VantageのデータをAzure Machine Learning Studioで使用する方法
概要
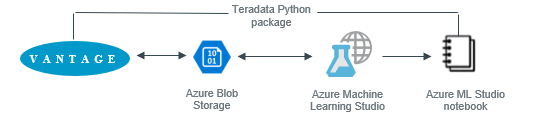
Azure Machine Learning (ML) Studio は、データに基づく予測分析ソリューションを構築、テスト、およびデプロイするために使用できる、共同作業用のドラッグ アンド ドロップ ツールです。ML Studio は、Azure Blob Storage からデータを利用できます。この入門ガイドでは、ML Studio の「組み込み」Jupter Notebook 機能を使用して、Teradata Vantage データ セットを Blob Storage にコピーする方法を説明します。その後、ML Studio でデータを使用して、機械学習モデルを構築およびトレーニングし、運用環境にデプロイできます。
前提条件
- Teradata Vantageインスタンスへのアクセス。
注記
Vantage のテストインスタンスが必要な場合は、 https://clearscape.teradata.com で無料でプロビジョニングできます
- Azureサブスクリプションま�たは作成 無料アカウント
- Azure ML Studio ワークスペース
- (オプション) AdventureWorks DW 2016 データベース (つまり 「モデルの学習」 セクション) をダウンロードします
