VantageからSageMakerのAPIを実行する方法
概要
このハウツーは、Amazon SageMaker と Teradata Vantage を統合するのに役立ちます。このガイドで説明するアプローチは、サービスと統合するための多くの潜在的なアプローチの 1 つです。
Amazon SageMaker は、完全に管理された機械学習プラットフォームを提供します。Amazon SageMaker と Teradata には 2 つの使用例があります。
1. データは Teradata Vantage 上に存在し、Amazon SageMaker はモデル定義とその後の��スコアリングの両方に使用されます。このユースケースでは、Teradata は Amazon S3 環境にデータを提供し、Amazon SageMaker がモデル開発の目的でトレーニングおよびテストデータセットを使用できるようにします。さらに、Teradata は Amazon S3 経由でデータを利用できるようにします。このデータは、Amazon SageMaker によるその後のスコアリングに使用されます。このモデルでは、Teradata はデータリポジトリのみです。
2. データは Teradata Vantage 上に存在し、Amazon SageMaker はモデル定義に使用され、Teradata はその後のスコアリングに使用されます。このユースケースでは、Teradata は Amazon S3 環境にデータを提供し、Amazon SageMaker はモデル開発の目的でトレーニングおよびテストデータセットを利用できるようになります。Teradata は、その後の Teradata Vantage によるスコアリングのために、Amazon SageMaker モデルを Teradata テーブルにインポートする必要があります。このモデルでは、Teradata はデータリポジトリおよびスコアリングエンジンです。
このドキュメントでは、最初のユースケースについて説明します。
Amazon SageMaker は、Amazon S3 バケットからトレーニング データとテスト データを使用します。この記事では、Teradata 分析データセットを Amazon S3 バケットにロードする方法について説明します。その後、Amazon SageMaker でデータを使用して機械学習モデルを構築およびトレーニングし、実稼働環境にデプロイすることができます。
