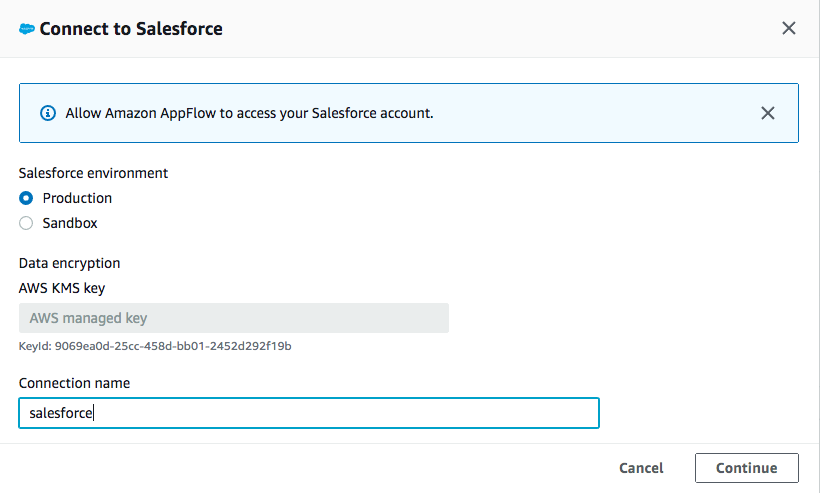
Utilice los valores predeterminados para Entorno de Salesforce y Cifrado de datos. Asigne un nombre a su conexión (por ejemplo, salesforce) y haga clic en Continuar.
-
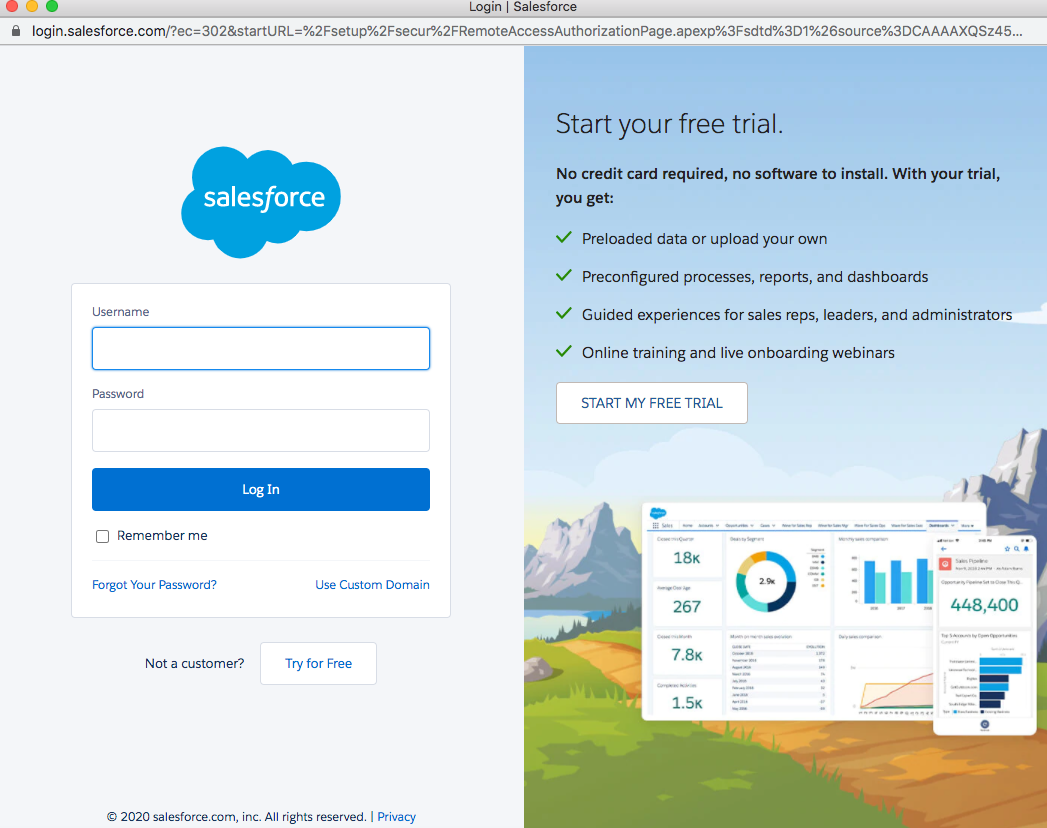
En la ventana de inicio de sesión de Salesforce, introduzca su Nombre de usuario y Contraseña. Haga clic en Iniciar sesión
-
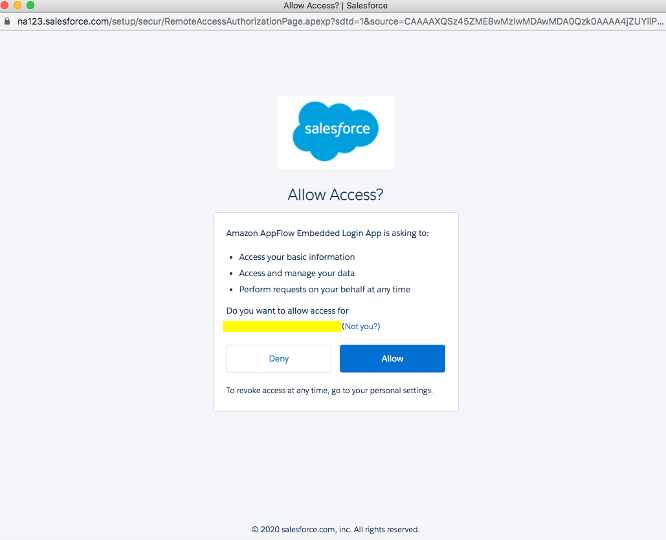
Haga clic en Permitir para permitir que AppFlow acceda a sus datos e información de Salesforce.
-
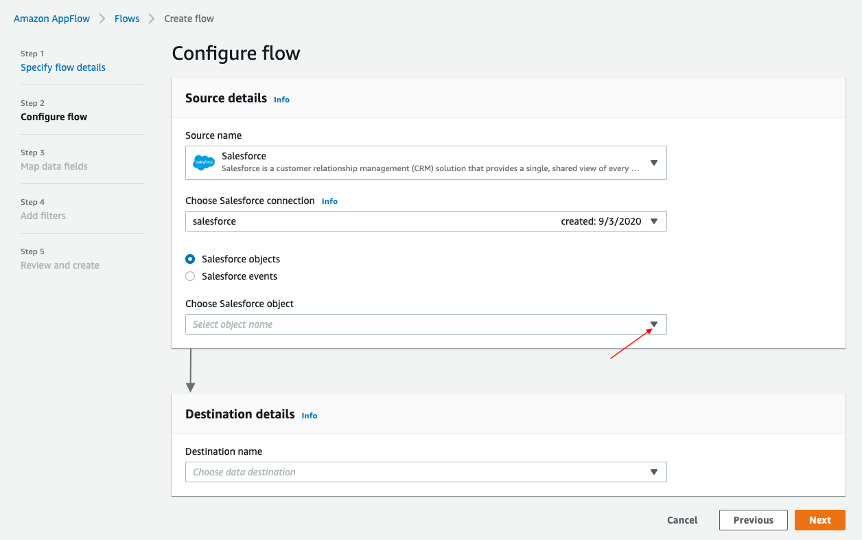
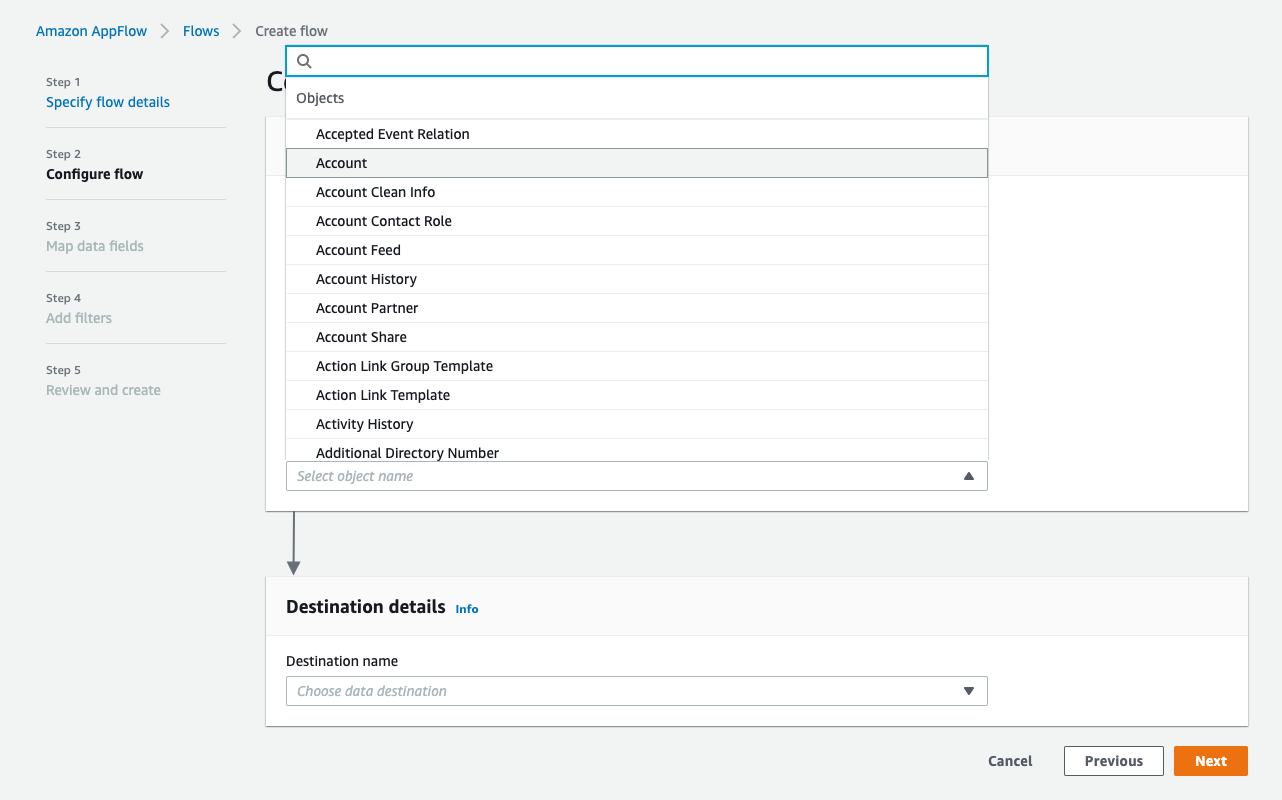
De vuelta en la ventana AppFlow Configurar flujo, use Objetos de Salesforce y elija Cuenta para que sea el objeto de Salesforce.
