AWS Glue スクリプトを使用して Teradata Vantage から Amazon S3 にデータを取り込み、カタログ化する
概要
このクイックスタートでは、AWS Glue を使用して Teradata Vantage から Amazon S3 にデータを取り込み、カタログ化するプロセスについて詳しく説明します。
カタログ化が必須でない場合に Amazon S3 にデータを取り込むには、 Teradata 書き込み NOS 機能を検討してください。
前提条件
- アクセス Amazon AWS アカウント
- Teradata Vantageインスタンスへのアクセス。
注記
Vantage のテストインスタンスが必要な場合は、 https://clearscape.teradata.com で無料でプロビジョニングできます
- テストデータをロードするためのクエリーを送信するデータベース クライアント
テストデータの読み込み
- お気に入りのデータベースクライアントで次のクエリーを実行します
Amazon AWS セットアップ
このセクションでは、以下の各手順について詳しく説明します。
- データを取り込むための Amazon S3 バケットを作成する
- メタデータを保存するための AWS Glue カタログデータベースを作成する
- AWS Secrets ManagerにTeradata Vantageの認証情報を保存する
- ETLジョブに割り当てるAWS Glueサービスロールを作成する
- AWS Glue で Teradata Vantage インスタンスへの接続を作成する
- AWS Glue ジョブを作成する
- Teradata Vantage データを Amazon S3 に自動的に取り込み、カタログ化するためのスクリプトを作成します。
データを取り込むための Amazon S3 バケットを作成する
- Amazon S3で
Create bucketを選択します。
- バケットに名前を割り当てて、メモしておきます。
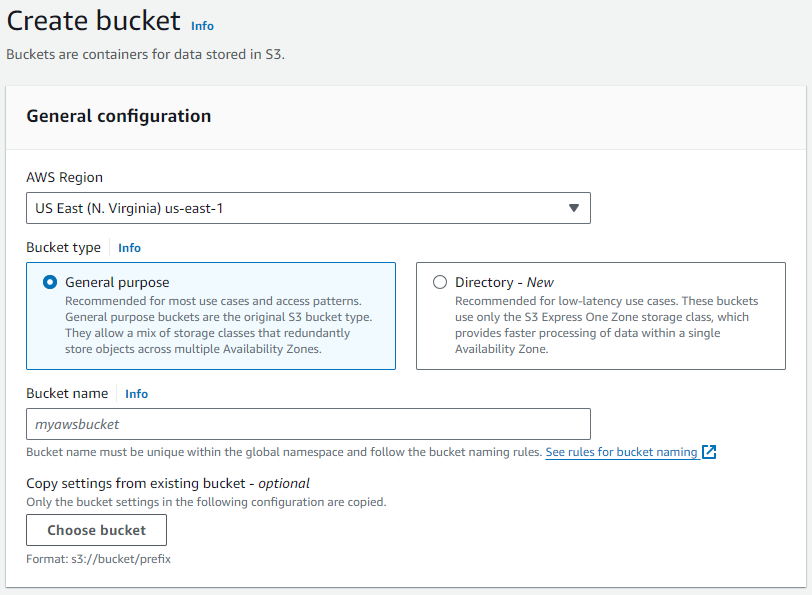
- すべての設定をデフォルト値のままにします。
Create bucketをクリックします。
すべての設定をデフォルト値のままにします。
- AWS Glue で、データカタログ、データベースを選択します。
Add databaseをクリックします。
- データベース名を定義し、
Create databaseをクリックします。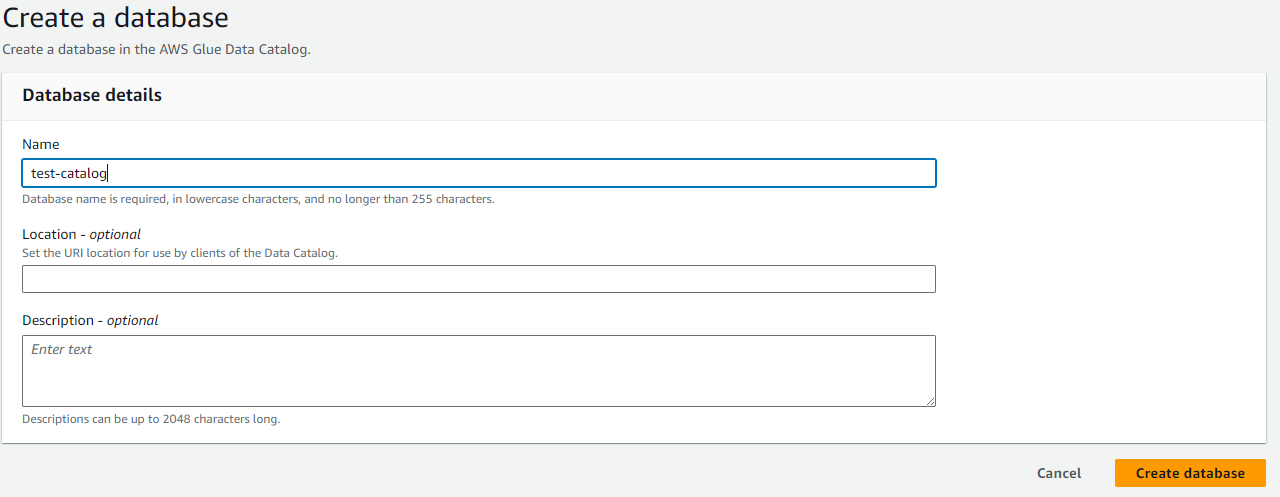
AWS Secrets ManagerにTeradata Vantageの認証情報を保存する