前提条件
- Teradata Vantageインスタンスへのアクセス。
注記
Vantage のテストインスタンスが必要な場合は、 https://clearscape.teradata.com で無料でプロビジョニングできます
- Amazon S3 バケットにアクセスし、Amazon SageMaker サービスを使用するための IAM 権限。
- トレーニングデータを保存するための Amazon S3 バケット。
データのロード
Amazon SageMaker は、Amazon S3 バケットからデータをトレーニングします。Vantage から Amazon S3 バケットにトレーニング データをロードする手順は次のとおりです。
1. Amazon SageMaker コンソールにアクセスし、ノートブックインスタンスを作成します。ノートブックインスタンスの作成方法については、 Amazon SageMaker 開発者ガイド を参照してください: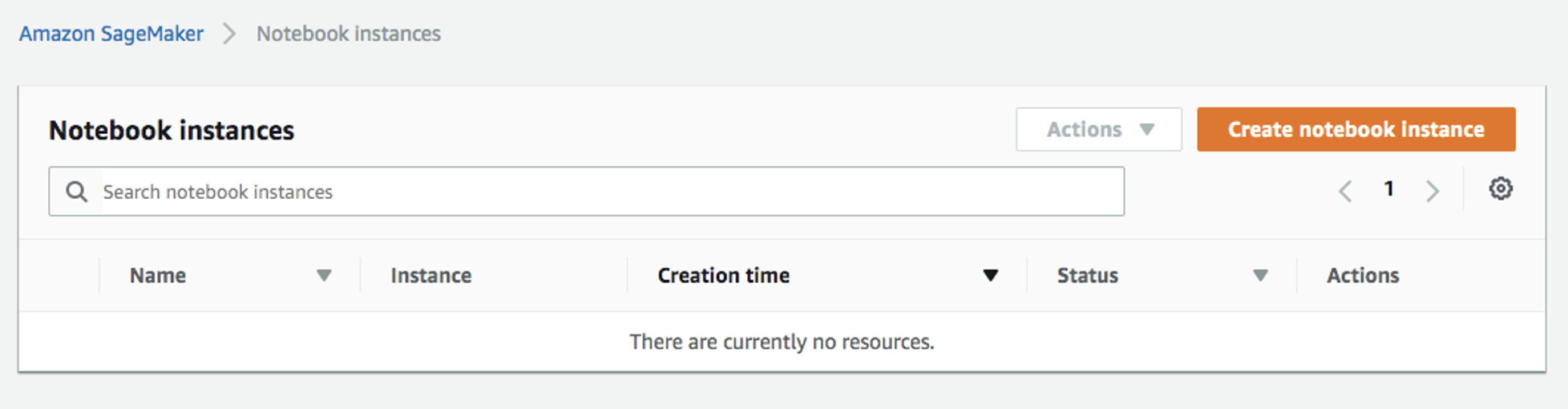
Notebookのインスタンスを開きます。
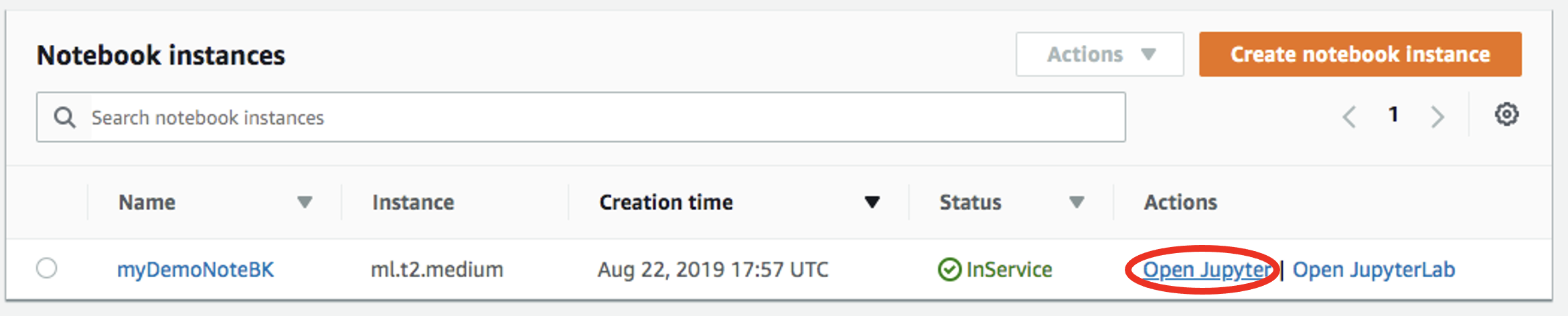
-