-
Utilice Amazon S3 como Nombre de destino. Seleccione el depósito que creó anteriormente en el cual quiere que se almacenen los datos (es decir, ptctsoutput).
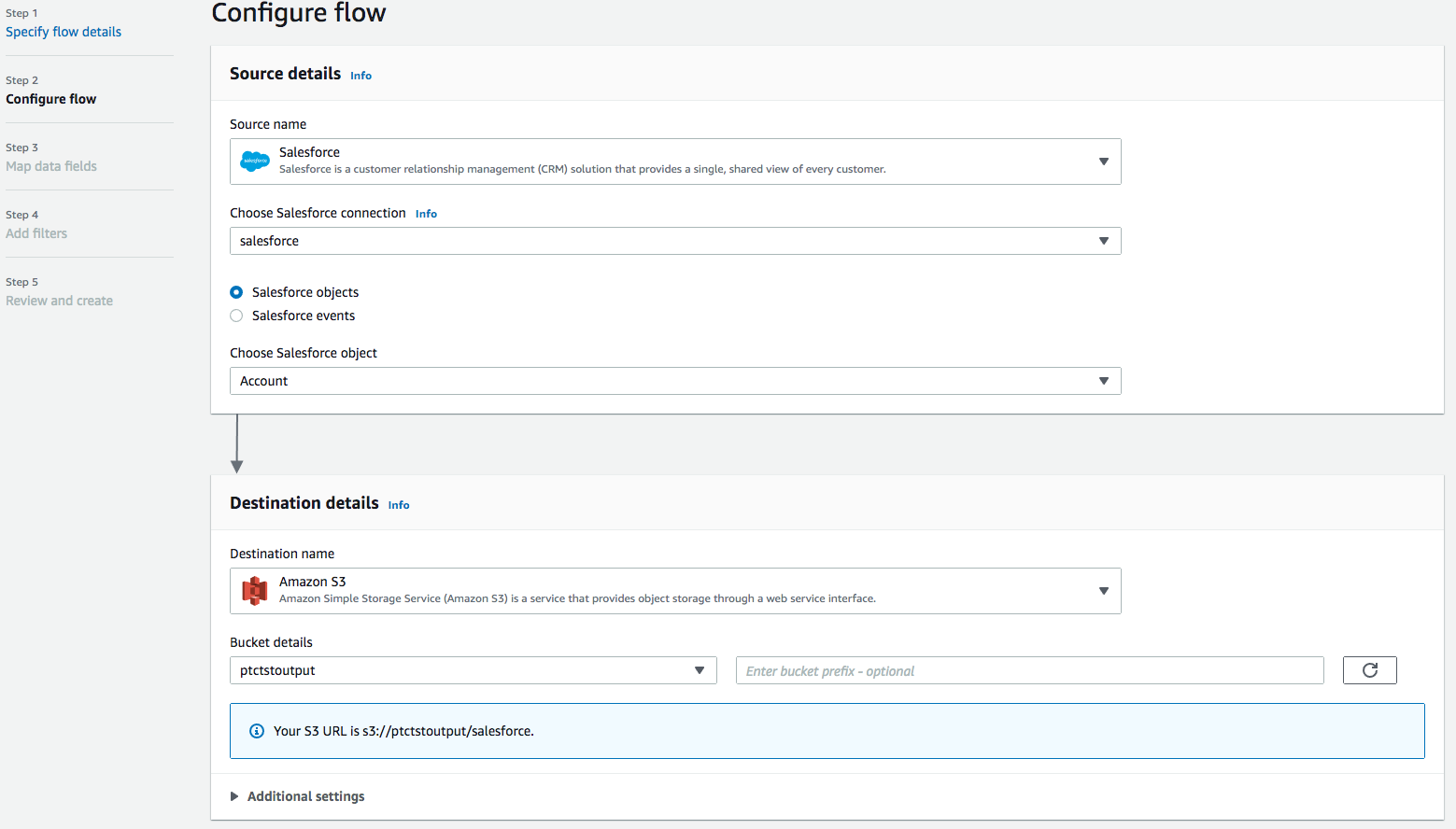
-
Disparador de flujos es Ejecutar bajo demanda. Haga clic en Siguiente.
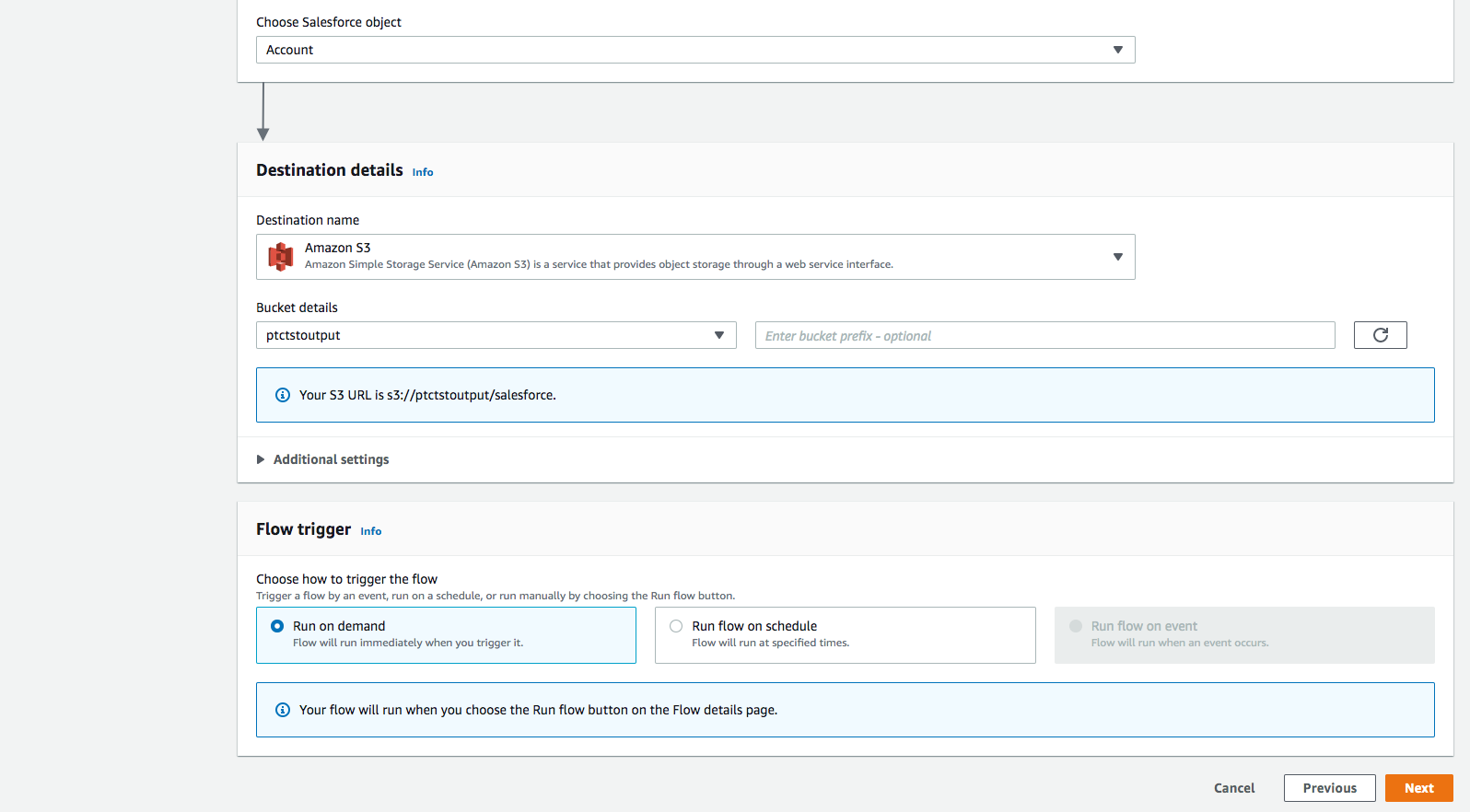
Paso 3: Asignar campos de datos
Este paso determina cómo se transfieren los datos desde el origen al destino.
- Utilice Asignar campos manualmente como Método de asignación
- Para simplificar, elija Asignar todos los campos directamente para Asignación de archivado de origen a destino.