- AWS Secrets Managerで、
Create new secretを選択します。
- シークレットは、Teradata Vantage インスタンスに応じて、次のキーと値を持つ
Other type of secretである必要があります。- USER
- PASSWORD
ClearScape Analytics Experience の場合、ユーザーは常に「demo_user」であり、パスワードは ClearScape Analytics Experience 環境の作成時に定義したパスワードです。
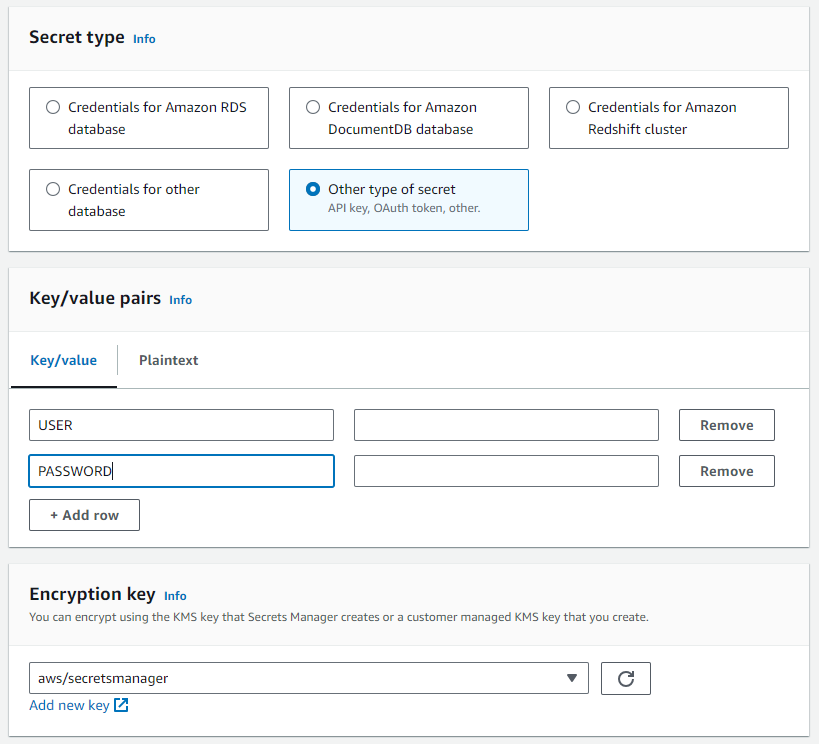
- シークレットに名前を割り当てます。
- 残りの手順はデフォルト値のままにしておきます。
- 秘密を作成します。
ETL ジョブに割り当てる AWS Glue サービスロールを作成する
作成するロールには、Glue サービス ロールの一般的な権限へのアクセス権だけでなく、作成したシークレットと S3 バケットを読み取るアクセス権も付与する必要があります。
- AWS で、IAM サービスに移動します。
- アクセス管理で
Rolesを選択します。 - ロールで
Create roleをクリックします。
- 信頼できるエンティティの選択で、
