データベース分析関数を使用して Vantage で ML モデルをトレーニングする
概要
機械学習モデルのアイデアをすぐに検証したい場合があります。モデルの種類は決まっています。まだ ML パイプラインで運用化はしたくありません。念頭に置いていた関係が存在するかどうかをテストしたいだけです。また、実稼働環境では、MLops による継続的な再学習が必要ない場合もあります。このような場合は、データベース分析関数を使用して特徴エンジニアリングを行い、さまざまな ML モデルをトレーニングし、モデルにスコアを付け、さまざまなモデル評価関数でモデルを評価できます。
前提条件
Teradata Vantageインスタンスへのアクセス。
Vantage のテストインスタンスが必要な場合は、 https://clearscape.teradata.com で無料でプロビジョニングできます
サンプルデータを読み込む
この例では、 val データベースのサンプル データを使用します。 accounts、[]、 customer、 transactions テーブルを使用します。プロセス中にいくつかのテーブルを作成しますが、 val データベースにテーブルを作成するときに問題が発生する可能性があるため、独自のデータベース td_analytics_functions_demoを作成しましょう。
データベース分析関数を使用するには、データベースに対する CREATE TABLE アクセス権が必要です。
val データベース内の対応するテーブルから、データベース td_analytics_functions_demo に accounts、customer 、および transactions テーブルを作成しましょう。