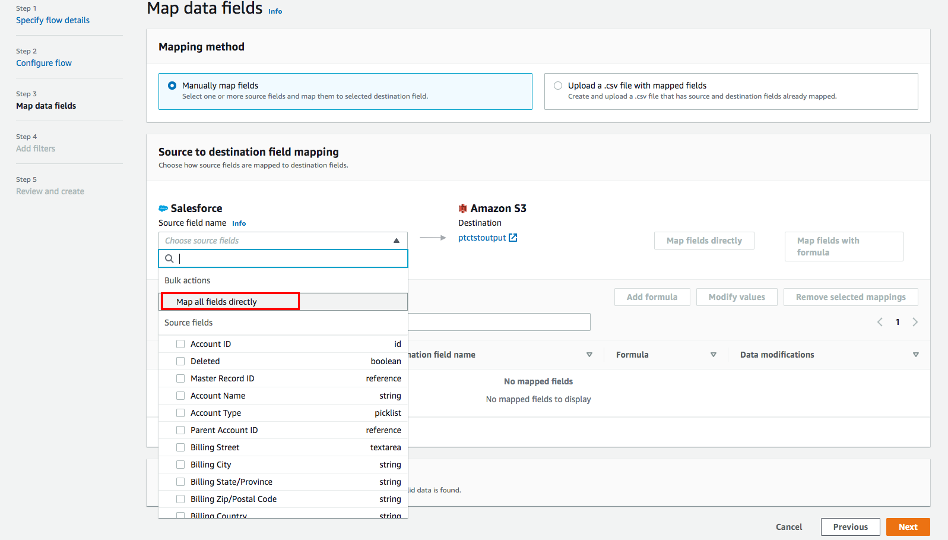
Una vez que haga clic en "Asignar todos los campos directamente", todos los campos se mostrarán bajo Campos asignados. Haga clic en la casilla de verificación de los campos que quiera para Agregar fórmula (concatenados), Modificar valores (enmascarar o truncar valores de campo) o Eliminar asignaciones seleccionadas.
Para este ejemplo, no se marcará ninguna casilla de verificación.
- Para Validaciones, agregue una condición para omitir el registro que no contiene "Dirección de envío" (opcional). Haga clic en Siguiente.
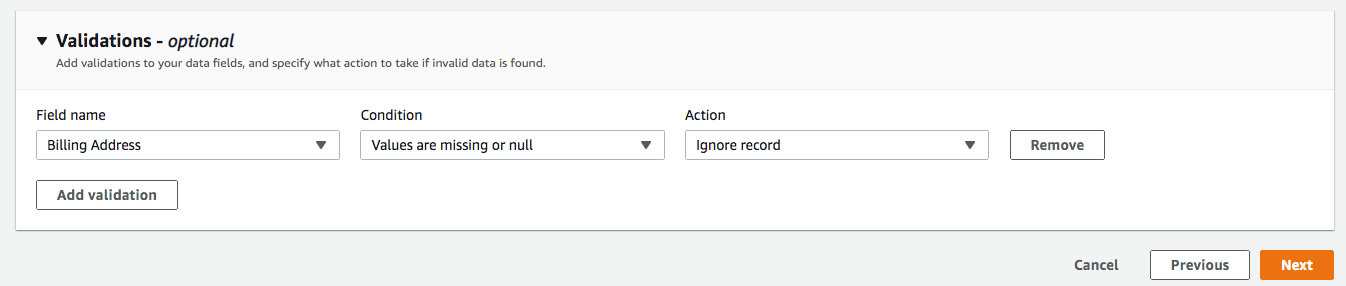
Paso 4: Agregar filtros
