Ejecutar demostraciones de Teradata Jupyter Notebook para VantageCloud Lake en Amazon SageMaker
Información general
En este inicio rápido se detalla el proceso para ejecutar las Demostraciones de Jupyter Notebook de Teradata para VantageCloud Lake en Amazon SageMaker, la plataforma IA/ML de AWS.
Prerrequisitos
- Módulos de Teradata para Jupyter (descarga aquí, es necesario registrarse)
- Cuenta de AWS con acceso a S3 y SageMaker
- Acceso a un entorno VantageCloud Lake
Configuración del entorno AWS
En esta sección cubriremos en detalle cada uno de los pasos a continuación:
- Cargar los módulos Teradata para Jupyter en un depósito S3
- Crear un rol de IAM para su instancia de Jupyter notebook
- Crear una configuración de ciclo de vida para su instancia de Jupyter notebook
- Crear una instancia de Jupyter notebook
- Encontrar el CIDR IP de su instancia de Jupyter notebook
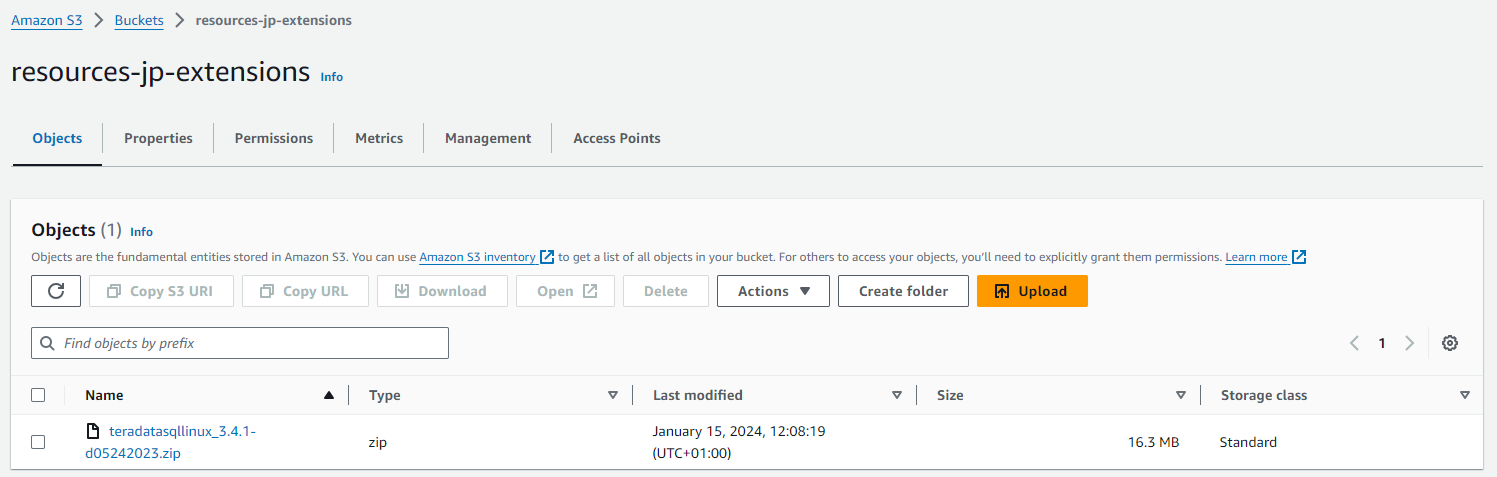
Cargar los módulos Teradata para Jupyter en un depósito S3
- En AWS S3, cree un depósito y tome nota del nombre asignado
- Las opciones predeterminadas son apropiadas para este depósito.