- 「vTargetMail」 テーブルを SQL Server から Teradata Vantageに復元およびコピーします。
手順
初期設定
-
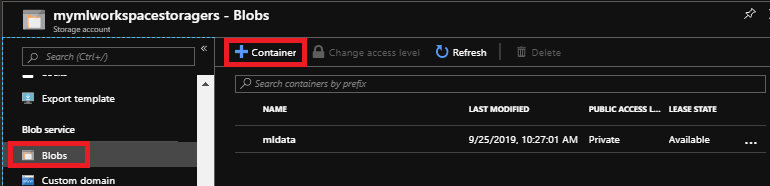
ML Studio ワークスペースの作成中に、現在の利用可能な場所にストレージ アカウントがない場合は、「新しい」ストレージ アカウントを作成し、この入門ガイドの [ Web service plan に DEVTEST Standard を選択する必要がある場合があります。 Azureポータルにログオンし、ストレージ アカウントを開いて、 コンテナ がまだ存在しない場合は作成します。
-
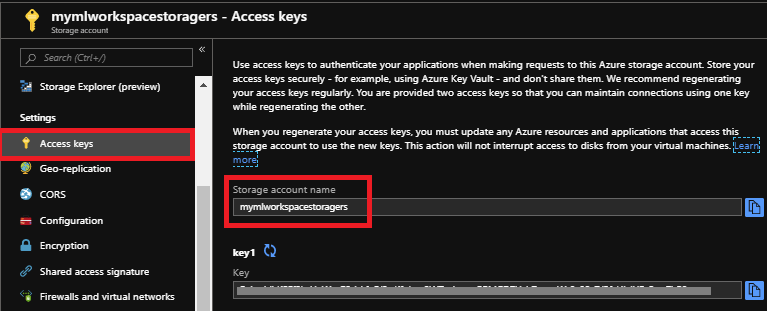
ストレージアカウント名 と キー をメモ帳にコピーし、Python3 NotebookでAzure Blob Storageアカウントにアクセスするために使用します。
-
最後に、Configuration プロパティを開き、'Secure transfer required' を Disabled に設定して、ML Studioインポートデータモジュールがブロブストレージアカウントにアクセスできるようにする。

データのロード
ML Studioにデータを取得するには、まずTeradata VantageからAzure Blob Storageにデータをロードする必要があります。ML Jupyter Notebookを作成し、Teradataに接続してAzure Blob Storageにデータを保存するPythonパッケージをインストールします。