AWS serviceを選択し、ドロップダウンからGlueを選択します。
- 権限の追加:
- 検索する
AWSGlueServiceRole。 - 関連するチェックボックスをクリックします。
- 検索する
SecretsManagerReadWrite。 - 関連するチェックボックスをクリックします。
- 検索する
- 名前で確認して作成します。
- ロールの名前を定義します。
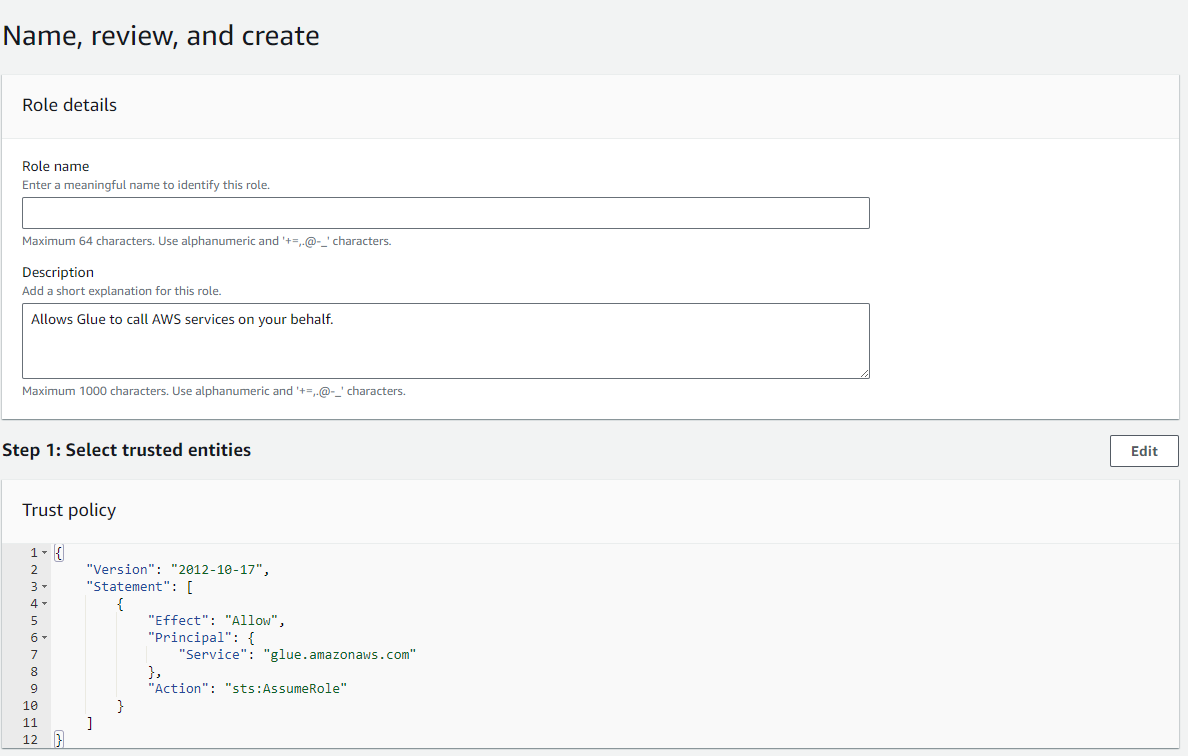
- ロールの名前を定義します。
Create roleをクリックします。- 「アクセス管理」、「ロール」に戻り、作成したロールを検索します。
- 役割を選択してください。
Add permissionsをクリックしてからCreate inline policyをクリックします。JSONをクリックします。- ポリシー エディターで、作成したバケットの名前を置き換えて、以下の JSON オブジェクトを貼り付けます。
Nextをクリックします。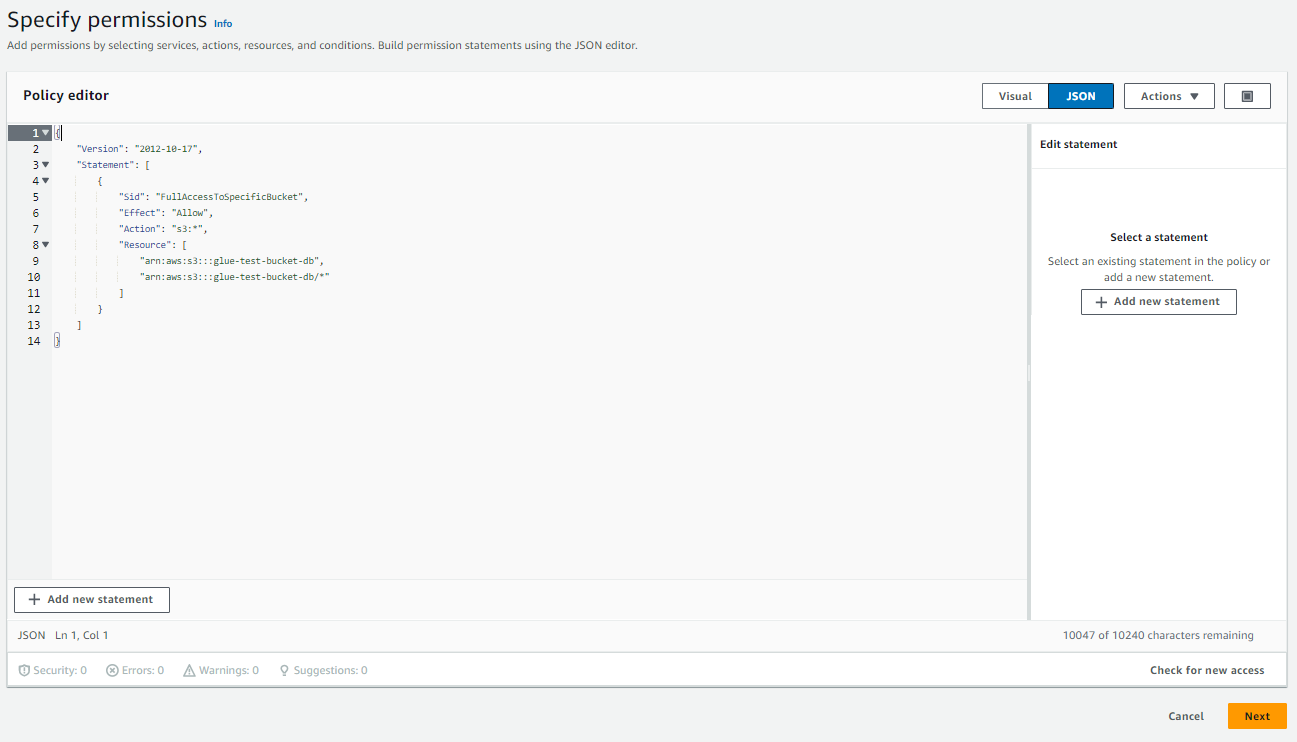
- ポリシーに名前を割り当て�ます。
Create policyをクリックします。
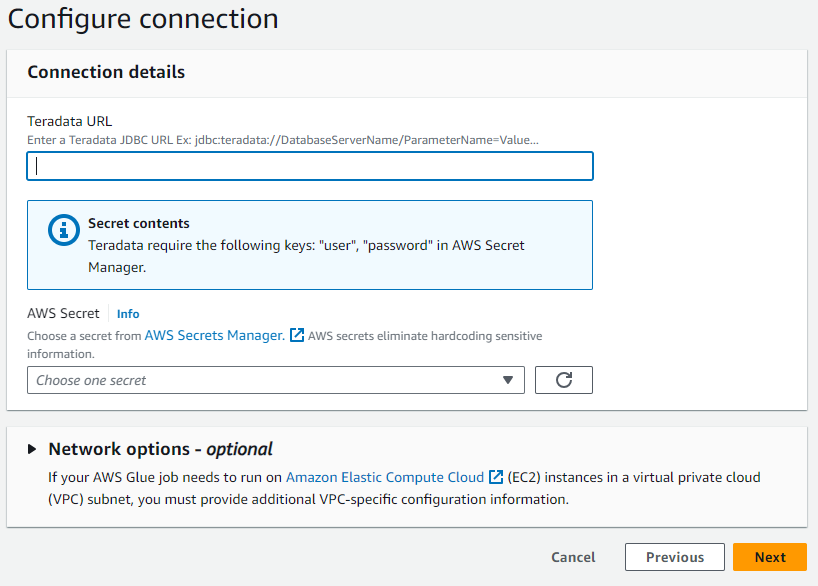
