Transformar datos cargados con Airbyte mediante dbt
Información general
Este tutorial demuestra cómo utilizar dbt (Data Build Tool) para transformar la carga de datos externos a través de Airbyte (una herramienta de extracción de carga de código abierto) en Teradata Vantage.
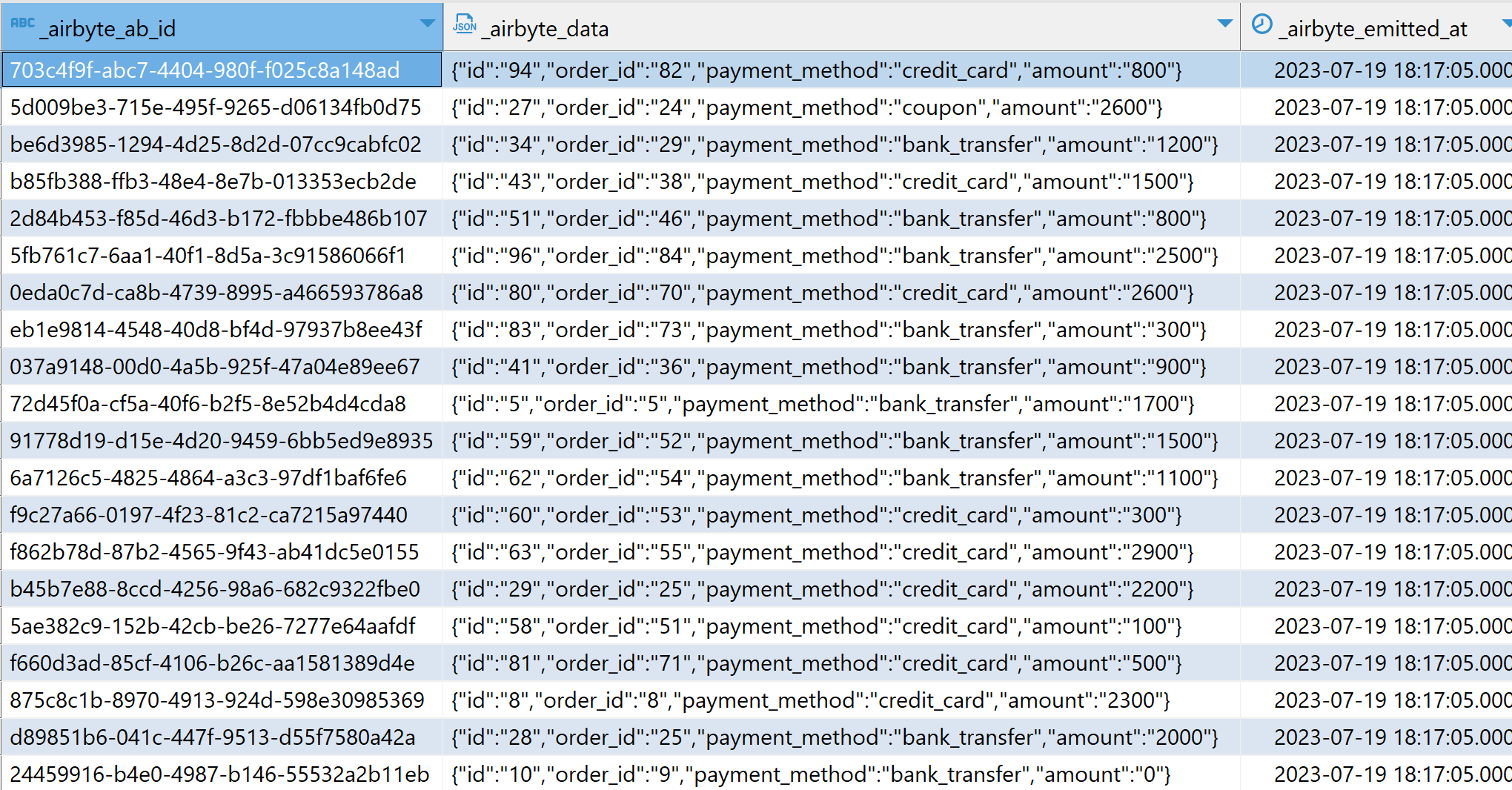
Este tutorial se basa en el tutorial de Jaffle Shop sobre dbt original con un pequeño cambio; en lugar de usar el comando dbt seed, el conjunto de datos de Jaffle Shop se carga desde Google Sheets en Teradata Vantage usando Airbyte. Los datos cargados a través de airbyte están contenidos en columnas JSON como se puede ver en la siguiente imagen:
Prerrequisitos
- Acceso a una instancia de Teradata Vantage.