- En el depósito creado, cargue los módulos de Teradata para Jupyter
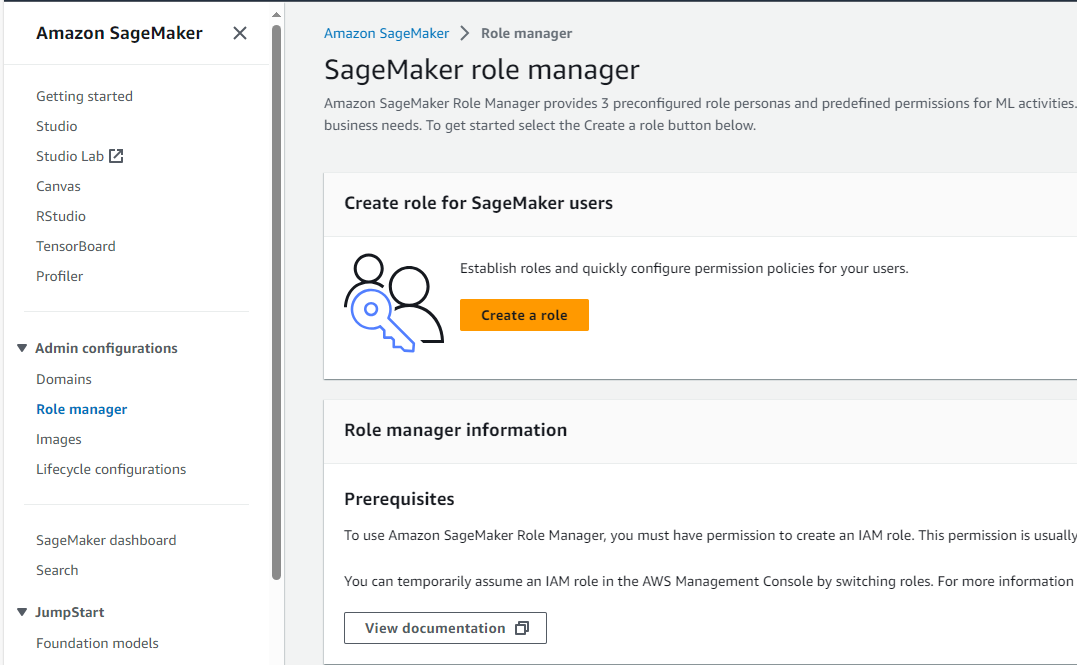
Crear un rol de IAM para su instancia de Jupyter Notebooks
- En SageMaker, navegue hasta el administrador de roles
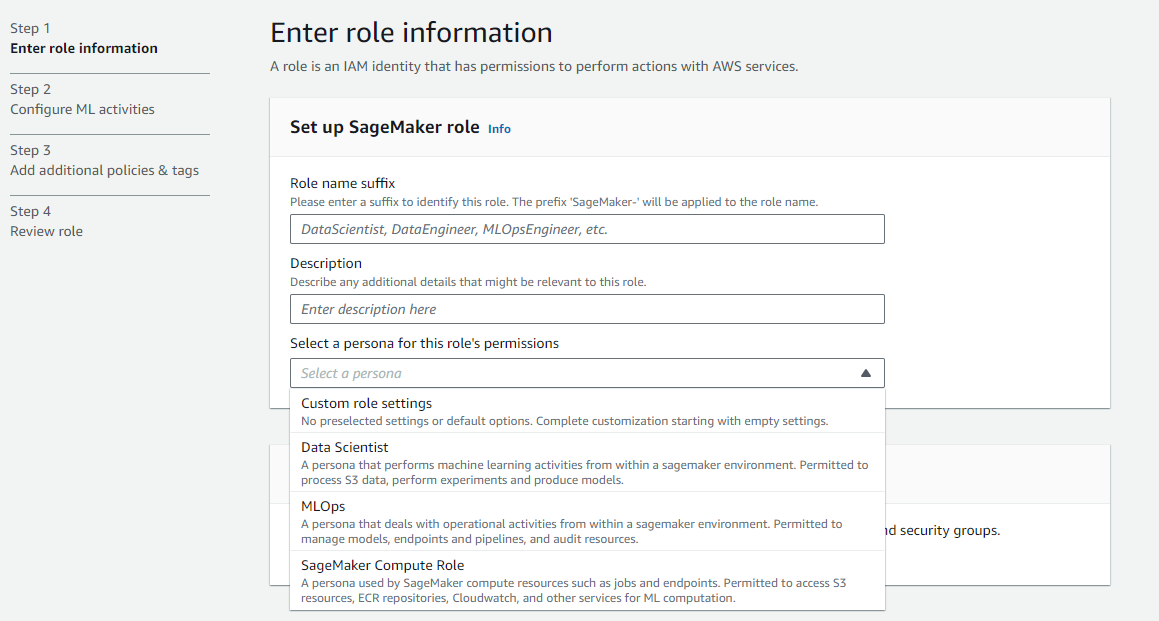
- Crear un nuevo rol (si aún no está definido)
- Para los fines de esta guía, al rol creado se le asigna la persona de científico de datos
- En la configuración, es apropiado mantener los valores predeterminados
- En la pantalla correspondiente, defina el depósito donde cargó los módulos de Teradata Jupyter
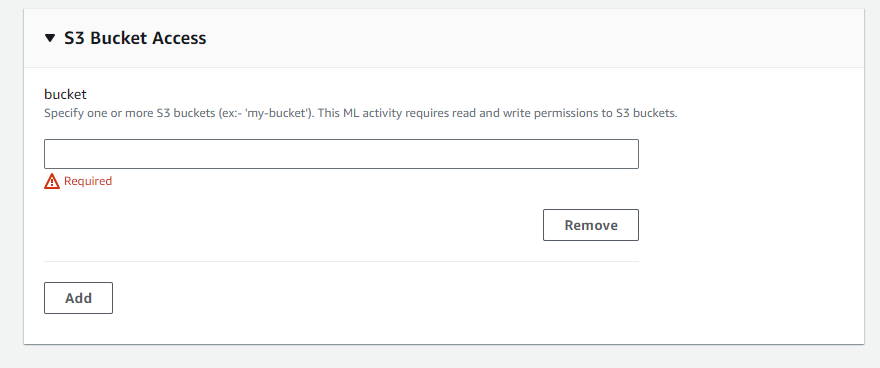
- En la siguiente configuración agregamos las políticas correspondientes para el acceso al depósito S3
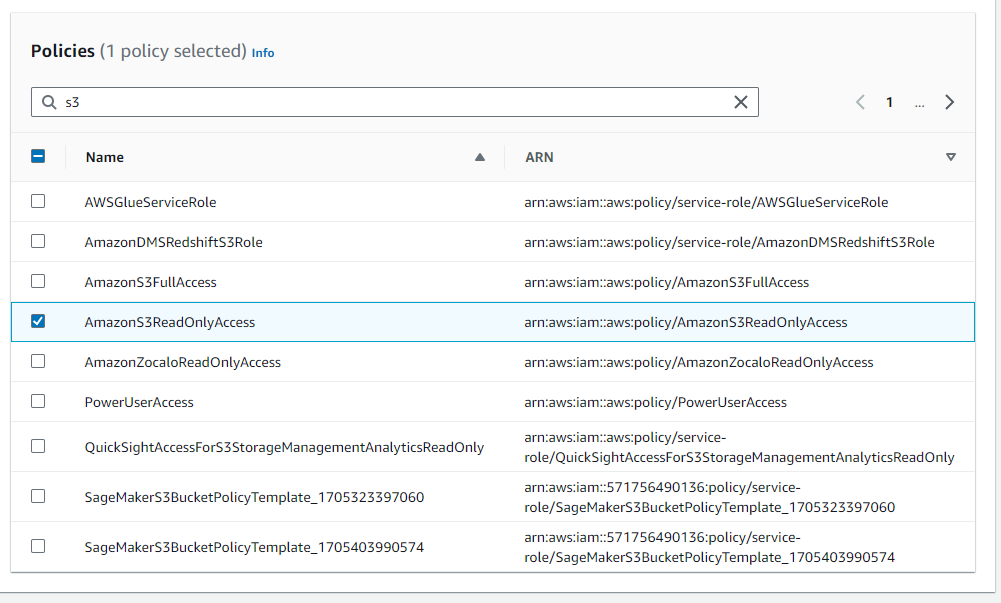