Azureポータルにログオンし、 ML Studioワークスペース と Machine Learning Studioを起動する と サインインに移動します
-
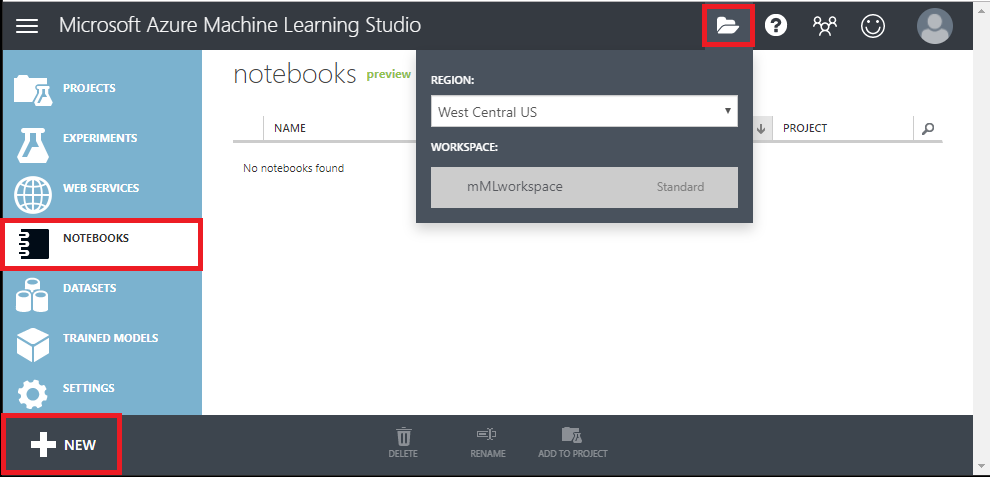
以下の画面が表示されます。 Notebooks をクリックして、正しいリージョン/ワークスペースにいることを確認し、Notebook の Newをクリックします。
-
Python3 を選択し、Notebook インスタンスに 名前を付け ます。
-
Jupyterノートブックインスタンスに 高度な分析のための Teradata Vantage Python パッケージをインストールします。
注記Microsoft Azure ML StudioとTeradata Vantage Pythonパッケージの間の検証は行われていません。
-
Microsoft Azure Storage Blob Client Library for Pythonをインストールします。
-
以下のライブラリをインポートしてください。
-
以下のコマンドを使用して Teradata に接続します。
-
Teradata Python DataFrameモジュールを使用してデータを取得します。
-
Teradata DataFrameをPanda DataFrameに変換します。