Nota
Si necesita una instancia de prueba de Vantage, puede obtener una de forma gratuita en https://clearscape.teradata.com
- Datos de muestra: los datos de muestra del conjunto de datos de Jaffle Shop se pueden encontrar en Google Sheets.
- Referencia del repositorio del proyecto dbt: Proyecto Jaffle con Airbyte.
- Python 3.7, 3.8, 3.9, 3.10 o 3.11 instalado.
Carga de datos de muestra
- Siga los pasos del tutorial de Airbyte. Asegúrese de cargar datos de la hoja de cálculo de Jaffle Shop y no del conjunto de datos predeterminado al que se hace referencia en el tutorial de Airbyte. Además, establezca
Default Schemaen el destino de Teradata enairbyte_jaffle_shop.
Cuando configura un destino de Teradata en Airbyte, le pedirá un Default Schema. Establezca Default Schema en airbyte_jaffle_shop.
Clonar el proyecto
Clone el repositorio del tutorial y cambie el directorio al directorio del proyecto:
Instalar dbt
-
Cree un nuevo entorno de python para administrar dbt y sus dependencias. Activar el entorno:
NotaYou can activate the virtual environment in Windows by executing the corresponding batch file
./myenv/Scripts/activate. -
Instale el módulo
dbt-teradatay sus dependencias. El módulo dbt principal se incluye como dependencia, por lo que no es necesario instalarlo por separado:
Configurar dbt
-
Inicialice un proyecto dbt.
El asistente del proyecto dbt le pedirá un nombre de proyecto y un sistema de gestión de base de datos para utilizar en el proyecto. En esta demostración, definimos el nombre del proyecto como "dbt_airbyte_demo". Dado que utilizamos el conector dbt-teradata, el único sistema de gestión de bases de datos disponible es Teradata.


-
Configure el archivo
profiles.ymlubicado en el directorio$HOME/.dbt. Si el archivoprofiles.ymlno está presente, puede crear uno nuevo. -
Ajuste
server,username,passwordpara que coincida conHOST,Username,Passwordde su instancia de Teradata respectivamente. -
En esta configuración,
schemarepresenta la base de datos que contiene los datos de muestra; en nuestro caso, ese es el esquema predeterminado que definimos en Airbyteairbyte_jaffle_shop. -
Una vez que el archivo
profiles.ymlesté listo, podemos validar la configuración. Vaya a la carpeta del proyecto dbt y ejecute el comando:Si el comando de depuración devolvió errores, es probable que tenga un problema con el contenido de