サンプルデータを理解する
サンプル テーブルを td_analytics_functions_demoにロードしたので、データを調べてみましょう。これは、銀行の顧客 (約 700 行)、口座 (約 1400 行)、取引 (約 77K 行) からなる単純化された架空のデータセットです。これらは、次のように相互に関連しています。
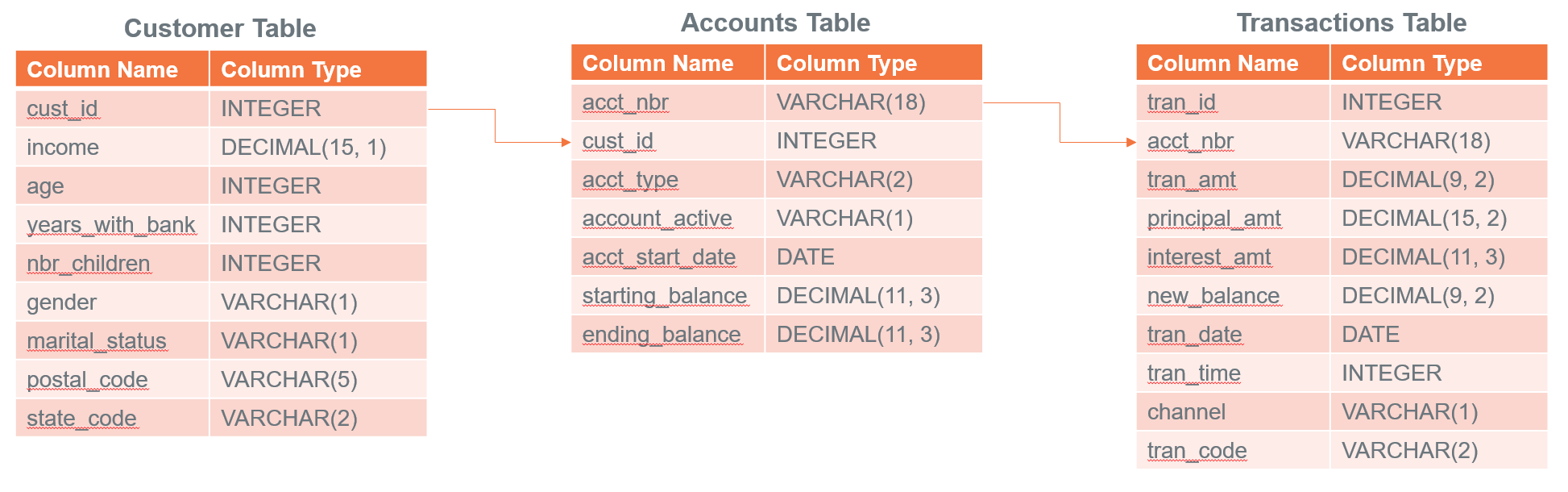
このハウツーの後半では、テーブル内のクレジット カードに関連しないすべての変数に基づいて、銀行顧客のクレジット カードの月平均残高を予測するモデルを構築できるかどうかを検討していきます。
データセットを準備する
3 つの異なるテーブルにデータがあり、それらを結合して機能を作成します。結合テーブルを作成することから始めましょう。
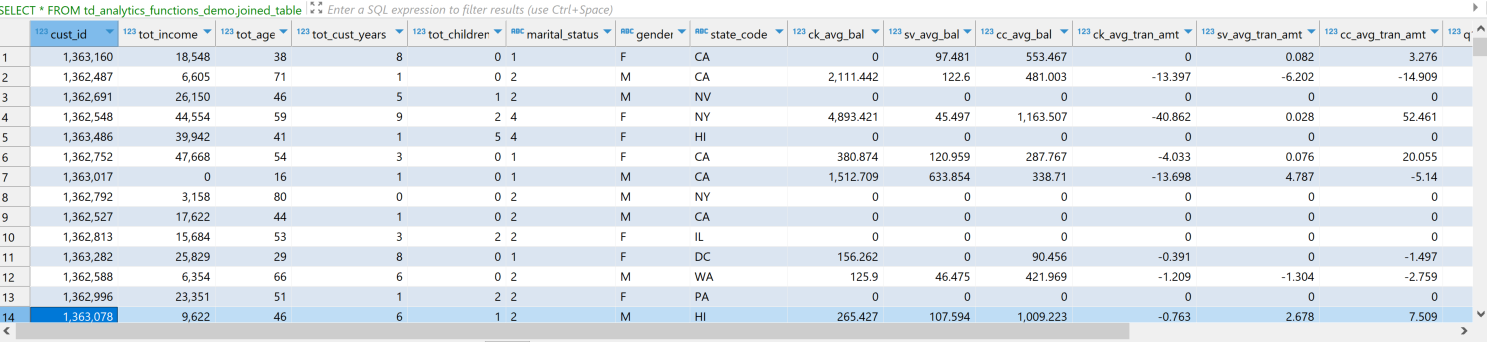
では、データがどのようになっているかを見てみましょう。データセットには、カテゴリと連続の両方の特徴、つまり独立変数があります。この場合、従属変数は cc_avg_bal で、これは顧客の平均クレジットカード残高です。
特徴量エンジニアリング
データを見ると、cc_avg_balを予測するために考慮できる特徴がいくつかあることがわかります。
TD_OneHotEncodingFit
データセットには gender、 marital status 、 state codeなどのカテゴリ特徴がいくつかあるため、データベース分析関数 TD_OneHotEncodingFit を利用してカテゴリをワンホット数値ベクトルにエンコードします。
TD_ScaleFit