-
データをCSVに変換します。
-
Azue Blob Storage アカウント名、キー、コンテナ名の変数を割り当てます。
-
Azure Blob Storageにファイルをアップロードします。
-
Azure ポータル にログオンし、BLOB ストレージ アカウントを開いて、アップロードされたファイルを表示します。

モデルの学習
既存の Azure Machine Learning でデータを分析する 記事を使用して、Azure Blob Storage のデータに基づく予測機械学習モデルを構築します。顧客が自転車を購入する可能性があるかどうかを予測することで、自転車ショップ Adventure Works 向けのターゲット マーケティング キャンペーンを構築します。
データのインポート
データは、上のセクションでコピーした vTargetMail.csv という Azure Blob Storage ファイルにあります。
- Azure Machine Learning studio にサインインし、 Experimentsをクリックします。
- 画面左下の +NEW をクリックし、 Blank Experiment を選択します。
- 実験の名前として「Targeted Marketing」を入力します。
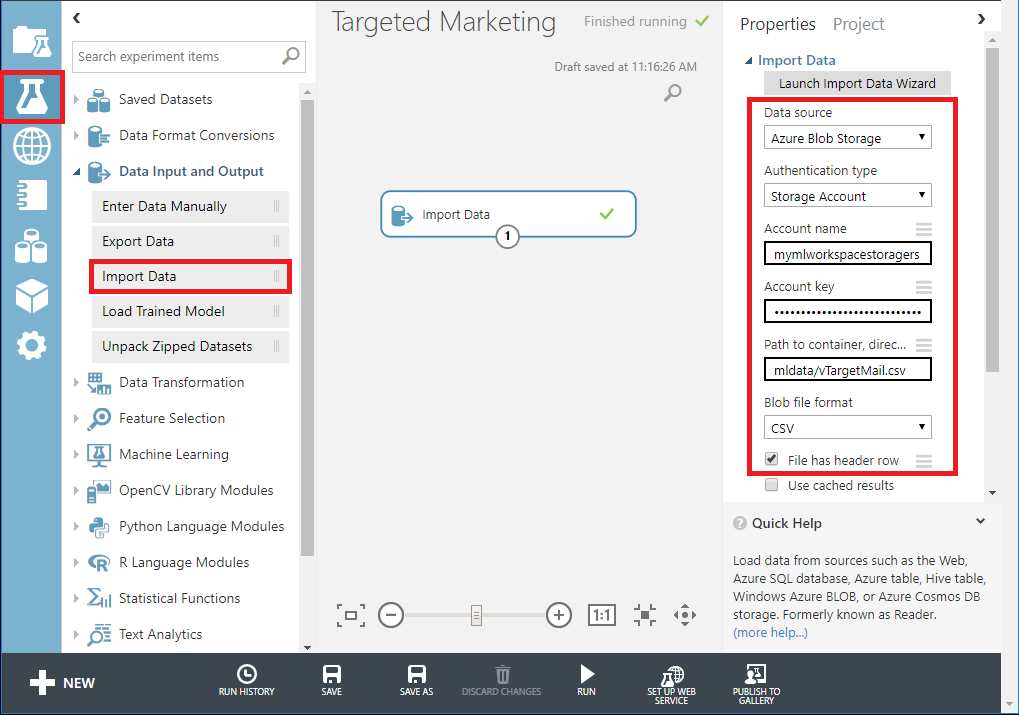
- Data Input and output の下にある Import data モジュールをモジュール ペインからキャンバスにドラッグします。