profiles.yml. Si la configuración es correcta, recibirá un mensajeAll checks passed!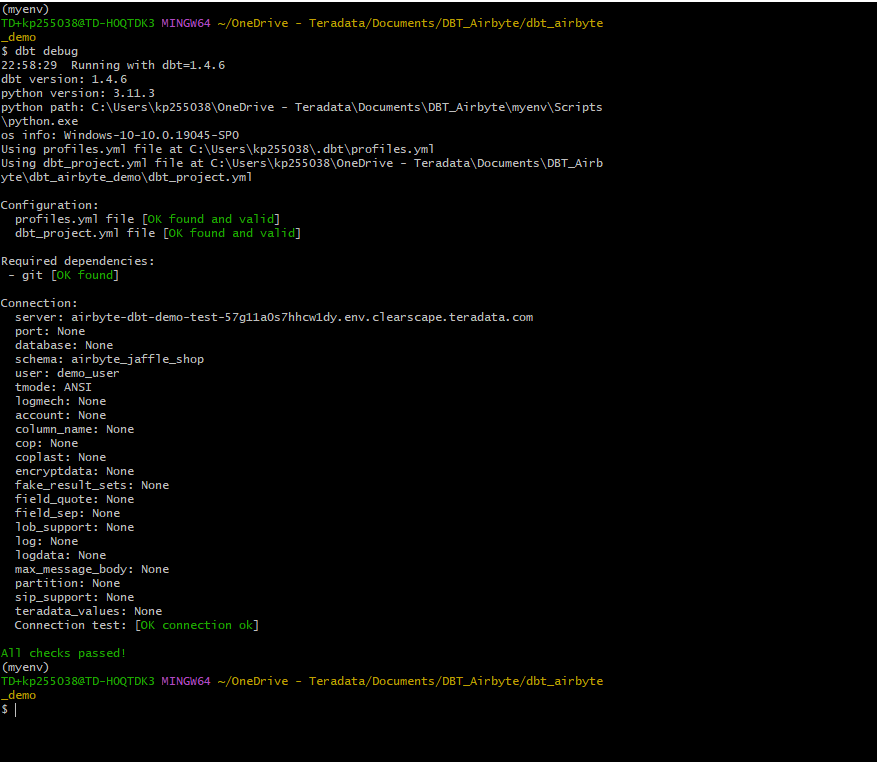
El proyecto dbt de Jaffle Shop
jaffle_shop es un restaurante ficticio que toma pedidos en línea. Los datos de este negocio constan de tablas para customers, orders y payments que siguen el diagrama de relaciones entre entidades a continuación:

Los datos en el sistema de origen están normalizados. A continuación se presenta un modelo dimensional basado en los mismos datos, más adecuado para herramientas de análisis:

Transformaciones de dbt
El proyecto dbt completo que abarca las transformaciones detalladas a continuación se encuentra en Proyecto Jaffle con Airbyte.
El proyecto dbt de referencia realiza dos tipos de transformaciones.
- Primero, transforma los datos sin procesar (en formato JSON), cargados desde Google Sheets a través de Airbyte, en vistas provisionales. En esta etapa los datos están normalizados.
- A continuación, transforma las vistas normalizadas en un modelo dimensional listo para análisis.
El siguiente diagrama muestra los pasos de transformación en Teradata Vantage usando dbt:

Como en todos los proyectos dbt, la carpeta models contiene los modelos de datos que el proyecto materializa como tablas, o vistas, según las configuraciones correspondientes en el nivel de proyecto o modelo individual.
Los modelos se pueden organizar en diferentes carpetas según su propósito en la organización del almacén/lago de datos. Los diseños de carpetas comunes incluyen una carpeta para staging, una carpeta para core y una carpeta para marts. Esta estructura se puede simplificar sin afectar el funcionamiento de dbt.
Modelos provisionales
En el tutorial de Jaffle Shop sobre dbt original, los datos del proyecto se cargan desde archivos csv ubicados en la carpeta ./data mediante el comando seed de dbt. El comando seed se usa habitualmente para cargar datos de tablas; sin embargo, este comando no está diseñado para realizar la carga de datos.
En esta demostración, asumimos una configuración más típica en la que se utilizó una herramienta diseñada para la carga de datos, Airbyte, para cargar datos en el almacén/lago de datos. Sin embargo, los datos cargados a través de Airbyte se representan como cadenas JSON sin formato. A partir de estos datos sin procesar, vamos a crear vistas de preparación normalizadas. Realizamos esta tarea a través de los siguientes modelos provisionales.