Puede especificar un filtro para determinar qué registros transferir. Para este ejemplo, agregue una condición para filtrar los registros que se eliminan (opcional). Haga clic en Siguiente.
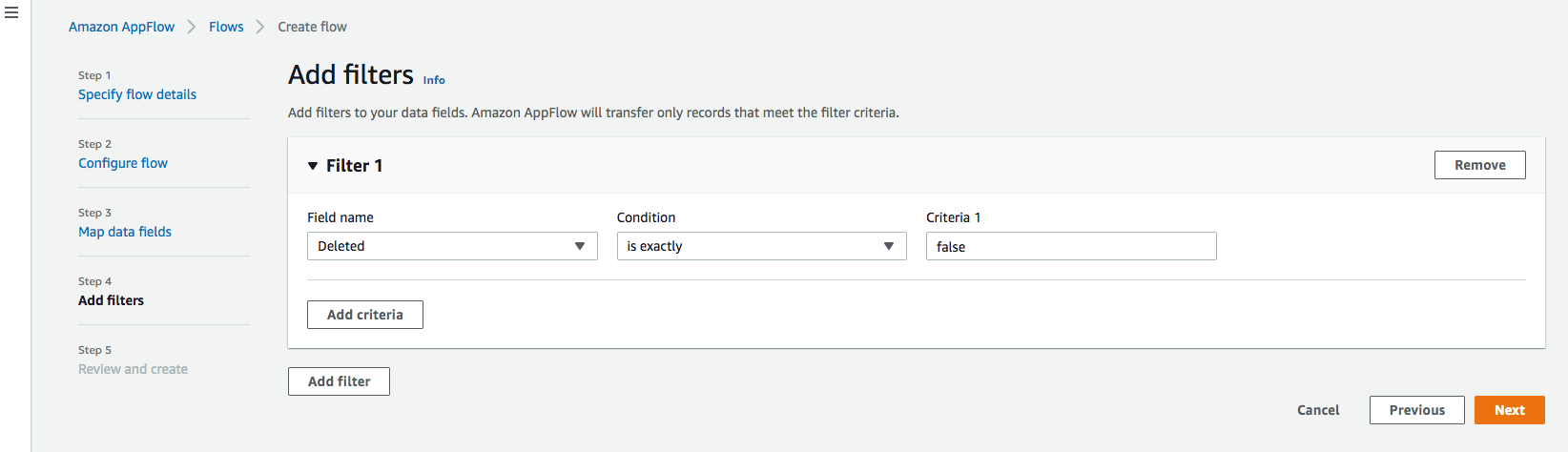
Paso 5. Revisar y crear
Revise toda la información que acaba de introducir. Modifíquela si es necesario. Haga clic en Crear flujo.
Se mostrará un mensaje de creación exitosa del flujo con la información del flujo una vez que se cree el flujo.
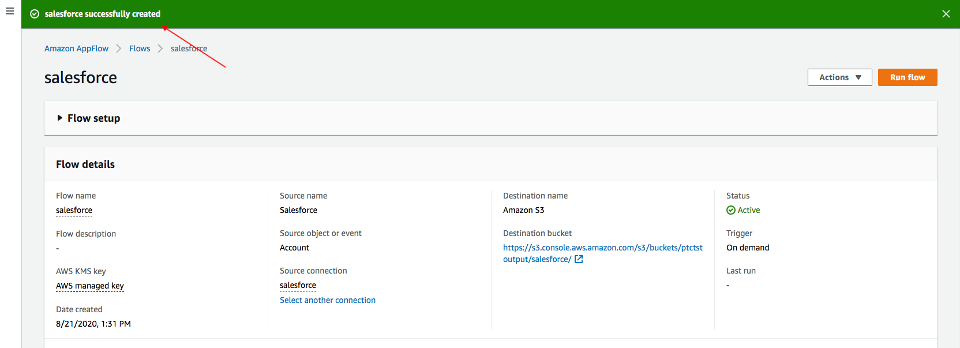
Flujo de ejecución
Haga clic en Flujo de ejecución en la esquina superior derecha.
Al finalizar la ejecución del flujo, se mostrará un mensaje para indicar una ejecución exitosa.
Ejemplo de mensaje:

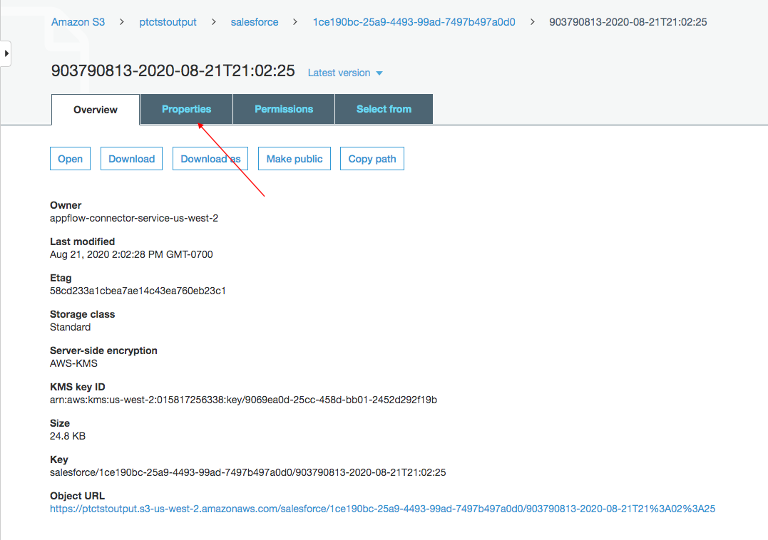
Haga clic en el enlace al depósito para ver los datos. Los datos de Salesforce estarán en formato JSON.
Cambiar propiedades del archivo de datos
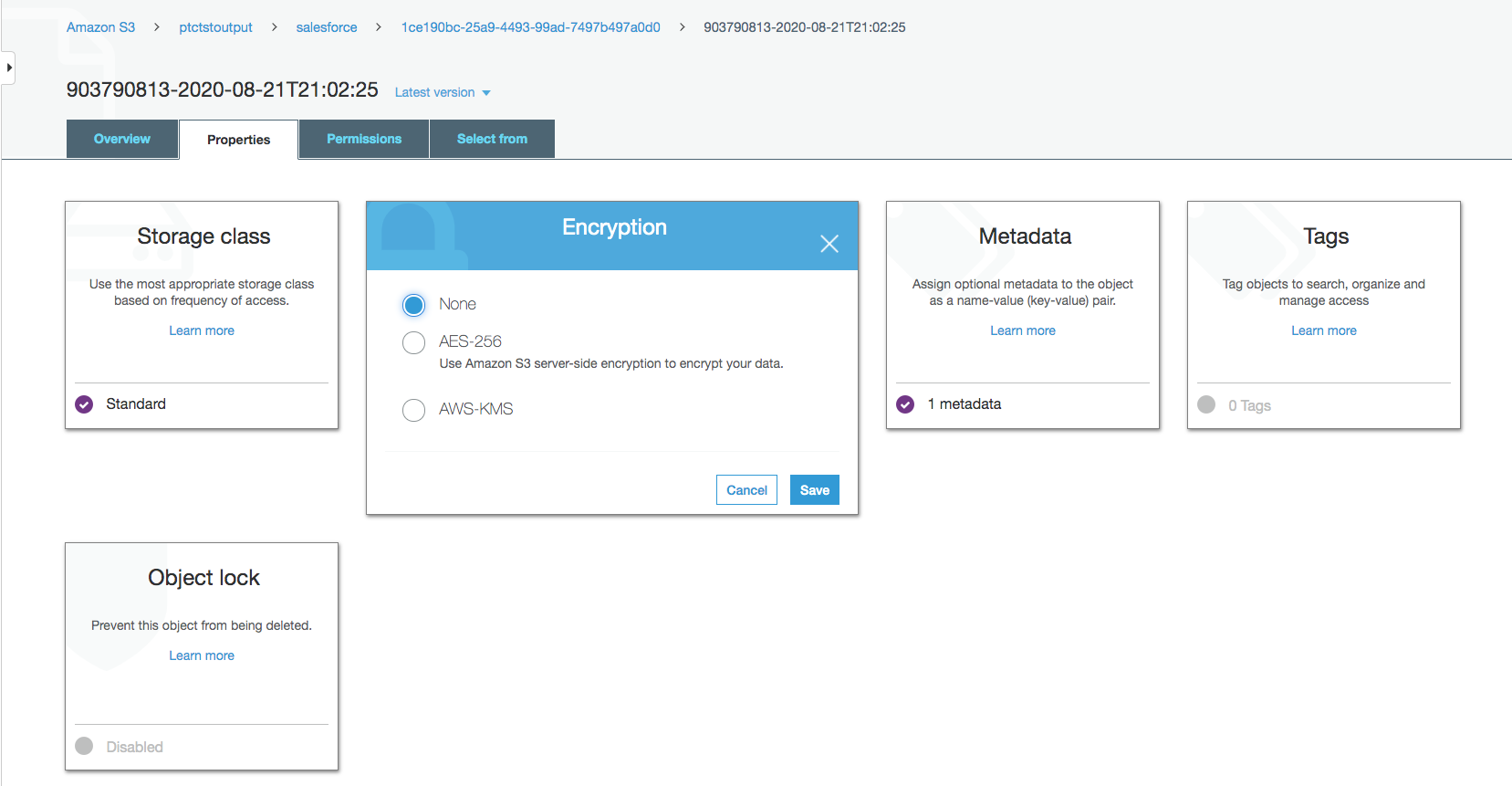
De forma predeterminada, los datos de Salesforce están cifrados. Necesitamos eliminar el cifrado para que NOS pueda acceder a él.
Haga clic en el archivo de datos en su depósito de Amazon S3 y, posteriormente, haga clic en la pestaña Propiedades.
Haga clic en AWS-KMS desde Cifrado y cambie el cifrado de AWS-KMS a None. Haga clic en Guardar.
Explorar datos mediante NOS
Native Object Store tiene funcionalidades integradas para explorar y analizar datos en Amazon S3. Esta sección enumera algunas funciones de uso común de NOS.
Crear tabla externa
La tabla externa permite hacer referencia fácilmente a los datos externos dentro del Vantage Advanced SQL Engine y hace que los datos estén disponibles en un formato relacional estructurado.
Para crear una tabla externa, primero inicie sesión en el sistema Teradata Vantage con sus credenciales. Cree un objeto AUTHORIZATION con claves de acceso para acceder al depósito de Amazon S3. El objeto de autorización mejora la seguridad al establecer control sobre quién puede usar una tabla externa para acceder a los datos de Amazon S3.
"USER" es el AccessKeyId de su cuenta de AWS y "PASSWORD" es la SecretAccessKey.
Cree una tabla externa con el archivo JSON en Amazon S3 usando el siguiente comando.
Como mínimo, la definición de la tabla externa debe incluir un nombre de tabla y una cláusula de ubicación (resaltada en amarillo) que apunte a los datos del almacén de objetos. La ubicación requiere un nombre único de nivel superior, denominado "depósito" en Amazon.
Si el nombre del archivo no tiene una extensión estándar (.json, .csv, .parquet) al final, también se requiere la definición de las columnas Location y Payload (resaltadas en turquesa) para indicar el tipo de archivo de datos.
Las tablas externas siempre se definen como tablas sin índice primario (No Primary Index, NoPI).
Una vez creada la tabla externa, puede consultar el contenido del conjunto de datos de Amazon S3 haciendo clic en "Seleccionar" en la tabla externa.
La tabla externa solo contiene dos columnas: Ubicación y Carga útil. La ubicación es la dirección en el sistema de almacenamiento de objetos. Los propios datos se representan en la columna de carga útil, con el valor de carga útil dentro de cada registro de la tabla externa que representa un único objeto JSON y todos sus pares nombre-valor.
Salida de muestra de "SELECT * FROM salesforce;".
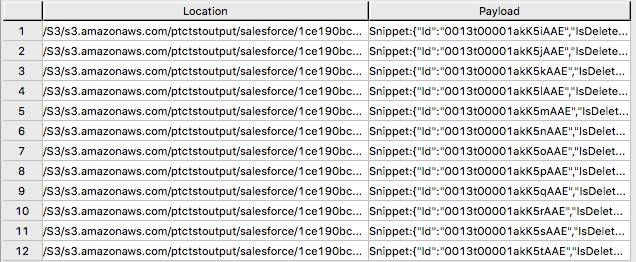
Formulario de salida de muestra "SELECT payload.* FROM salesforce;".