データを見ると、 tot_income、 tot_age、 ck_avg_bal などの一部の列には異なる範囲の値があります。勾配降下法などの最適化アルゴリズムでは、収束を高速化し、スケールの一貫性を保ち、モデルのパフォーマンスを向上させるために、値を同じスケールに正規化することが重要です。 TD_ScaleFit 関数を利用して、異なるスケールの値を正規化します。
TD_ColumnTransformer
Teradata のデータベース分析関数は、通常、データ変換のためにペアで動作します。最初のステップは、データの「フィッティング」専用です。その後、2 番目の関数は、フィッティング プロセスから得られたパラメータを使用して、データに対して実際の変換を実行します。 TD_ColumnTransformerは、FIT テーブルを関数に渡し、入力テーブル列を 1 回の操作で変換します。
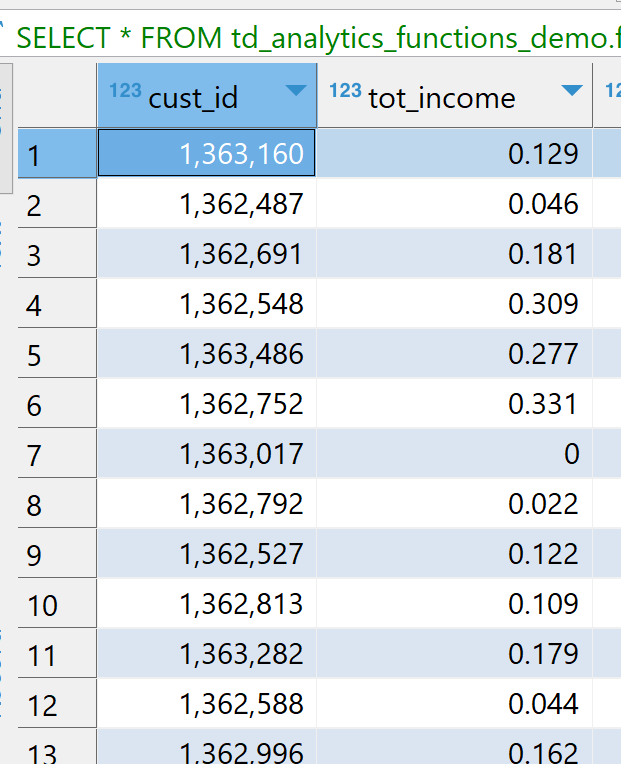
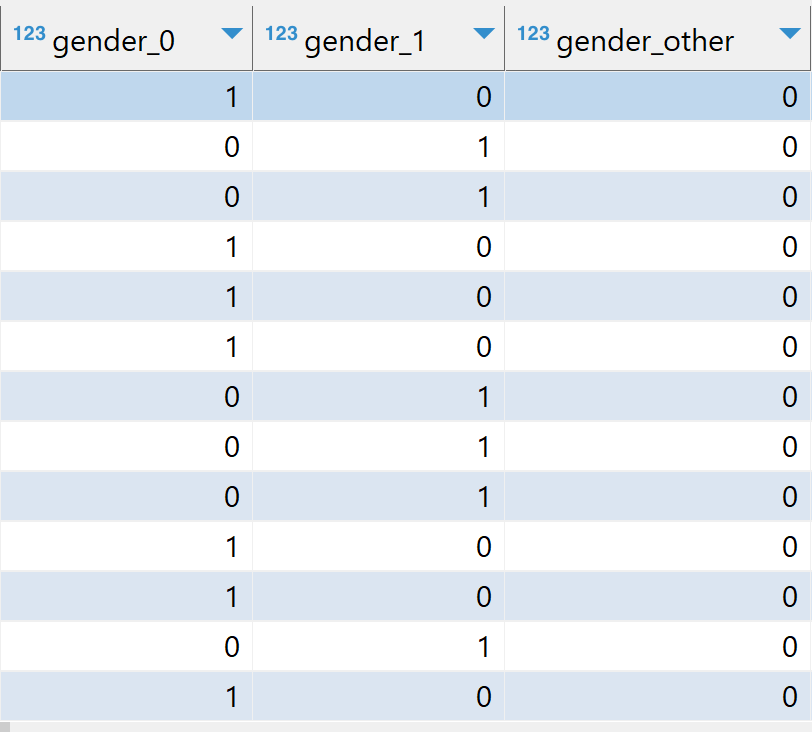
変換を実行すると、以下のイメージに示すように、カテゴリ列がone-hot エンコードされ、数値がスケーリングされたことがわかります。たとえば、tot_income は [0,1] の範囲内にあり、gender は gender_0、gender_1、gender_other にワンホットエンコードされます。
テスト分割のトレーニング
データセットがスケーリングされ、エンコードされた状態で準備できたので、データセットをトレーニング (75%) とテスト (25%) の部分に分割します。Teradata のデータベース分析関数には、データセットを分割するために活用する TD_TrainTestSplit 関数が用意されています。