- El modelo
stg_customerscrea la vista de almacenamiento provisional normalizada paracustomersa partir de la tabla_airbyte_raw_customers. - El modelo
stg_orderscrea la vista normalizada paraordersa partir de la tabla_airbyte_raw_orders - El modelo
stg_paymentscrea la vista normalizada parapaymentsa partir de la tabla_airbyte_raw_payments.
Como el método de extracción de cadenas JSON sigue siendo coherente en todos los modelos de preparación, proporcionaremos una explicación detallada de las transformaciones utilizando solo uno de estos modelos como ejemplo.
A continuación se muestra un ejemplo de transformación de datos JSON sin procesar en una vista a través del modelo stg_orders.sql:
- En este modelo, la fuente se define como la tabla sin formato
_airbyte_raw_orders. - Las columnas de esta tabla sin procesar contienen metadatos y los datos ingeridos reales. La columna de datos se llama
_airbyte_data. - Esta columna es de tipo Teradata JSON. Este tipo admite el método JSONExtractValue para recuperar valores escalares del objeto JSON.
- En este modelo recuperamos cada uno de los atributos de interés y agregamos alias significativos para materializar una vista.
Modelos dimensionales (marts)
La construcción de un modelo dimensional es un proceso de dos pasos:
- Primero, tomamos las vistas normalizadas en
stg_orders,stg_customers,stg_paymentsy construimos tablas de unión intermedias desnormalizadascustomer_orders,order_payments,customer_payments. Encontrará las definiciones de estas tablas en./models/marts/core/intermediate. - En el segundo paso, creamos los modelos
dim_customersyfct_orders. Estas constituyen las tablas del modelo dimensional que queremos exponer a nuestra herramienta de BI. Encontrará las definiciones de estas tablas en./models/marts/core.
Ejecutar las transformaciones
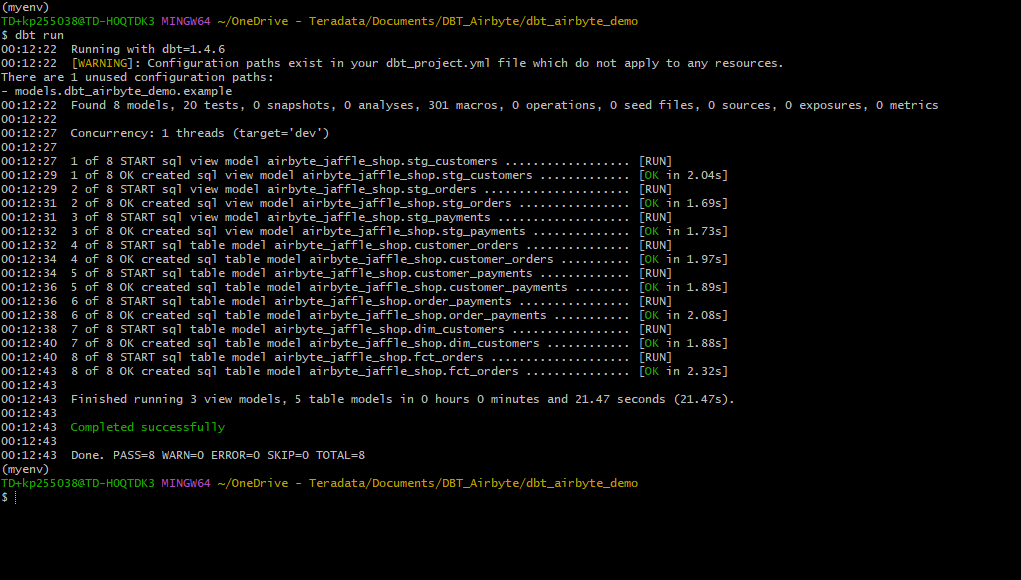
Para ejecutar las transformaciones definidas en el proyecto dbt, ejecutamos:
Obtendrá el estado de cada modelo como se indica a continuación:
Datos de prueba
Para garantizar que los datos en el modelo dimensional sean correctos, dbt nos permite definir y ejecutar pruebas con los datos.