Crear una configuración de ciclo de vida para su instancia de Jupyter Notebooks
-
En SageMaker, navegue hasta configuraciones del ciclo de vida y haga clic en crear
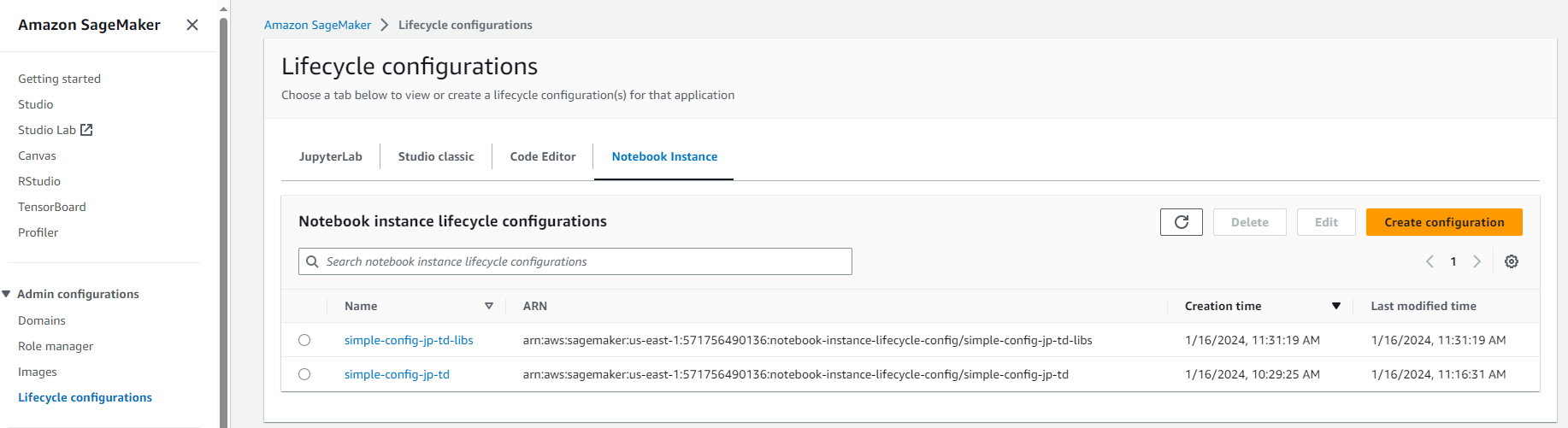
-
Defina una configuración de ciclo de vida con los siguientes scripts * Cuando trabaje desde un entorno Windows, recomendamos copiar los scripts en el editor de configuración del ciclo de vida línea por línea. Presione 'Entrar' después de cada línea directamente en el editor para evitar problemas de copia. Este enfoque ayuda a evitar errores de retorno de carro que pueden ocurrir debido a diferencias de codificación entre Windows y Linux. Estos errores a menudo se manifiestan como "/bin/bash^M: bad interpreter" y pueden interrumpir la ejecución del script.
-
Al crear un script:
-