New -> conda_python3をクリックして新規ファイルを起動します。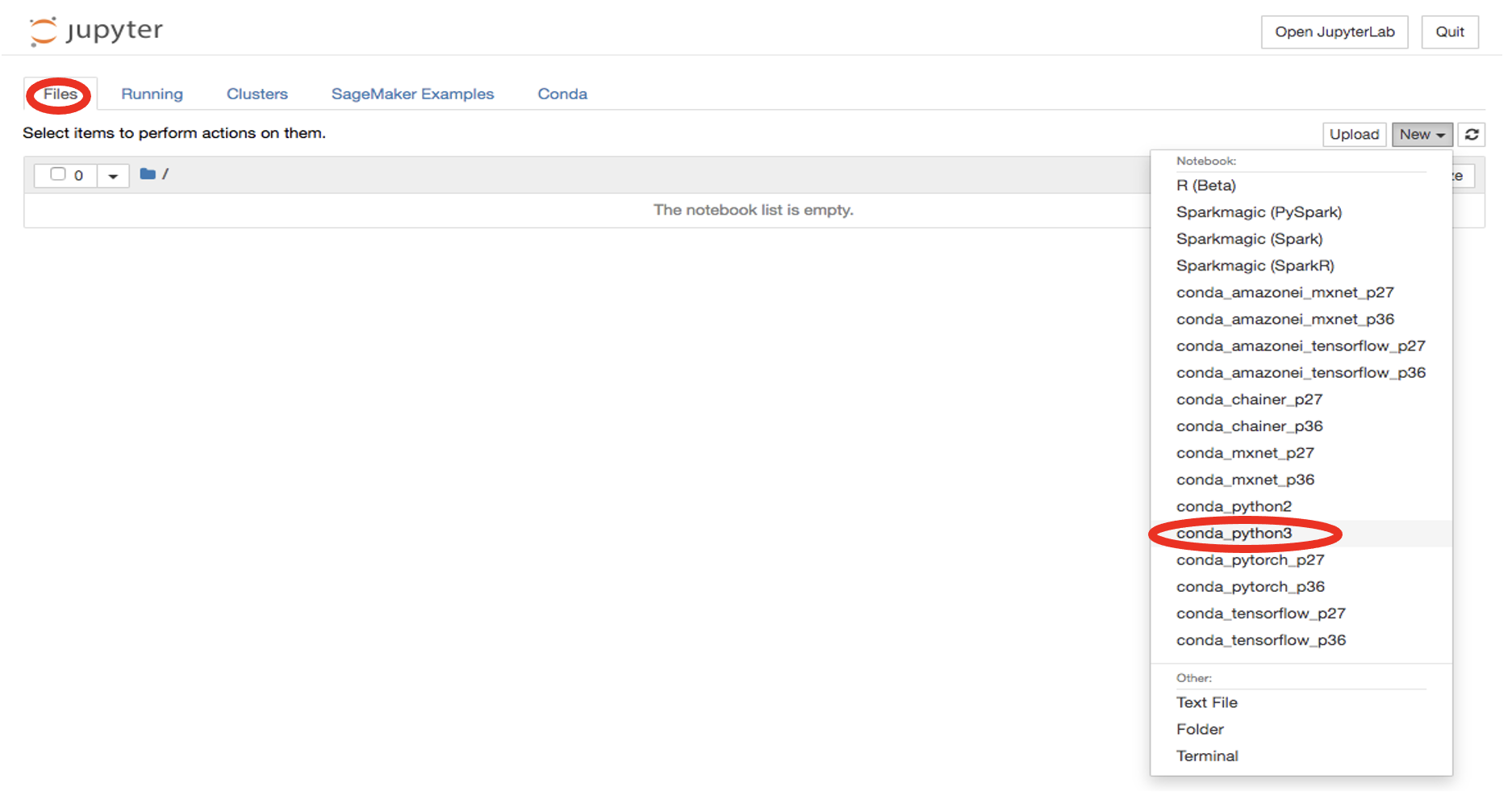
-
Teradata Pythonライブラリをインストールします。
-
新しいセルに追加のライブラリをインポートします。
-
新しいセルで、Teradata Vantage に接続します。
<hostname>、<database user name>、<database password>を Vantage 環境に合わせて置き換えます。 -
TeradataML DataFrame APIを使用して学習用データセットが存在するテーブルからデータを取得します。
-
ローカルファイルにデータを書き込みます。
-
Amazon S3にファイルをアップロードします。
モデルの学習
-
左メニューの
Trainingの下にあるTraining jobsを選択し、Create training jobをクリックします。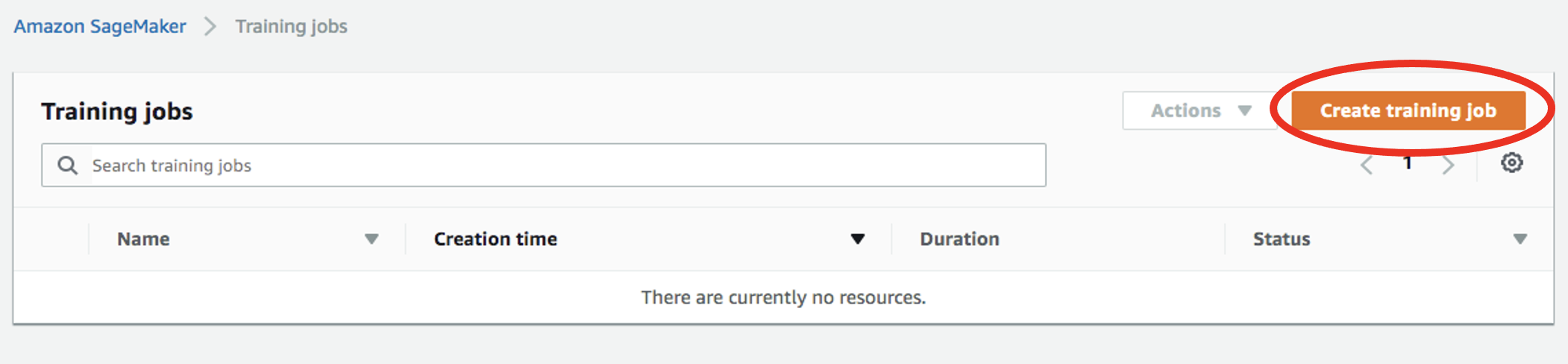
-