Las pruebas se definen en ./models/marts/core/schema.yml y ./models/staging/schema.yml. Cada columna puede tener varias pruebas configuradas en la clave tests.
- Por ejemplo, esperamos que la columna
fct_orders.order_idcontenga valores únicos y no nulos.
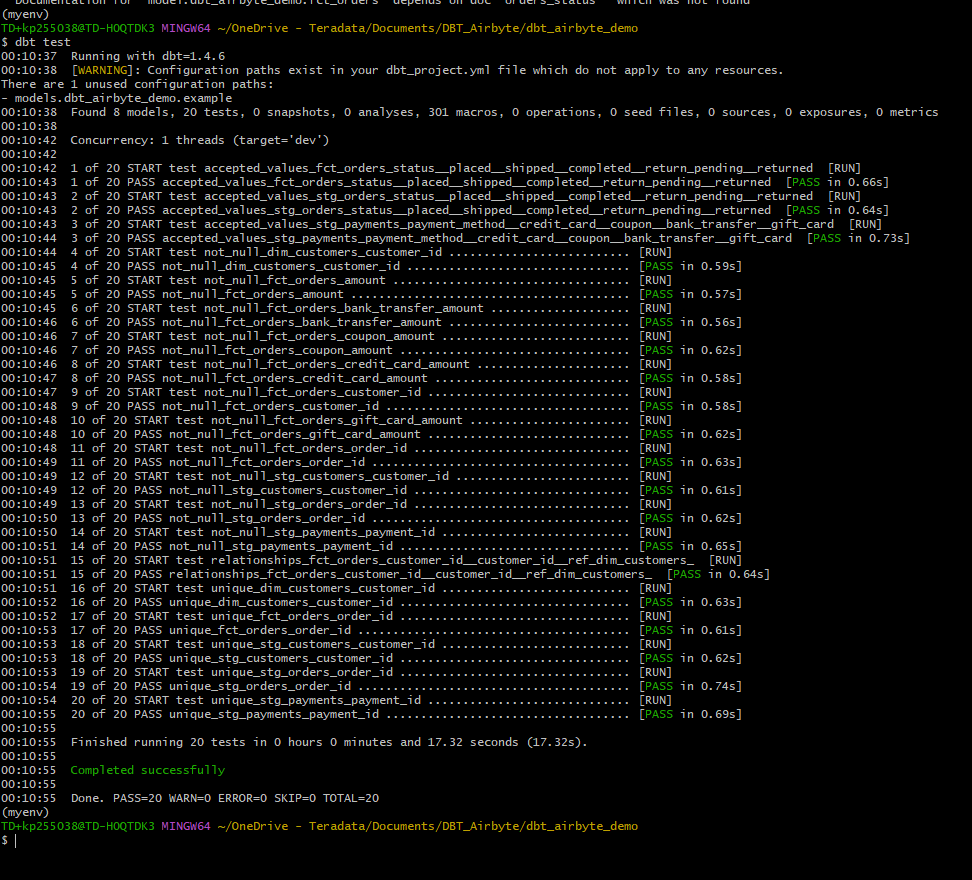
Para validar que los datos en las tablas creadas satisfacen las condiciones de prueba, ejecute:
Si los datos de los modelos satisfacen todos los casos de prueba, el resultado de este comando será el siguiente:
Generar documentación
Nuestro modelo consta de unas pocas tablas. En un escenario con más fuentes de datos y un modelo dimensional más complejo, es muy importante documentar el linaje de datos y cuál es el propósito de cada uno de los modelos intermedios.
Generar este tipo de documentación con dbt es muy sencillo.
Esto generará archivos html en el directorio ./target.