Al iniciar el script (en este script, sustituya el nombre de su depósito y confirme la versión de los módulos de Jupyter)
-
Crear una instancia de Jupyter Notebooks
-
En SageMaker, navegue por Notebooks, Instancias de Notebook, cree una instancia de Notebook
-
Elija un nombre para su instancia de notebook, defina el tamaño (para demostraciones, la instancia más pequeña disponible es suficiente)
-
Haga clic en configuraciones adicionales y asigne la configuración del ciclo de vida creada recientemente
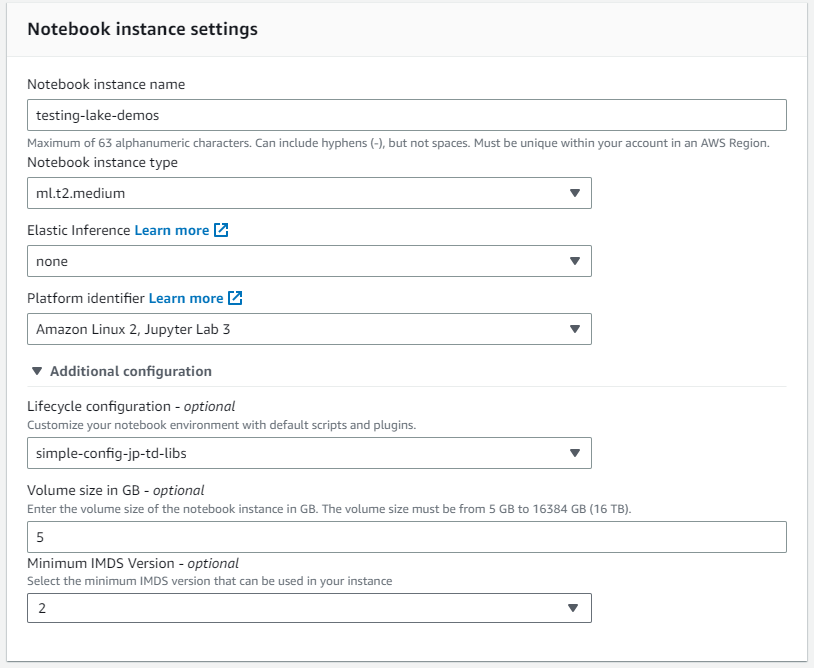
-
Haga clic en configuraciones adicionales y asigne la configuración del ciclo de vida creada recientemente
-
Asigne el rol de IAM creado recientemente a la instancia del cuaderno
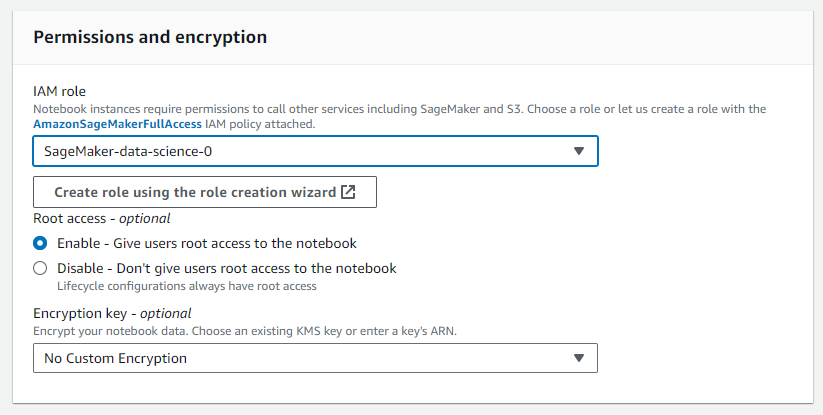
-
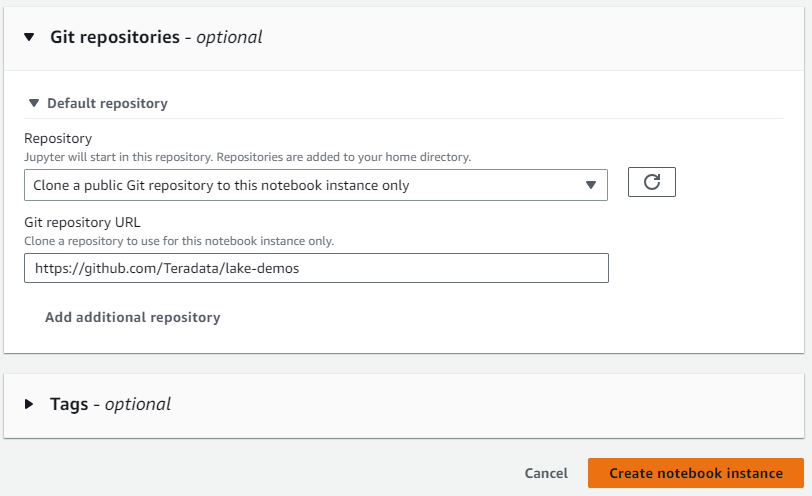