Create training jobウィンドウで、IAM ロールのJob name(例:xgboost-bank) とCreate a new roleを入力します。Amazon S3 バケットのAny S3 bucketと [Create roleを選択します。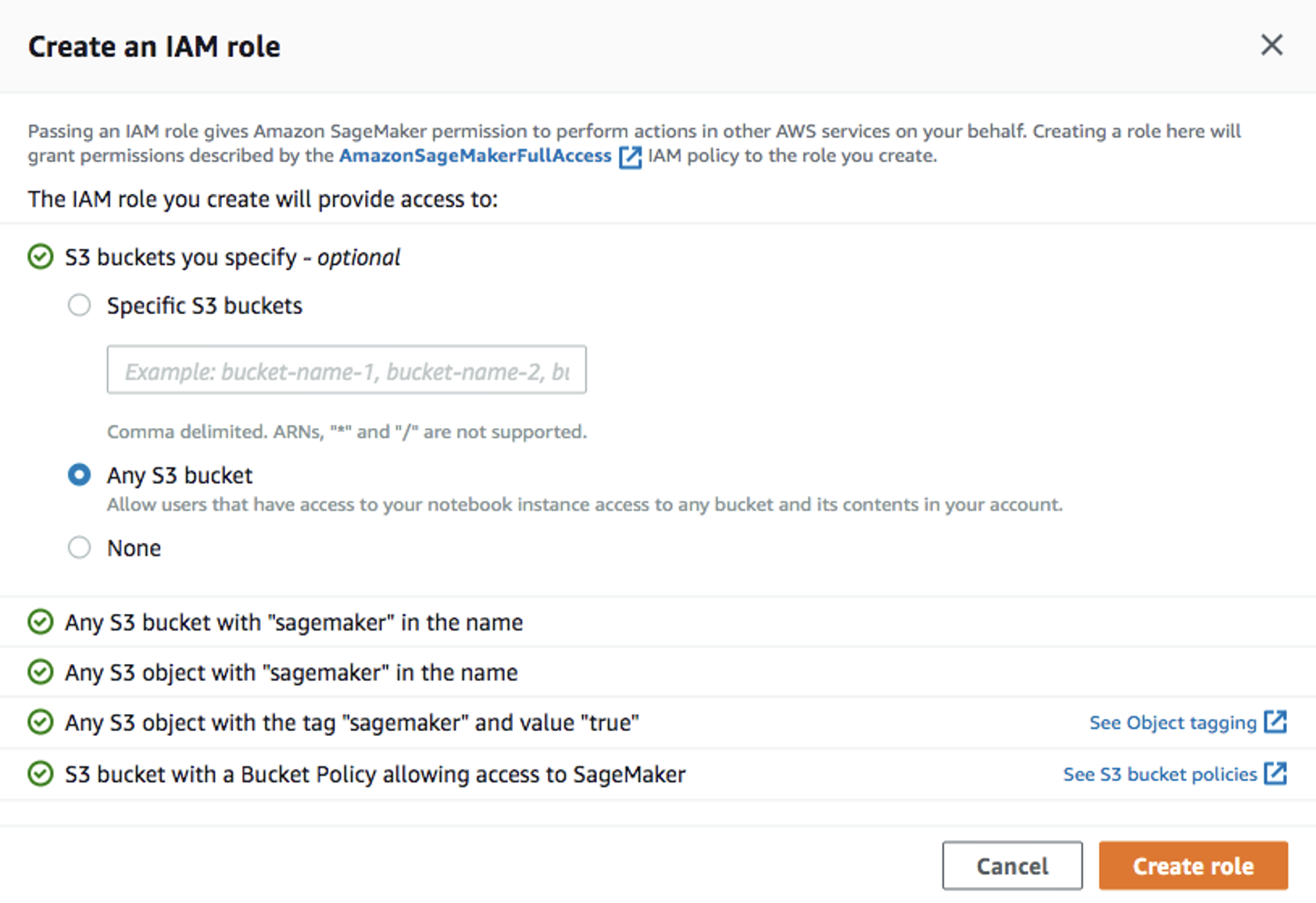
-
Create training jobウィンドウに戻りアルゴリズムとしてXGBoostを使用します。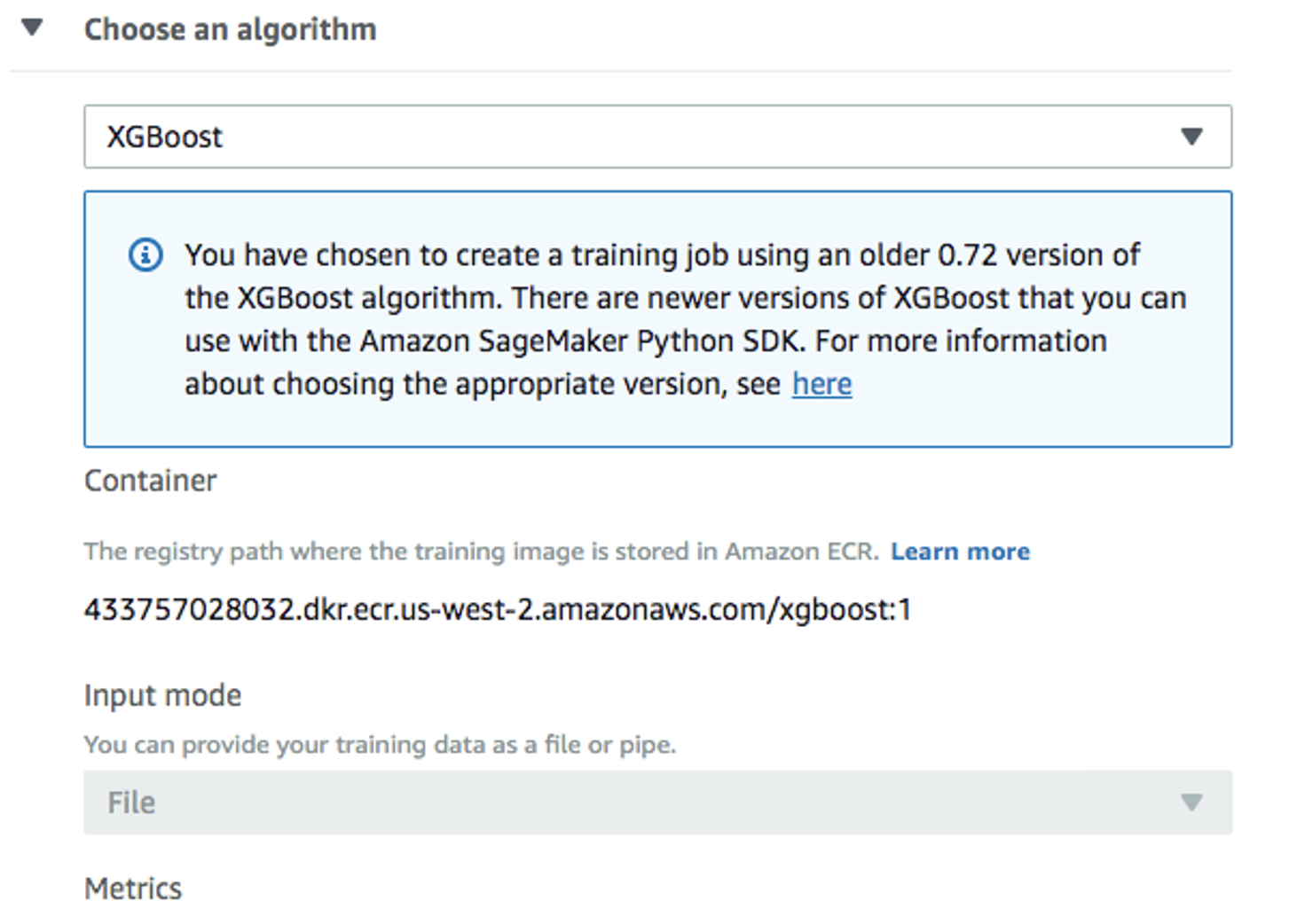
-
デフォルトの
ml.m4.xlargeインスタンス タイプと、インスタンスごとに 30 GB の追加ストレージ ボリュームを使用します。これは短いトレーニング ジョブであり、10 分以上かかることはありません。 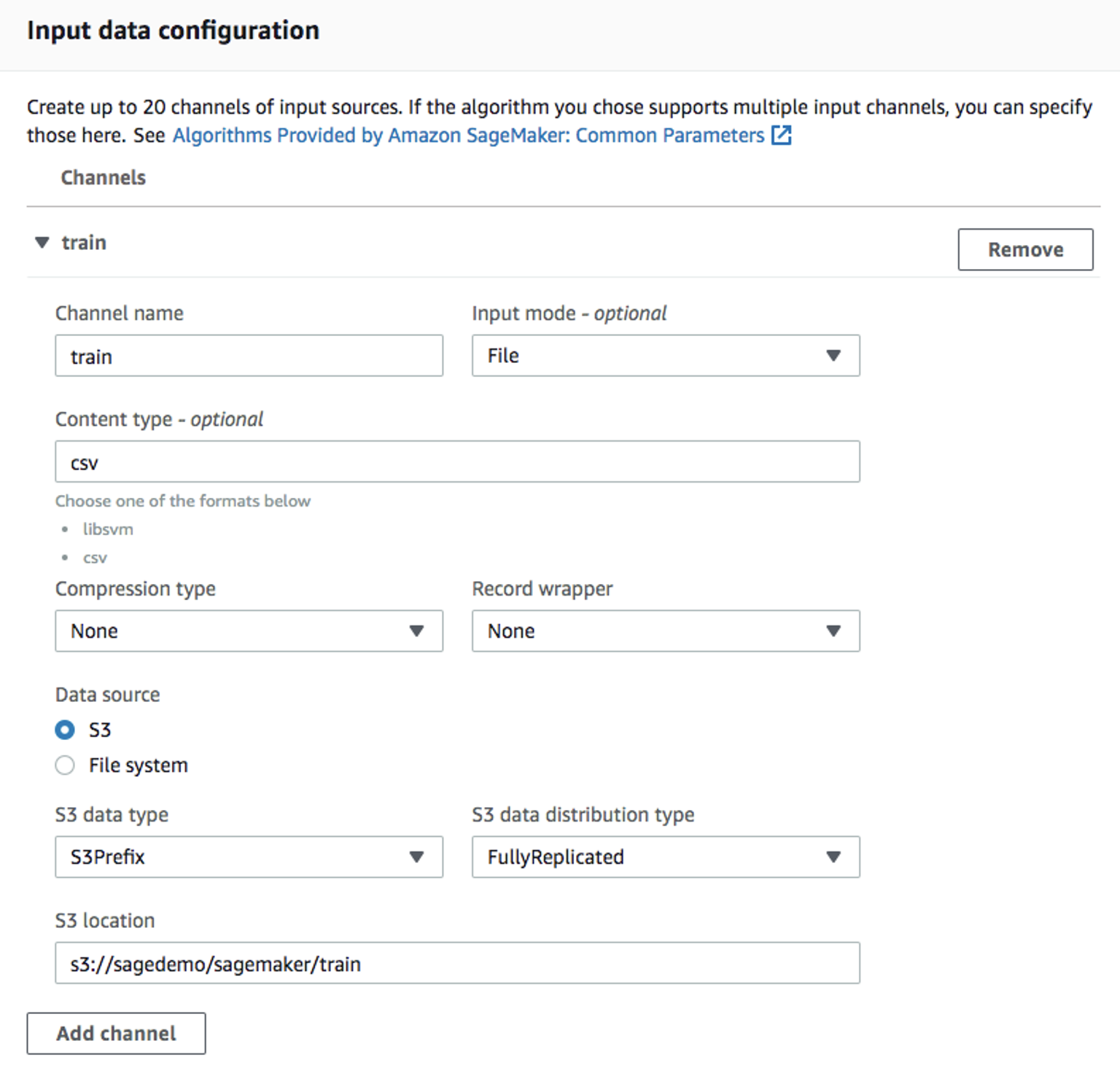
-
Output data configurationには出力データを保存するパスを入力します。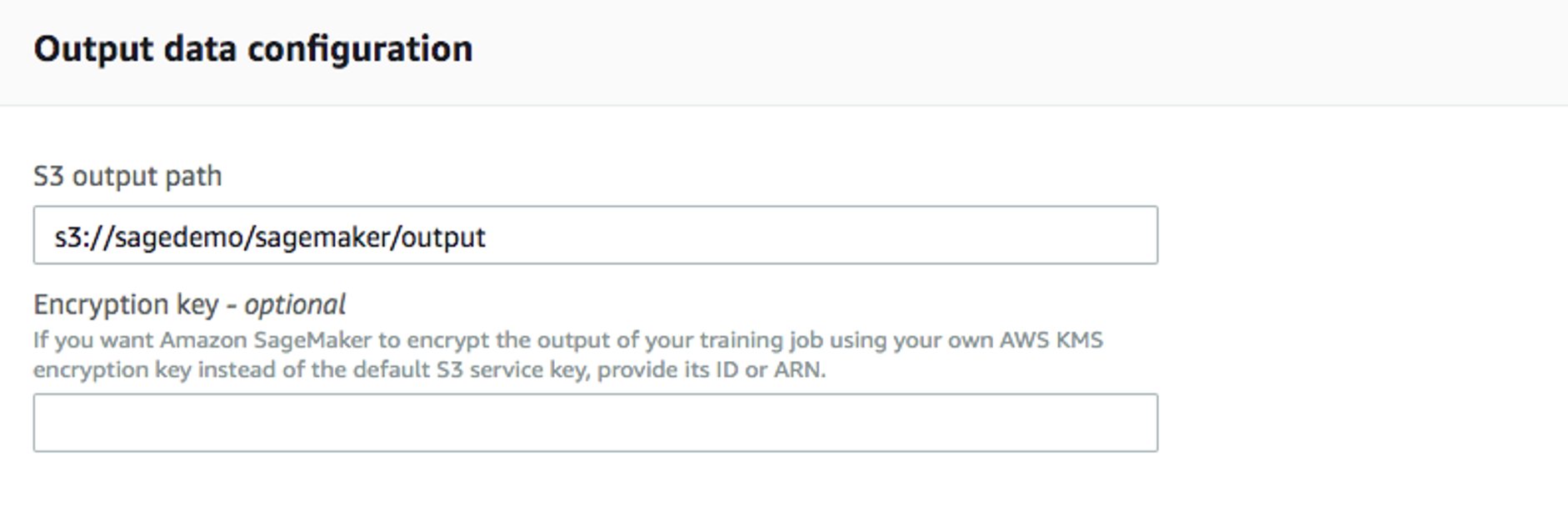
-
その他はすべてデフォルトのままにして、「トレーニングジョブの作成」をクリックします。