Puede iniciar su propio servidor para explorar la documentación. El siguiente comando iniciará un servidor y abrirá una pestaña del navegador con la página de inicio de los documentos:
Gráfico de linaje
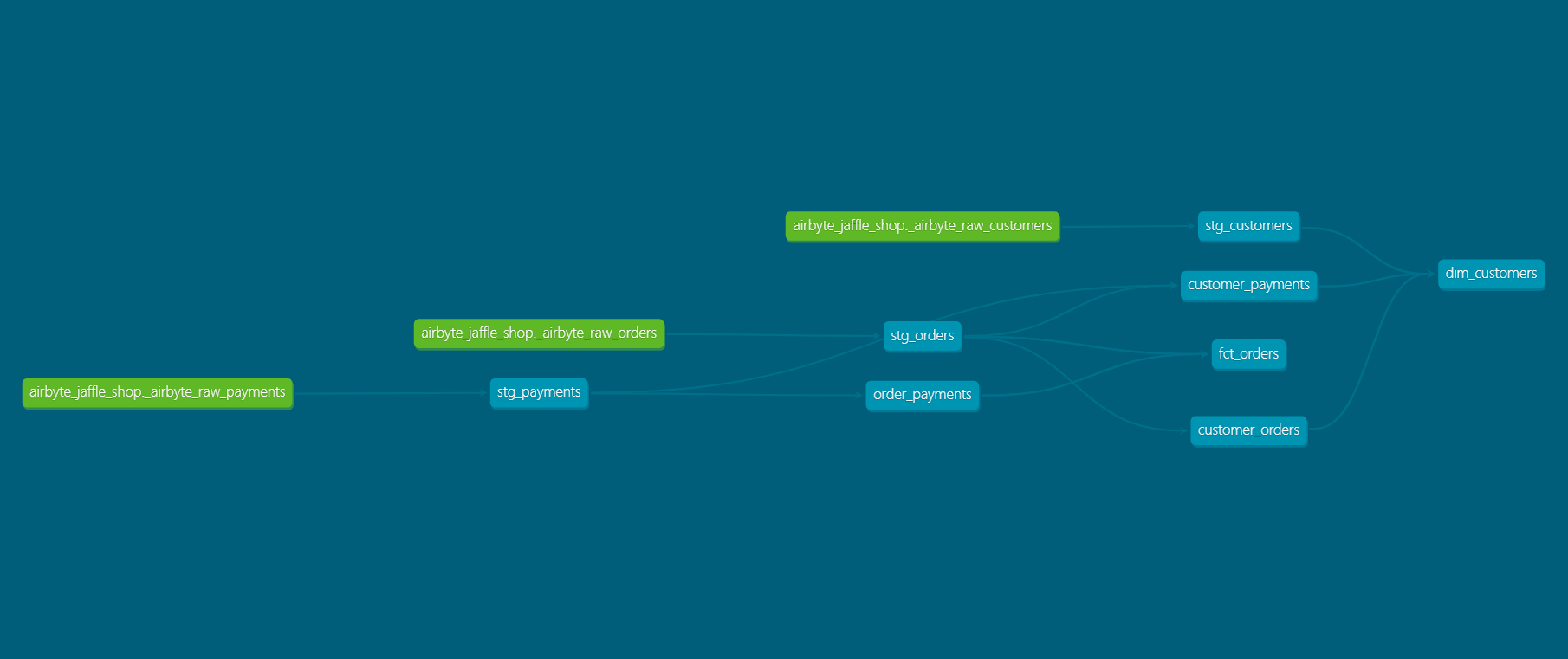
Resumen
Este tutorial demostró cómo usar dbt para transformar datos JSON sin procesar cargados a través de Airbyte en un modelo dimensional en Teradata Vantage. El proyecto de muestra toma datos JSON sin procesar cargados en Teradata Vantage, crea vistas normalizadas y finalmente genera un data mart dimensional. Usamos dbt para transformar JSON en vistas normalizadas y múltiples comandos dbt para crear modelos (dbt run), probar los datos (dbt test) y generar y entregar documentación del modelo (dbt docs generate, dbt docs serve).
Lectura adicional
Si tiene alguna pregunta o necesita más ayuda, visite nuestro foro de la comunidad donde podrá obtener ayuda e interactuar con otros miembros de la comunidad.