- [プロパティ] ペインで Azure Blob Storage の詳細 (アカウント名、キー、コンテナ名) を指定��します。
experimentキャンバスの下にある Run をクリックして、実験を実行します。
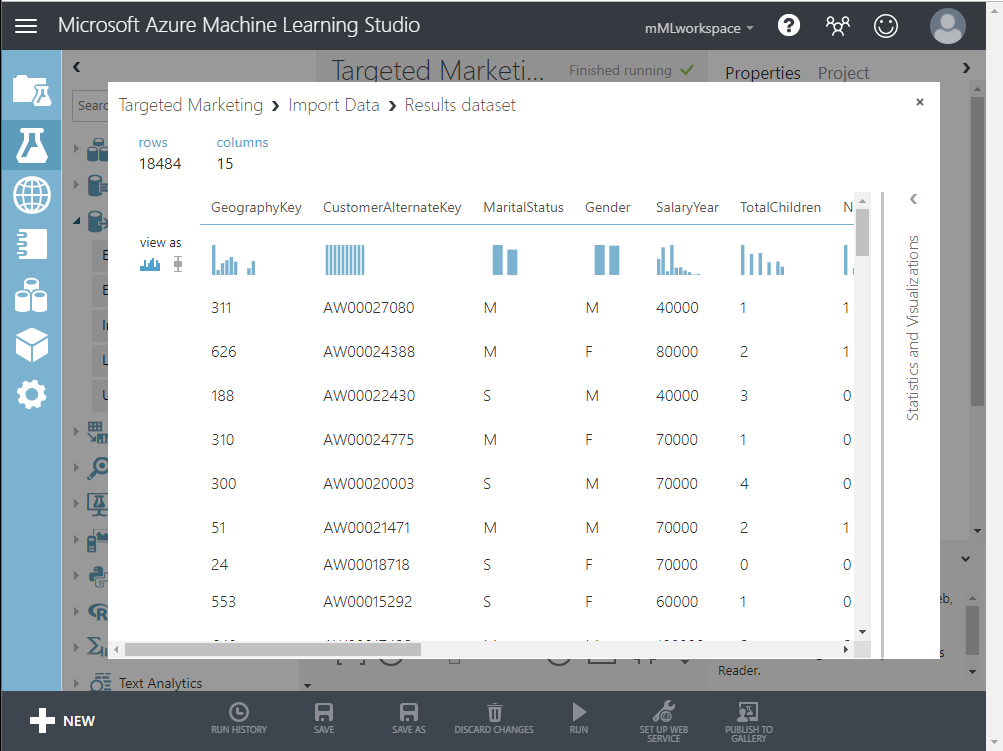
実験が正常に終了したら、Import Data モジュールの下部にある出力ポートをクリックし、 Visualize を選択してインポートしたデータを確認します。
データのクリーンアップ
データをクリーンアップするには、モデルに関係のない列をいくつか削除します。これを行うには、次の手順を実行します。
- Data Transformation < Manipulation の下の Select Columns in Dataset モジュールをキャンバスにドラッグします。このモジュールを Import Data モジュールに接続します。
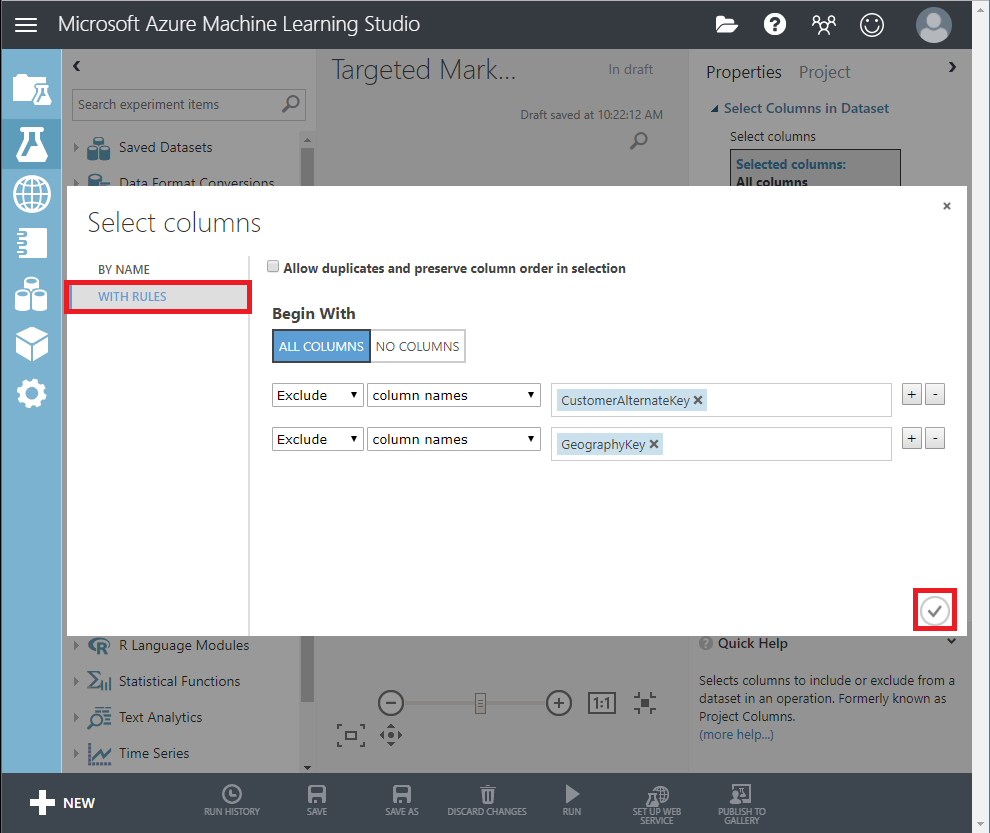
- プロパティペインの Launch column selector をクリックして、ドロップする列を指定します。
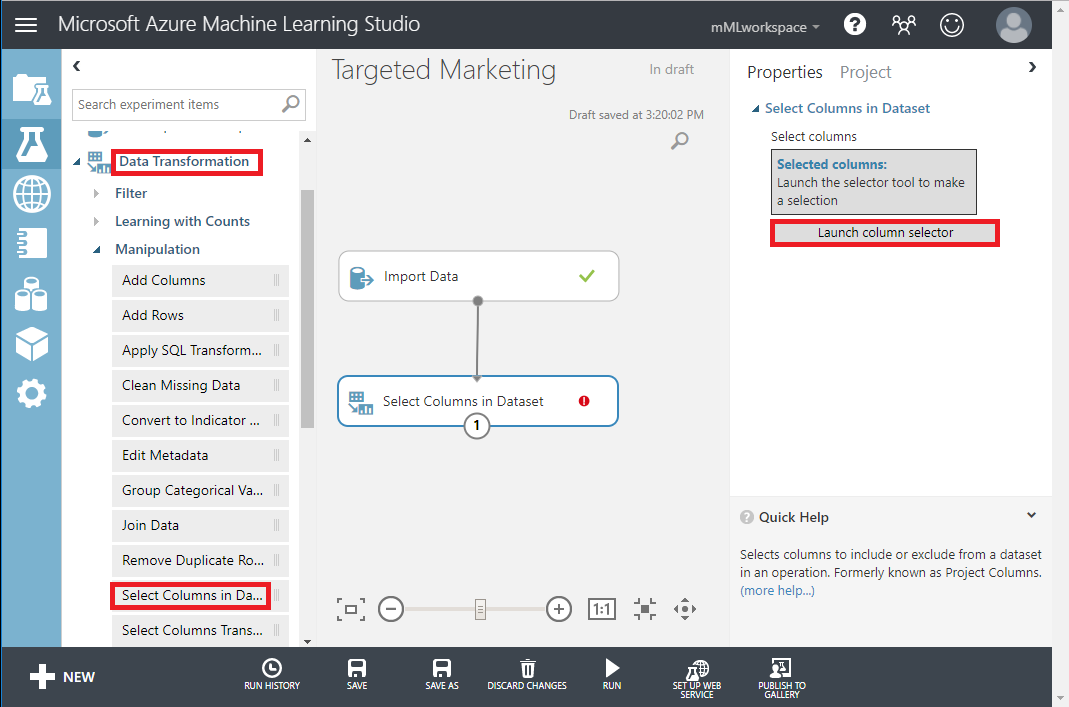
- CustomerAlternateKey と GeographyKey の2 つのカラムを除外します。
モデル�の構築