AWS Glue で Teradata Vantage インスタンスへの接続を作成する
- AWS Glue で
Data connectionsを選択します。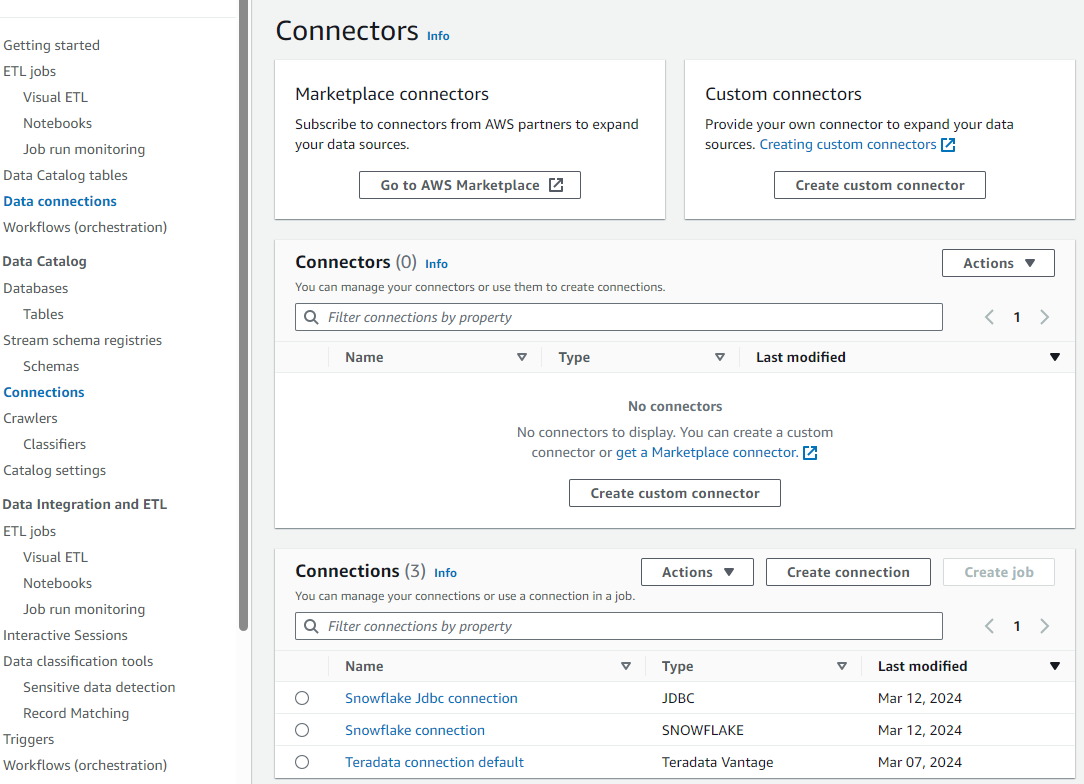
- コネクタの下で、
Create connectionを選択します。 - Teradata Vantage データ ソースを検索して選択します。
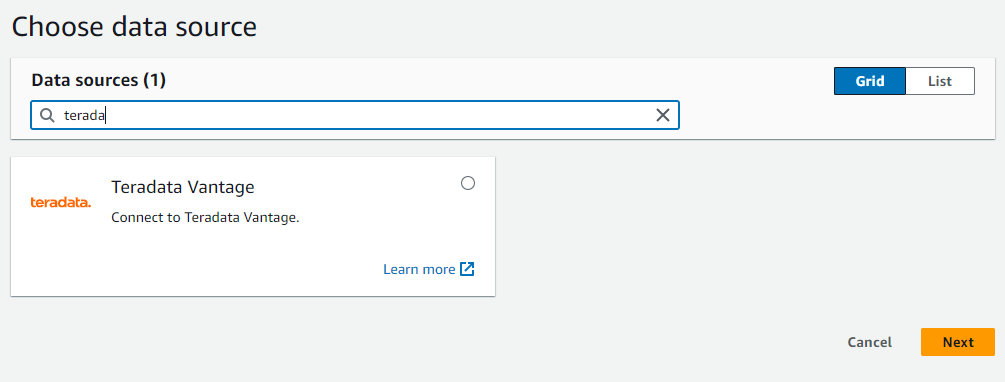
- ダイアログ ボックスに、Teradata Vantage インスタンスの URL を JDBC 形式で入力します。
ClearScape Analytics Experience の場合、URL は次の構造に従います。
jdbc:teradata://<URL Host>/DATABASE=demo_user,DBS_PORT=1025
- 前の手順で作成した AWS シークレットを選択します。
- 接続に名前を付けて、作成プロセスを終了します。
AWS Glue ジョブを作成する
- AWS Glue で
ETL Jobsを選択し、Script editorをクリックします。
- エンジンとして
Sparkを選択し、新しく開始することを選択します。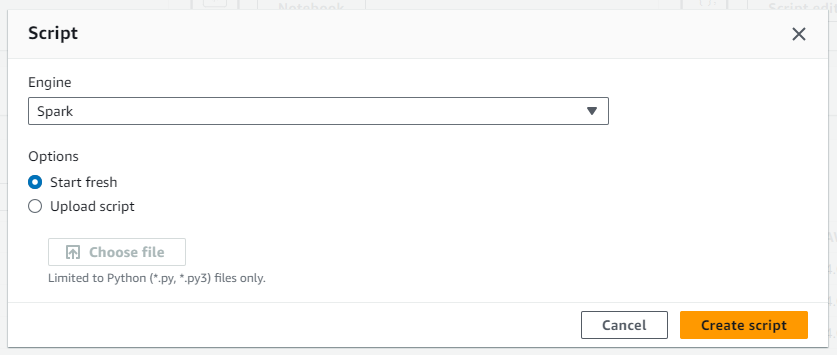