Operador de tabla JSON_KEYS
Los datos JSON pueden contener diferentes atributos en diferentes registros. Para determinar la lista completa de posibles atributos en un almacén de datos, utilice JSON_KEYS:
Salida parcial:

Crear vista
Las vistas pueden simplificar los nombres asociados con los atributos de carga útil, facilitar la codificación de SQL ejecutable con datos del almacén de objetos y ocultar las referencias de ubicación en la tabla externa para que parezcan columnas normales.
A continuación se muestra un ejemplo de declaración de creación de vista con los atributos descubiertos en el operador de tabla JSON_KEYS anterior.
Salida parcial:

Operador de tabla READ_NOS
El operador de tabla READ_NOS se puede utilizar para muestrear y explorar un porcentaje de los datos sin haber definido primero una tabla externa, o para ver una lista de las claves asociadas con todos los objetos especificados por una cláusula de Location.
Salida:

Unir datos de Amazon S3 a tablas en la base de datos
La tabla externa se puede unir a una tabla en Vantage para su posterior análisis. Por ejemplo, la información de pedidos y envíos se encuentra en Vantage en estas tres tablas: Orders, Order_Items y Shipping_Address.
DDL para Orders:
DDL para Order_Items:
DDL para Shipping_Address:
Y las tablas tienen los siguientes datos:
Orders:

Order_Items:

Shipping_Address:

Al unir la tabla externa de Salesforce a la tabla de base de datos establecida Orders, Order_Items y Shipping_Address, podemos recuperar la información del pedido del cliente con la información de envío del cliente.
Resultados:

Importar datos de Amazon S3 a Vantage
Tener una copia persistente de los datos de Amazon S3 puede resultar útil cuando se espera un acceso repetitivo a los mismos datos. La tabla externa NOS no realiza automáticamente una copia persistente de los datos de Amazon S3. A continuación se describen algunos enfoques para capturar los datos en la base de datos:
Se puede utilizar una instrucción "CREATE TABLE AS … WITH DATA" con la definición de tabla externa actuando como tabla de origen. Utilice este enfoque para elegir selectivamente qué atributos dentro de la carga útil de la tabla externa desea incluir en la tabla de destino y cómo se nombrarán las columnas de la tabla relacional.
SELECT* * *FROM* salesforceVantage;resultados parciales:

Una alternativa al uso de una tabla externa es utilizar el operador de tabla READ_NOS. Este operador de tabla le permite acceder a datos directamente desde un almacén de objetos sin crear primero una tabla externa. Combinando READ_NOS con una cláusula CREATE TABLE AS para crear una versión persistente de los datos en la base de datos.
Resultados de la tabla salesforceReadNOS:

Otra forma de colocar datos de Amazon S3 en una tabla relacional es mediante "INSERT SELECT". Con este enfoque, la tabla externa es la tabla de origen, mientras que una tabla permanente recién creada es la tabla en la que se insertará. Al contrario del ejemplo READ_NOS anterior, este enfoque requiere que la tabla permanente se cree de antemano.
Una ventaja del método INSERT SELECT es que puede cambiar los atributos de la tabla de destino. Por ejemplo, puede especificar que la tabla de destino sea MULTISET o no, o puede elegir un índice principal diferente.
Resultados de muestra:

Exporte los datos de Vantage a Amazon S3 usando NOS
Tengo una tabla newleads con 1 fila en el sistema Vantage.

Tenga en cuenta que no hay información de dirección para este cliente potencial. Usemos la información de la cuenta recuperada de Salesforce para actualizar la newleads tabla
Ahora el nuevo cliente potencial tiene información de dirección.

Escriba la nueva información del cliente potencial en el depósito S3 usando WRITE_NOS.
Donde Access_ID es AccessKeyID y Access_Key es SecretAccessKey del depósito.
Crear un flujo de Amazon S3 a Salesforce
Repita el paso 1 para crear un flujo utilizando Amazon S3 como origen y Salesforce como destino.
Paso 1. Especificar los detalles del flujo
Este paso proporciona información básica para su flujo.
Complete Nombre del flujo (es decir, vantage2sf) y Descripción del flujo (opcional), deje Personalizar la configuración de cifrado (avanzado) sin marcar. Haga clic en Siguiente.
Paso 2. Configurar el flujo
Este paso proporciona información sobre el origen y el destino de su flujo. En este ejemplo, utilizaremos Amazon S3 como origen y Salesforce como destino.
- Para Detalles de origen, elija Amazon S3, posteriormente elija el depósito donde escribió su archivo CSV (es decir, vantagecsv)
- Para Detalles de destino, elija Salesforce, use la conexión que creó en el Paso 1 de la lista desplegable para Elegir la conexión de Salesforce y Lead como Elegir objeto de Salesforce.
- Para Manejo de errores, utilice el valor predeterminado Detener la ejecución del flujo actual.
- Disparador de flujos es Ejecutar bajo demanda. Haga clic en Siguiente.
Paso 3. Asignar los campos de datos
Este paso determina cómo se transfieren los datos desde el origen al destino.
-
Utilice Asignar campos manualmente como Método de asignación
-
Utilice Insertar nuevos registros (predeterminado) como Preferencia de registro de destino
-
Para Asignación de archivado de origen a destino, utilice la siguiente asignación
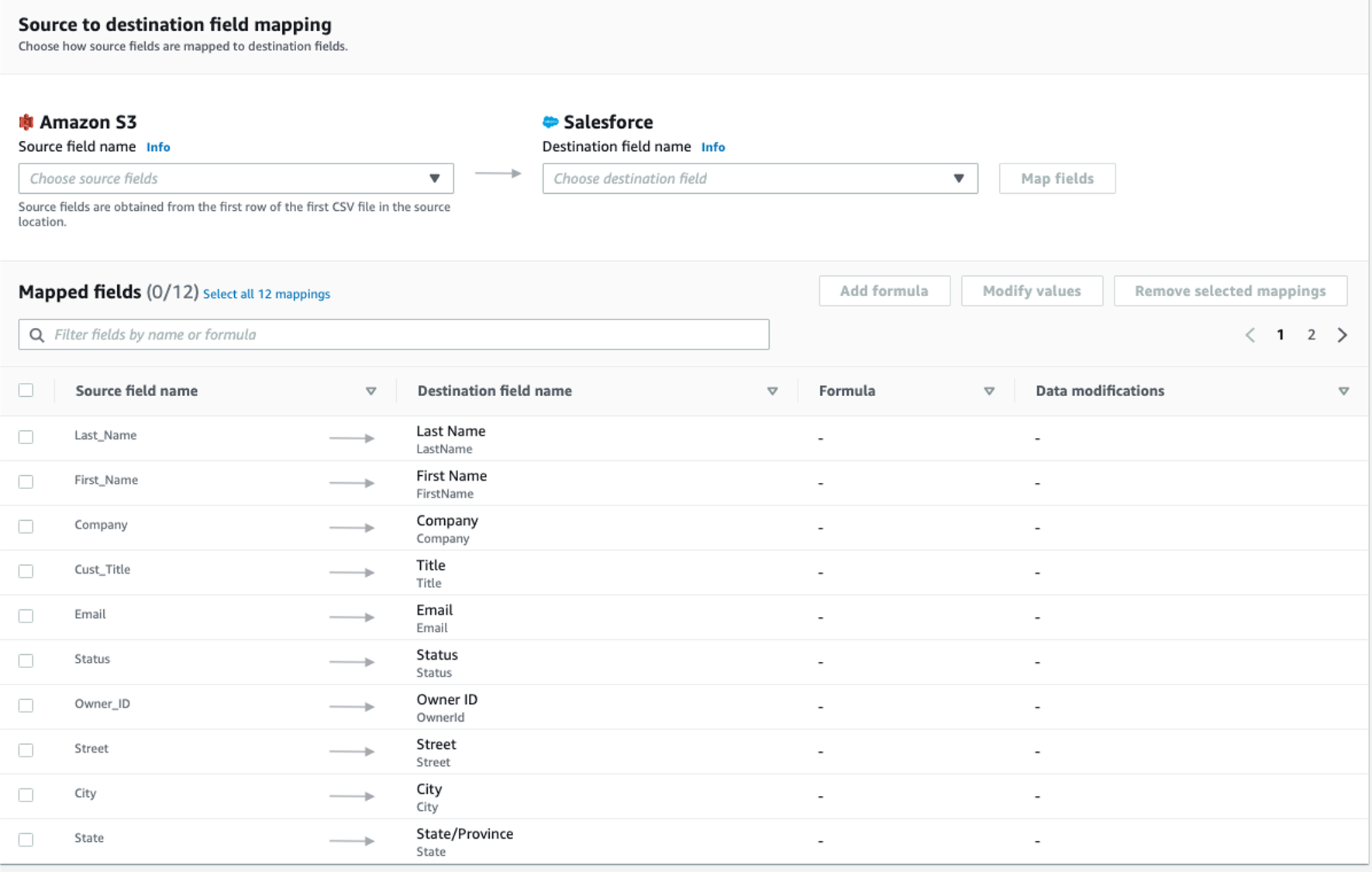