トレーニングジョブの設定方法の詳細な手順については、[Amazon SageMaker 開発者ガイド](https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-mkt-algo-train.html#sagemaker-mkt-algo-train-console] を参照してください。
トレーニングジョブが作成されるとAmazon SageMakerはMLインスタンスを起動してモデルをトレーニングし、結果のモデル成果物やその他の出力をOutput data configurationデフォルトではpath/<training job name>/output)に格納します。
モデルのデプロイ
モデルを学習させた後、永続的なエンドポイントを使用してモデルをデプロイします。
モデルの作成
- 左パネルから [
Inferenceの下のModelsを選択し、次にCreate modelを選択します。モデル名 (例:xgboost-bank) を入力し、前の手順で作成した IAM ロールを選択します。 2.Container definition 1には433757028032.dkr.ecr.us-west-2.amazonaws.com/xgboost:latestをLocation of inference code imageとして使用します。Location of model artifactsはトレーニングジョブの出力パスです。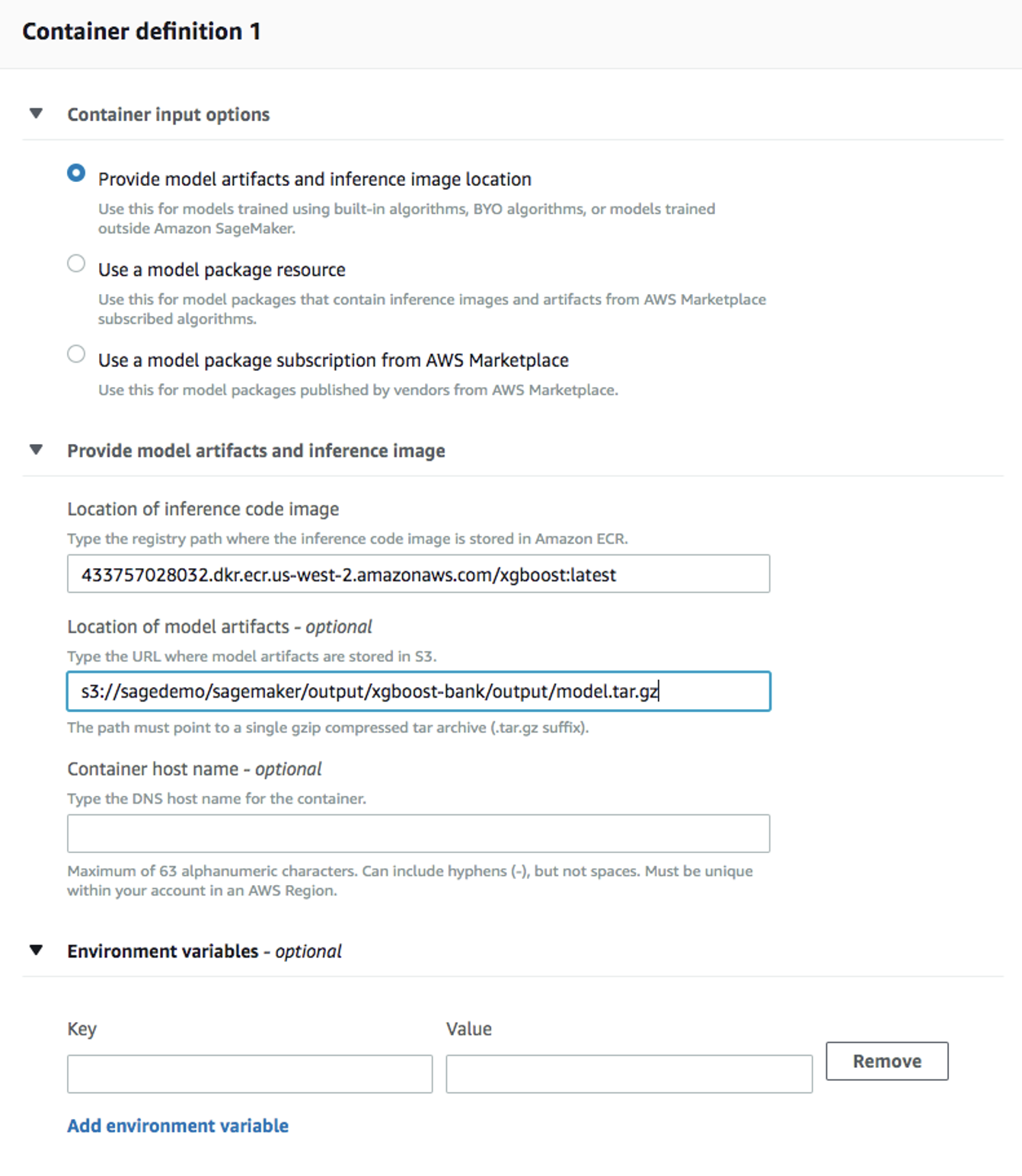
- 他はデフォルトのまま
Create modelします。
エンドポイントコンフィギュレーションの作成
-
作成したモデルを選択し、
Create endpoint configurationをクリックします。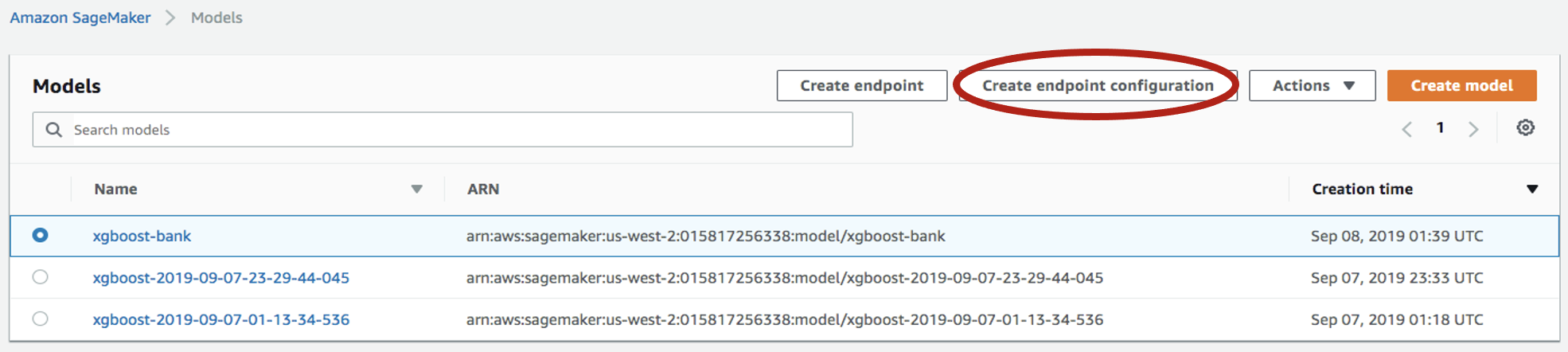
-
名前(例:
xgboost-bank)を入力し、その他はすべてデフォルトを使用します。モデル名とトレーニングジョブは自動的に入力されます。Create endpoint configurationをクリックします。
エンドポイントの作成
-
左パネルから
Inference->Modelsを選択し、再度モデルを選択し、今度はCreate endpointをクリックします。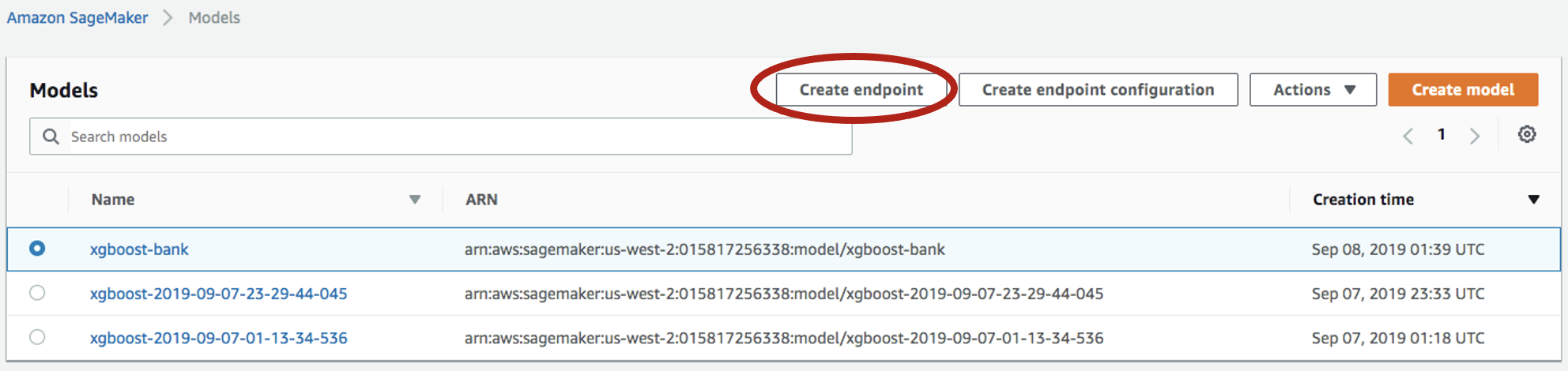
-
名前 (例:
xgboost-bank)を入力し、Use an existing endpoint configurationを選択します。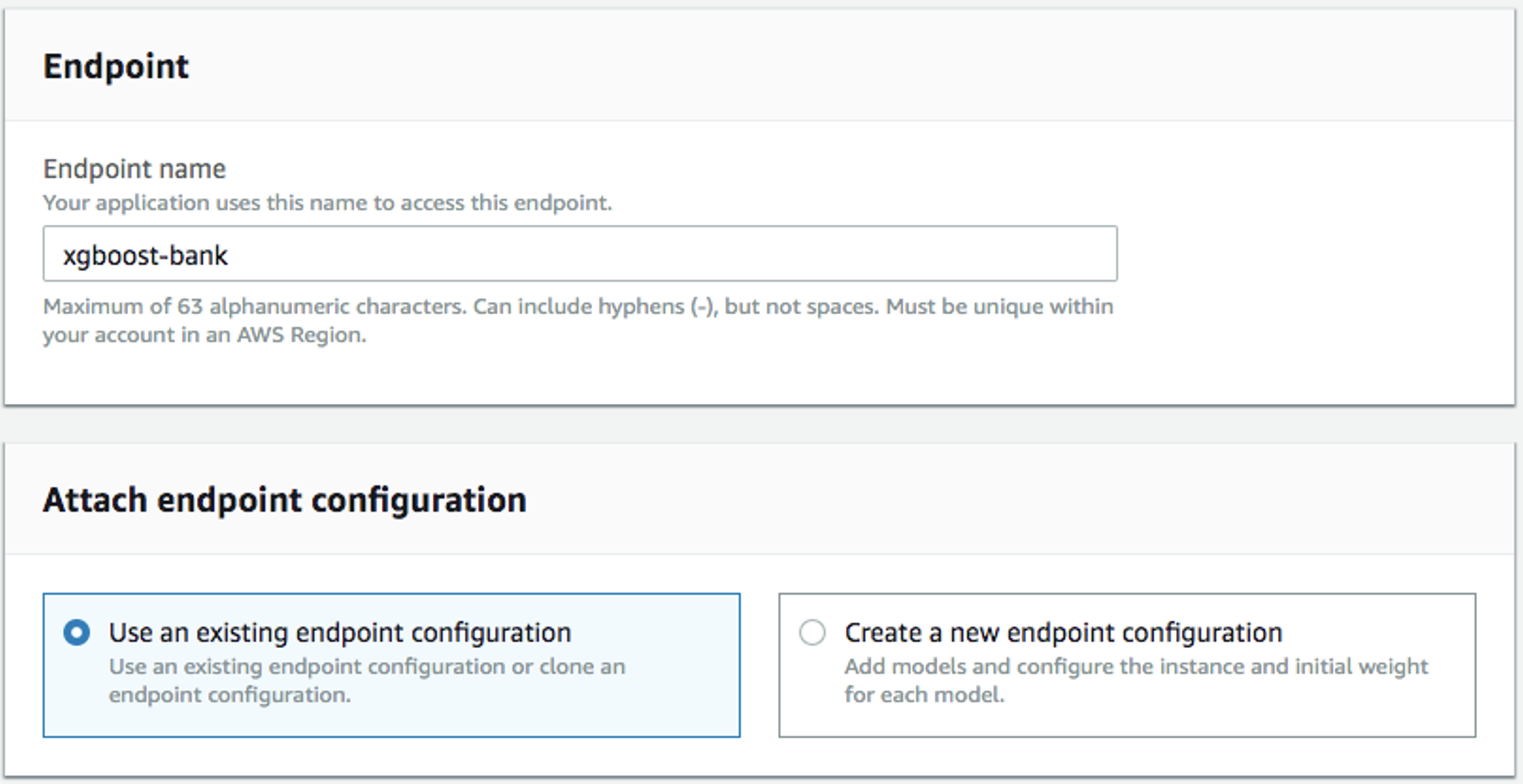
-
前回の手順で作成したエンドポイント構成を選択し
Select endpoint configurationをクリックします。
-
他のすべてをデフォルトのままにして
Create endpointをクリックします。
これでモデルがエンドポイントにデプロイされクライアントアプリケーションから利用できるようになります。
まとめ
このハウツーでは、Vantage からトレーニング データを抽出し、それを使用して Amazon SageMaker でモデルをトレーニングする方法を示しました。このソリューションでは、Jupyter ノートブックを使用して Vantage からデータを抽出し、それを S3 バケットに書き込みました。SageMaker トレーニング ジョブは S3 バケットからデータを読み取り、モデルを作成しました。モデルはサービス エンドポイントとして AWS にデプロイされました。
さらに詳しく
ご質問がある場合やさらにサポートが必要な場合は、 コミュニティフォーラム にアクセスしてサポートを受けたり、他のコミュニティ メンバーと交流したりしてください。