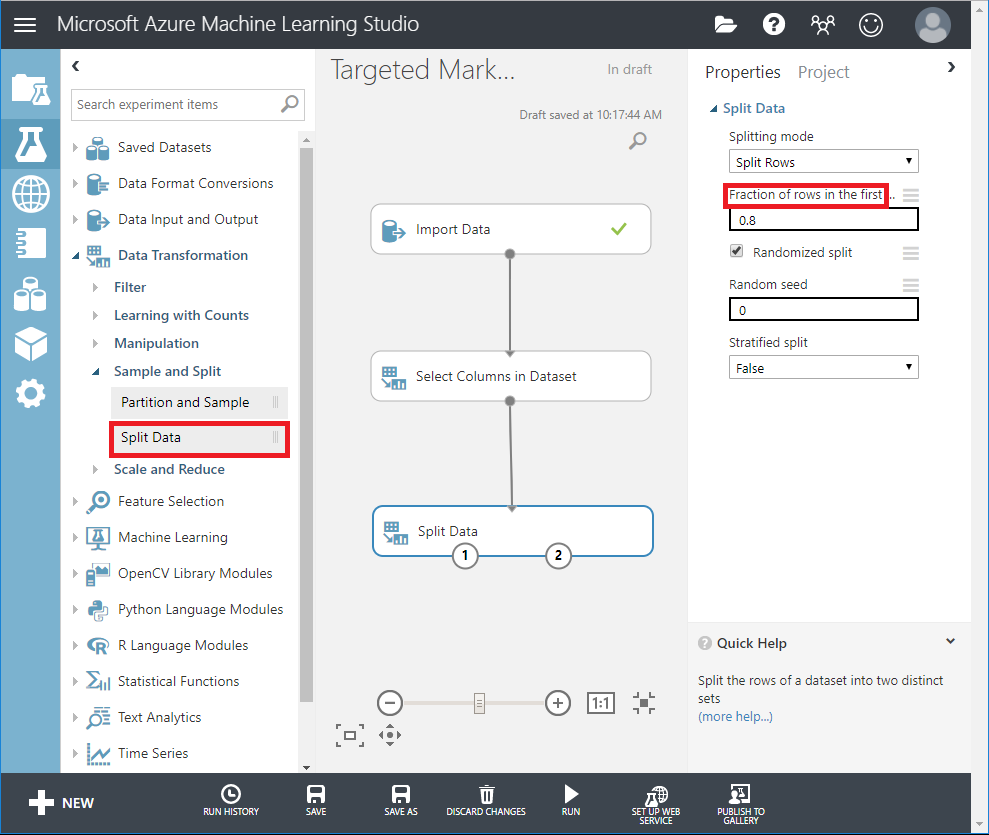
データを 80-20 に分割します。80% は機械学習モデルのトレーニングに、20% はモデルのテストに使用します。このバイナリ分類問題には、「2 クラス」アルゴリズムを使用します。
-
SplitData モジュールをキャンバスにドラッグし、「Select Columns in DataSet」で接続します。
-
プロパティペインで「Fraction of rows in the first output dataset」に「0.8」を入力します。
-
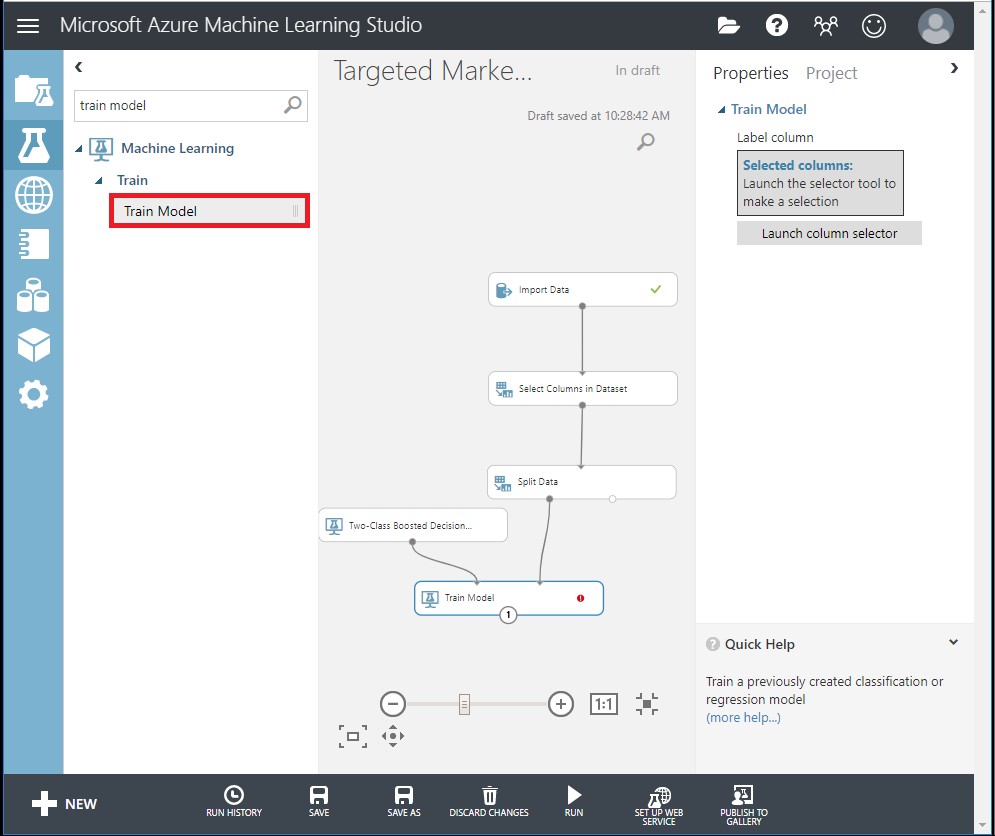
Two-Class Boosted Decision Tree モジュールを検索し、キャンバスにドラッグします。
-
Train Model モジュールを検索してキャンバスにドラッグし、Two-Class Boosted Decision Tree (MLアルゴリズム)モジュールと Split Data (アルゴリズムをトレーニングするためのデータ)モジュールに接続して入力を指定する。
-
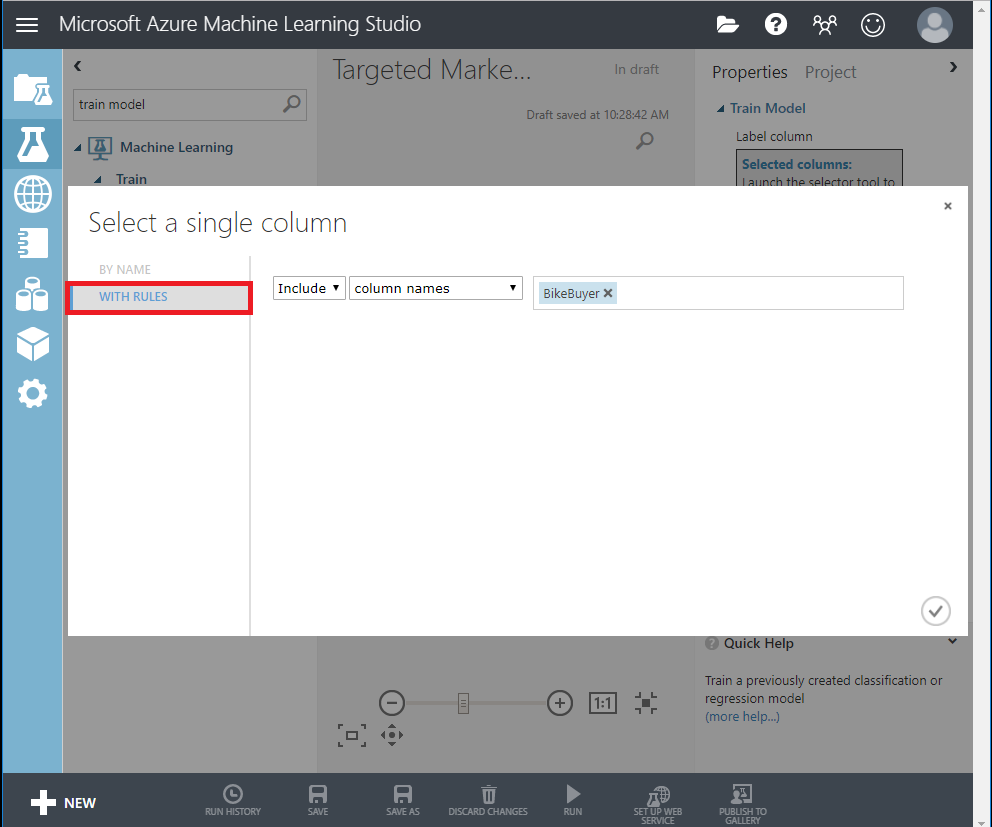
次に、プロパティ ペインで Launch column selector をクリックします。予測する列として BikeBuyer 列を選択します。
モデルの評価
ここで、モデルがテスト データに対してどのように機能するかをテストします。選択したアルゴリズムと別のアルゴリズムを比較して、どちらのパフォーマンスが優れているかを確認します。