-
Haga clic en Siguiente.
Paso 4. Agregar filtros
Puede especificar un filtro para determinar qué registros transferir. Para este ejemplo, no se agrega ningún filtro. Haga clic en Siguiente.
Paso 5. Revisar y crear
Revise toda la información que acaba de introducir. Modifíquela si es necesario. Haga clic en Crear flujo.
Se mostrará un mensaje de creación exitosa del flujo con la información del flujo una vez que se cree el flujo.
Flujo de ejecución
Haga clic en Flujo de ejecución en la esquina superior derecha.
Al finalizar la ejecución del flujo, se mostrará un mensaje para indicar una ejecución exitosa.
Ejemplo de mensaje:

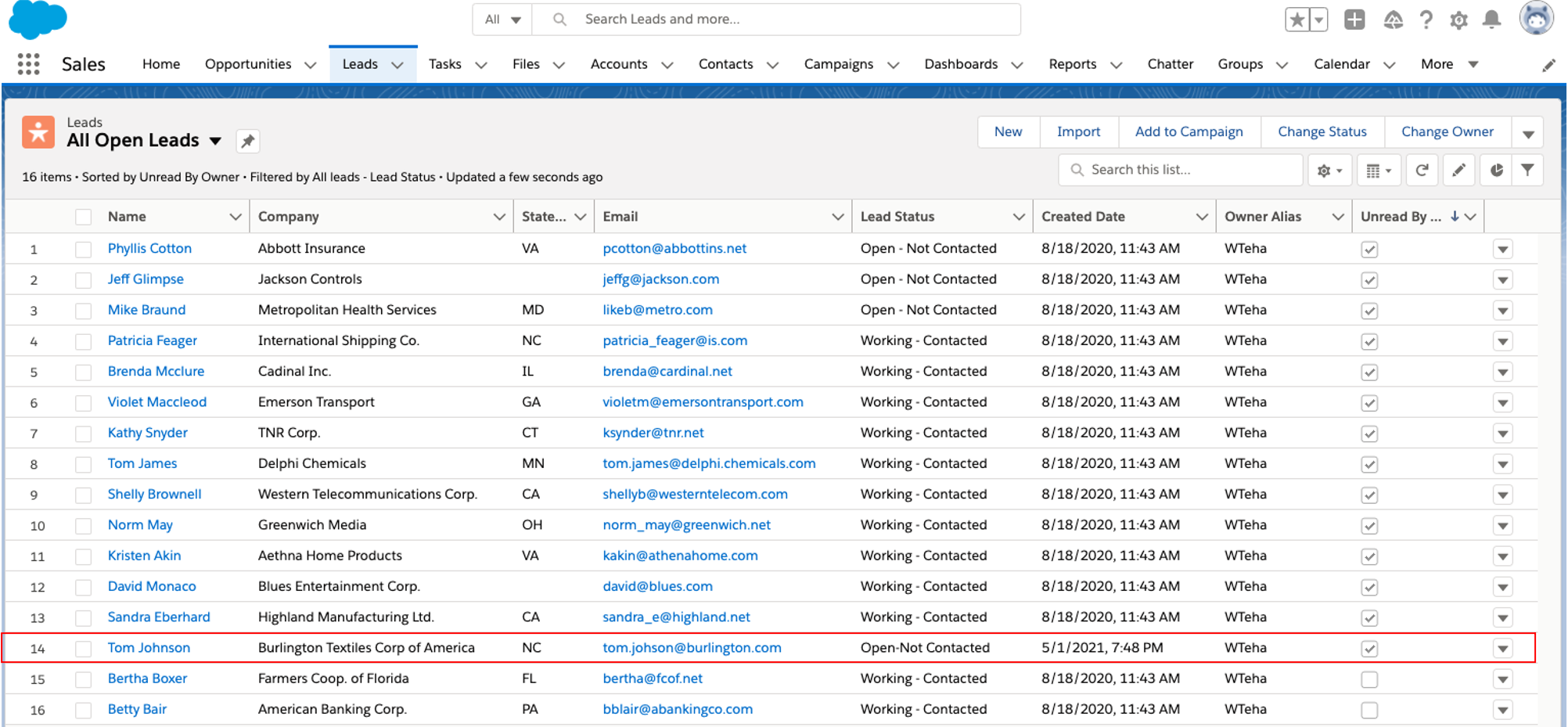
Vaya a la página de Salesforce; se agregó el nuevo cliente potencial Tom Johnson.
Limpieza (opcional)
Una vez que haya terminado con los datos de Salesforce, para evitar incurrir en cargos en su cuenta de AWS (es decir, AppFlow, Amazon S3, Vantage y VM) por los recursos utilizados, siga estos pasos:
-
AppFlow:
- Elimine las "Conexiones" que creó para el flujo
- Elimine los flujos
-
Depósito y archivo de Amazon S3:
- Vaya a los depósitos de Amazon S3 donde está almacenado el archivo de datos de Vantage y elimine los archivos
- Si no es necesario conservar los depósitos, elimínelos
-
Instancia de Teradata Vantage
- Detenga/termine la instancia si ya no es necesaria
Si tiene alguna pregunta o necesita más ayuda, visite nuestro foro de la comunidad donde podrá obtener ayuda e interactuar con otros miembros de la comunidad.