以下のイメージからわかるように、この関数は新しい列 TD_IsTrainRow を追加します。
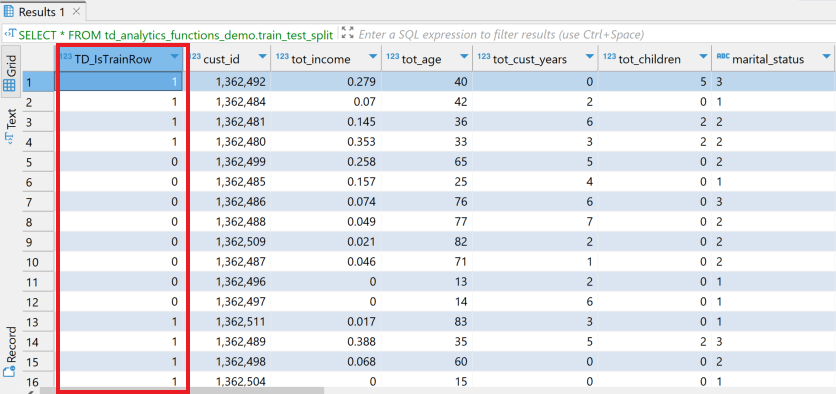
TD_IsTrainRow を使用して、トレーニング用とテスト用の2つのテーブルを作成します。
一般化線形モデルを使用したトレーニング
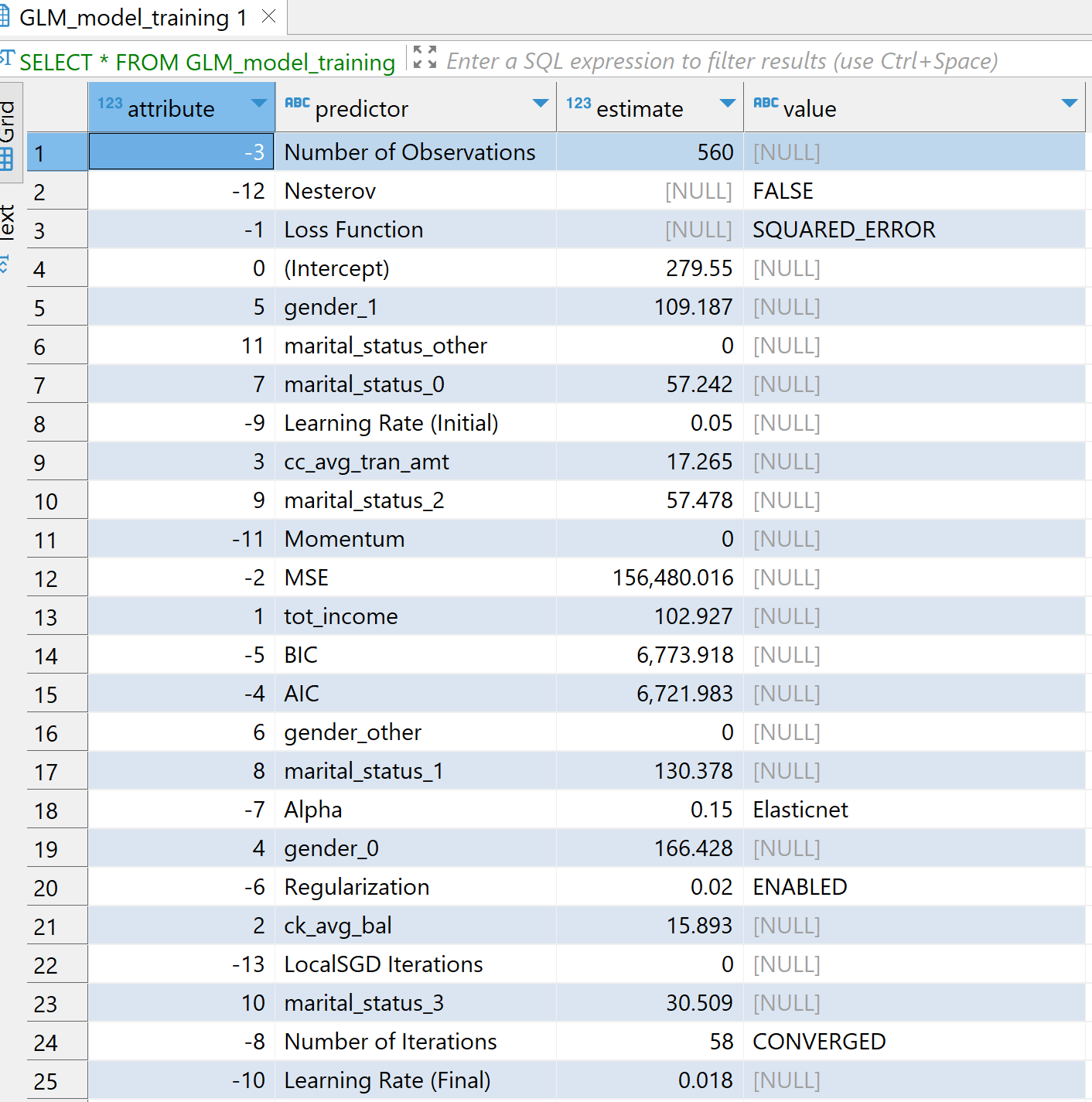
ここで、 TD_GLM データベース分析関数を使用して、トレーニング データセットをトレーニングします。 TD_GLM 関数は、データ セットに対して回帰分析と分類分析を実行する一般化線形モデル (GLM) です。ここでは、 tot_income、 ck_avg_bal、cc_avg_tran_amt、婚姻状況、性別、州のワンホット エンコードされた値など、一連の入力列を使用しました。 cc_avg_bal は従属列または応答列であり、連続しているため回帰問題です。 Family は回帰の場合は Gaussian 、分類の場合は Binomial として使用します。
パラメータ Tolerance は、モデルが反復を停止するために必要な予測精度の最小改善を示し、 MaxIterNum は許容される反復の最大回数を示します。モデルは、最初に満たされた条件でトレーニングを終了します。たとえば、以下の例では、モデルは 58 回の反復後に CONVERGED になります。
テストデータセットのスコアリング
ここで、モデル GLM_model_training を使用して、リンク:TD_GLMPredictデータベース分析関数を使用してテスト データセット testing_table にスコアを付けます。