Teradata Vantage データを Amazon S3 に自動的に取り込み、カタログ化するためのスクリプトを作成します。
- 次のスクリプトをエディターにコピーします。
- スクリプトには次の変更が必要です。
- S3 バケットの名前を置き換えます。
- Glue カタログ データベースの名前を置き換えます。
- ガイドの例に従わない場合は、データベース名と、取り込んでカタログ化するテーブルを変更します。
- カタログ作成の目的で、例では各テーブルの最初の行のみが取り込まれます。このクエリーを変更して、テーブル全体を取り込んだり、選択した行をフィルタ処理したりできます。
- スクリプトには次の変更が必要です。
-
スクリプトに名前を割り当てる
-
ジョブの詳細の基本プロパティ:
- ETL ジョブ用に作成した IAM ロールを選択します。
- テストの場合、要求されるワーカー数として「2」を選択します。これが最小許容数です。
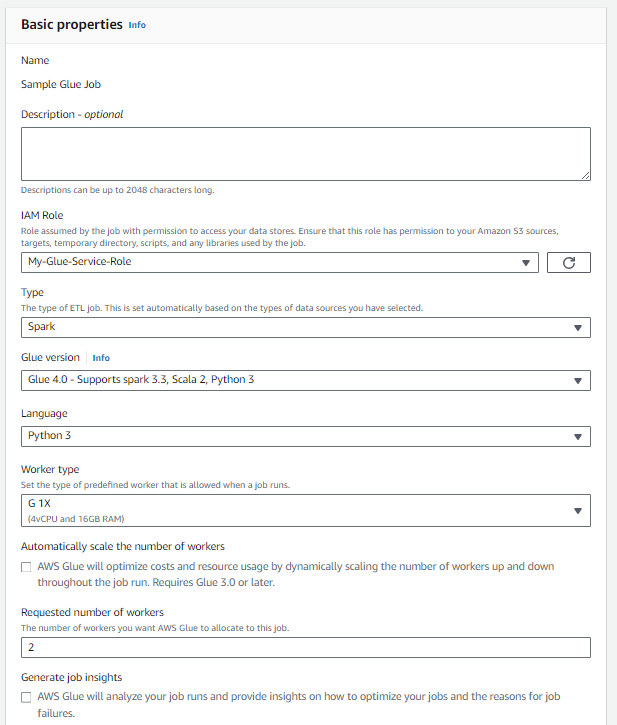 *
* Advanced properties、Connectionsで Teradata Vantage への接続を選択します。
作成された接続は、ジョブ構成で 1 回、スクリプト自体で 1 回、合わせて 2 回参照する必要があります。