Pegue el enlace https://github.com/Teradata/lake-demos como repositorio de GitHub predeterminado para la instancia del cuaderno
Encontrar el CIDR IP de su instancia de Jupyter Notebooks
-
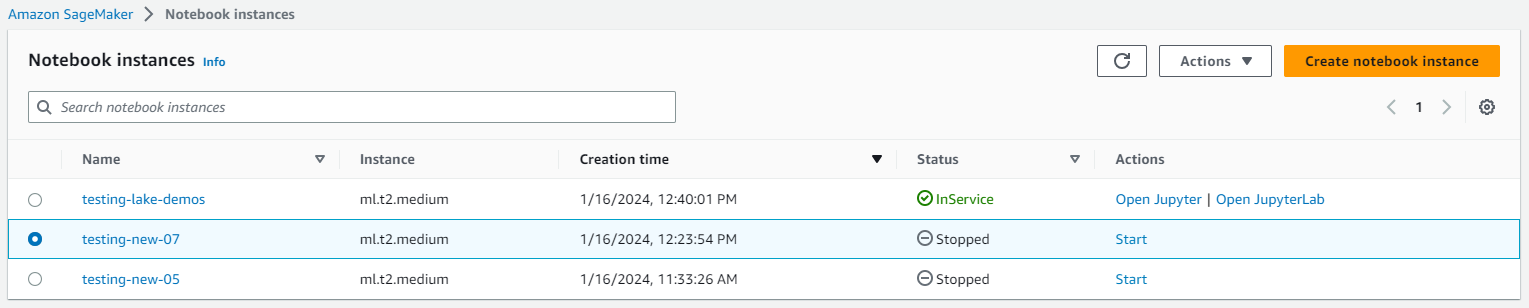
Una vez que la instancia se esté ejecutando, haga clic en abrir JupyterLab

-
En JupyterLab, abra un cuaderno con un kernel de Python y ejecute el siguiente comando para encontrar la dirección IP de la instancia del cuaderno. ** Incluiremos esta IP en la lista blanca de su entorno VantageCloud Lake para permitir la conexión. ** Esto es para los fines de esta guía y las demostraciones de cuadernos. Para entornos de producción, es posible que sea necesario configurar e incluir en la lista blanca una configuración de VPC, subredes y grupos de seguridad.