- Score Model モジュールをキャンバスにドラッグし、 Train Model と Split Data モジュールに接続します。
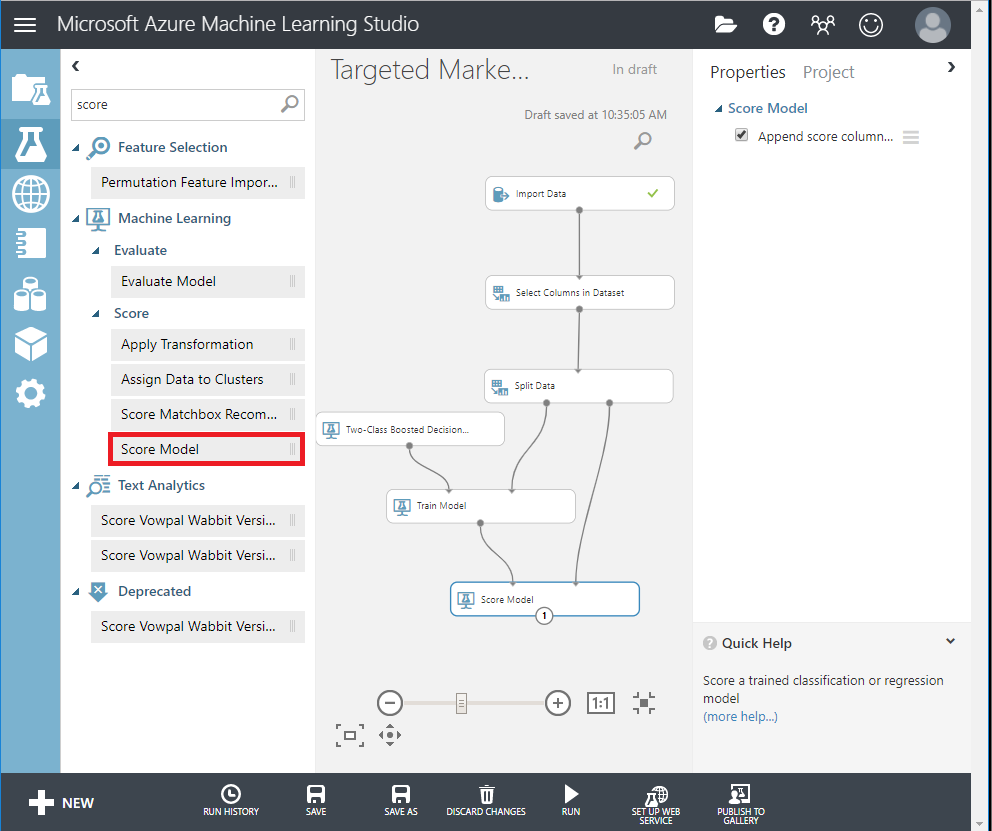
- Two-Class Bayes Point Machine を検索して実験キャンバスにドラッグします。このアルゴリズムのパフォーマンスを 2 クラス ブースト決定木と比較します。
- 「Train Model 」と「Score Model」モジュールをコピーして、キャンバスに貼り付けます。
- Evaluate Model モジュールを検索して、キャンバスにドラッグし、2つのアルゴリズムを比較します。
- Run 実験します。
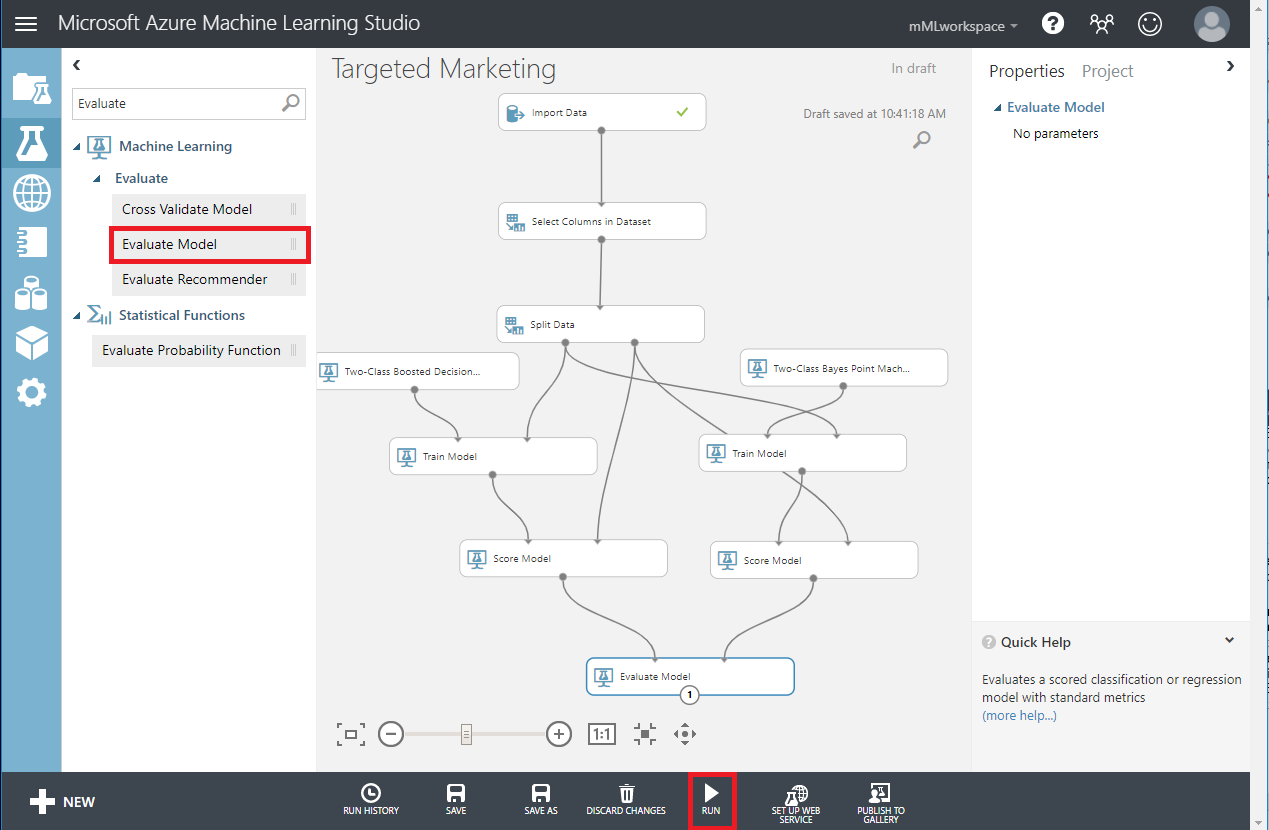
- Evaluate Model モジュールの下部にある出力ポートをクリックし、Visualize をクリックします。
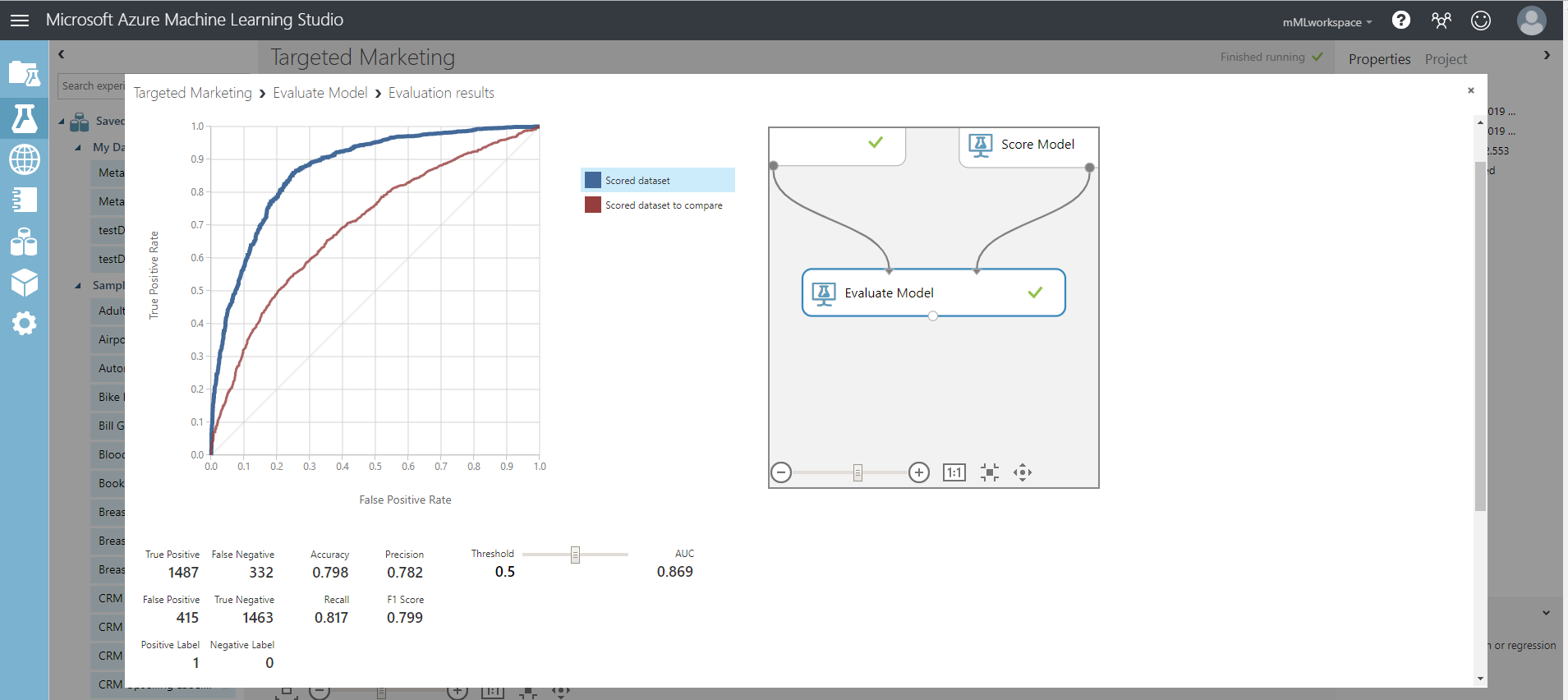
提供されるメトリックは、ROC 曲線、精度再現率図、リフト曲線です。これらのメトリックを見ると、最初のモデルが 2 番目のモデルよりもパフォーマンスが優れていることがわかります。最初のモデルが予測した内容を確認するには、スコア モデルの出力ポー�トをクリックし、[視覚化] をクリックします。