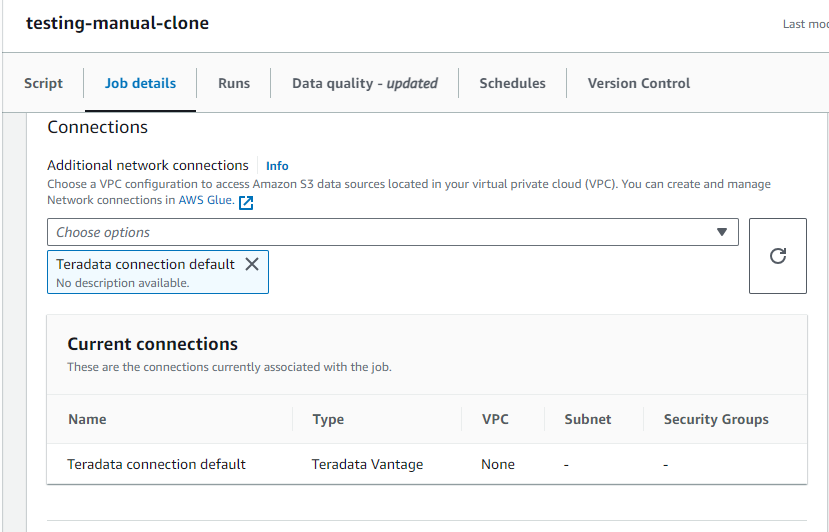
Saveをクリックします。Runをクリックします。- ETL ジョブが完了するまでに数分かかります。この時間のほとんどは Spark クラスターの起動に関連しています。
結果の確認
-
ジョブが完了したら:
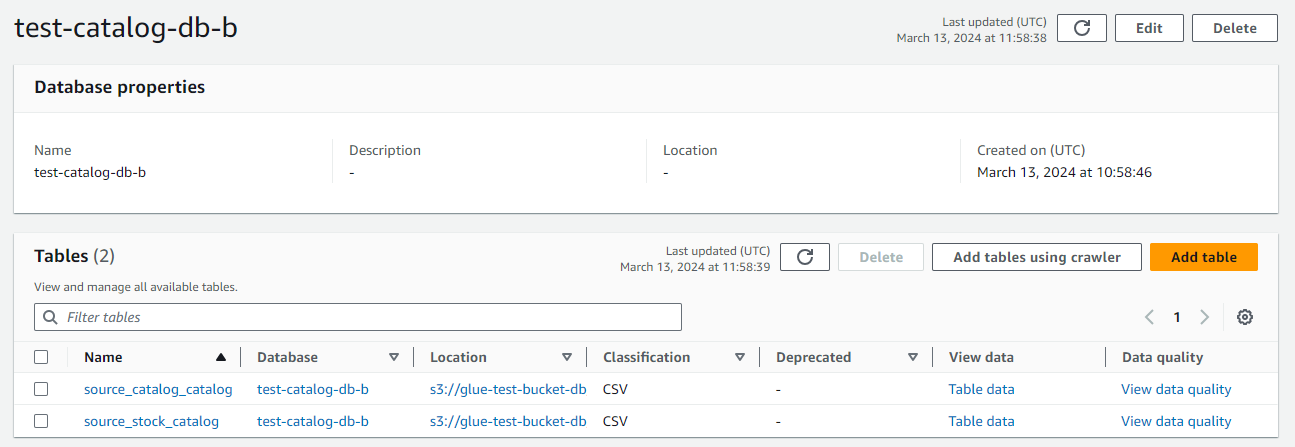
- データ カタログ、データベースに移動します。
- 作成したカタログ データベースをクリックします。
- この場所に、Glue ETL ジョブを通じて抽出されカタログ化されたテーブルが表示されます。
-
取り込まれたすべてのテーブルは、S3 に圧縮ファイルとしても存在します。まれに、これらのファイルが直接クエリーされることがあります。AWS Athena などのサービスを使用して、カタログ メタデータに依存するファイルをクエリーできます。
まとめ
このクイックスタートでは、AWS Glue スクリプトを使用して Teradata Vantage のデータを Amazon S3 に取り込み、カタログ化する方法を学びました。
さらに詳しく
ご質問がある場合やさらにサポートが必要な場合は、 コミュニティフォーラム にアクセスしてサポートを受けたり、他のコミュニティ メンバーと交流したりしてください。