Configuración de VantageCloud Lake
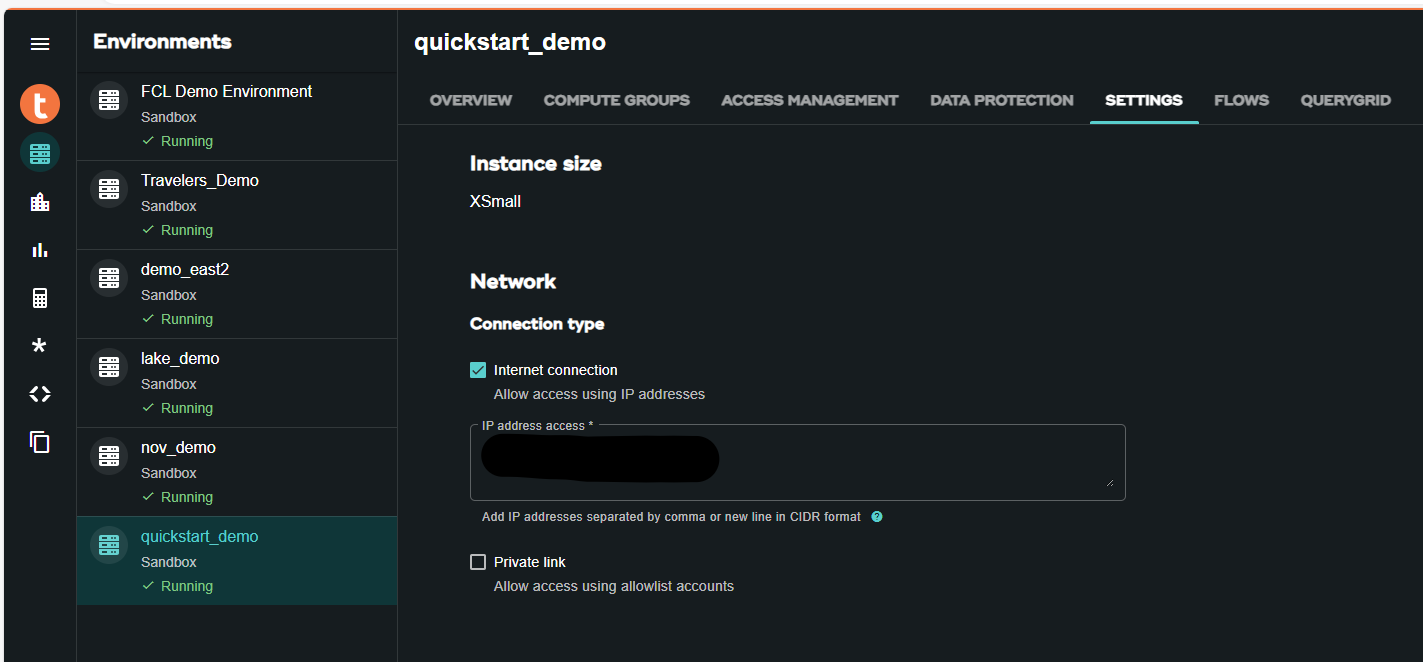
- En el entorno VantageCloud Lake, en configuración, agregue la IP de su instancia de notebook
Demostraciones de Jupyter Notebook para VantageCloud Lake
Configuraciones
-
El archivo vars.json del archivo debe editarse para que coincida con la configuración de su entorno VantageCloud Lake
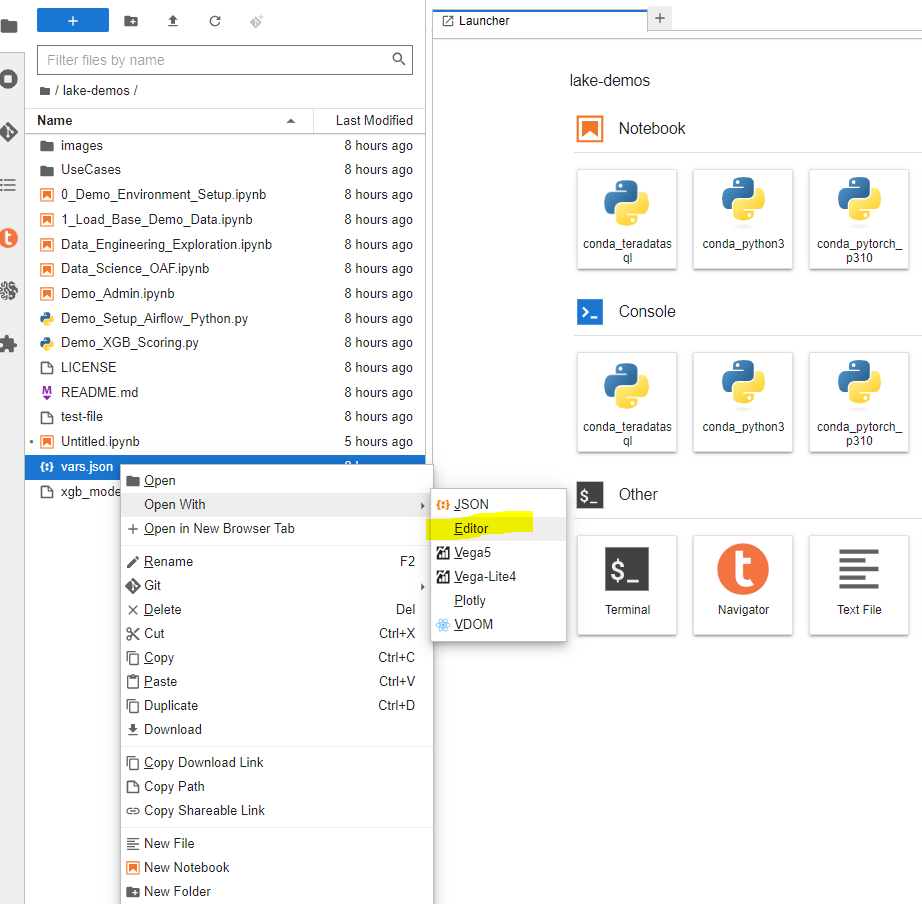
-
Específicamente se deben agregar los siguientes valores
Variable Valor "host" Valor de IP pública de su entorno VantageCloud Lake "UES_URI" Análisis abierto desde su entorno VantageCloud Lake "dbc" La contraseña maestra de su entorno VantageCloud Lake infoRecuerde cambiar todas las contraseñas en el archivo vars.json.
-
Verá que en el archivo vars.json de muestra, las contraseñas de todos los usuarios están predeterminadas en "password", esto es solo para fines ilustrativos, debe cambiar todos estos campos de contraseña a contraseñas seguras, protegerlas según sea necesario y seguir otras prácticas recomendadas de gestión de contraseñas.
Ejecutar demostraciones
Abra y ejecute todas las celdas de 0_Demo_Environment_Setup.ipynb para configurar su entorno. Seguido de 1_Demo_Setup_Base_Data.ipynb para cargar los datos base necesarios para las demostracion.
Para obtener más información sobre los cuadernos de demostración, vaya a la página Demostraciones de Teradata Lake en GitHub.
Resumen
En este inicio rápido, aprendimos cómo ejecutar demostraciones de Jupyter notebooks para VantageCloud Lake en Amazon SageMaker.