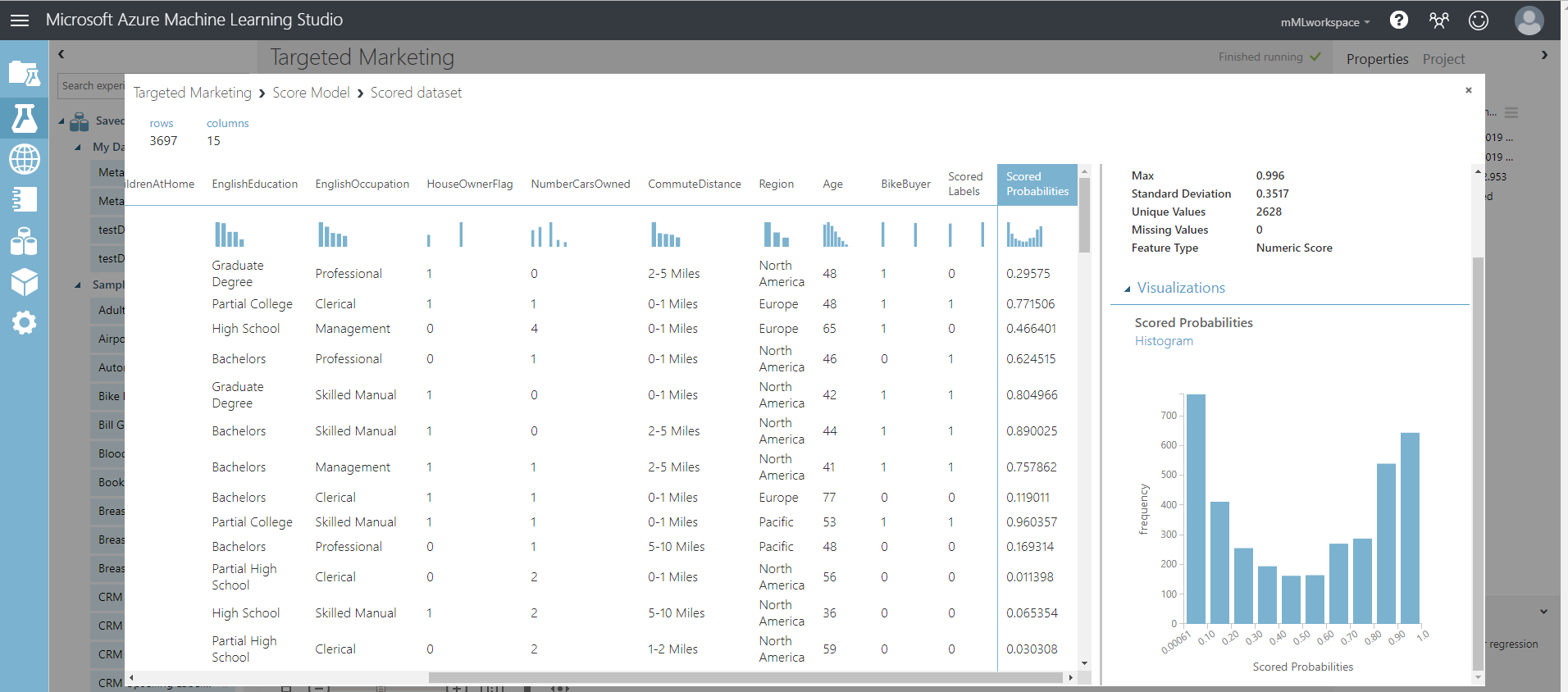
テストデータセットに2つの列が追加されているのがわかります。
- スコアリングされた確率:顧客がバイクの購入者である可能性。
- スコア付けされたラベル: モデルによって行われた分類 - 自転車購入者 (1) または非購入者 (0)。このラベル付けの確率しきい値は 50% に設定されており、調整可能です。
BikeBuyer 列 (実際) と Scored Labels (予測) 列を比較すると、モデルのパフォーマンスがどの程度優れているかがわかります。次の手順では、このモデルを使用して新規顧客の予測を行い、このモデルを Web サービスとして公開するか、結果を SQL Data Warehouse に書き戻すことができます。
さらに詳しく
- 予測型機械学習モデルの構築の詳細については、 Introduction to Machine Learning on Azureを参照してください。
- 大規模なデータセットのコピーには、Teradata Parallel Transporterのロード/アンロード オペレーターとAzure Blob Storageの間のインターフェイスである Teradata Access Module for Azure の利用を検討してください。
ご質問がある場合やさらにサポートが必要な場合は、 コミュニティフォーラム にアクセスしてサポートを受けたり、他のコミュニティ メンバーと交流したりしてください。