モデル評価
最後に、スコア付けされた結果に基づいてモデルを評価します。ここでは TD_回帰評価ツール 関数を使用しています。モデルは R2、 RMSE、 F_scoreなどのパラメータに基づいて評価できます。

このハウツーの目的は、機能エンジニアリングを説明することではなく、Vantage でさまざまなデータベース分析関数を活用する方法を示すことです。モデルの結果は最適ではない可能性があり、最適なモデルを作成するプロセスはこの記事の範囲外です。
まとめ
このクイックスタートでは、Teradata データベース分析関数を使用して ML モデルを作成する方法を学習しました。[] データベースの td_analytics_functions_demo 、 customer、accounts、 val``transactions データを使用して独自のデータベース [] を構築しました。 TD_OneHotEncodingFit、[]、 TD_ScaleFit 、 TD_ColumnTransformerを使用して列を変換することにより、特徴エンジニアリングを実行しました。次に、 TD_TrainTestSplit を使用してトレーニング テスト分割を行いました。 TD_GLM モデルを使用してトレーニング データセットをトレーニングし、テスト データセットにスコアを付けました。最後に、 TD_RegressionEvaluator 関数を使用してスコア付けされた結果を評価しました。
さらに詳しく
ご質問がある場合やさらにサポートが必要な場合は、 コミュニティフォーラム にアクセスしてサポートを受けたり、他のコミュニティ メンバーと交流したりしてください。