dbt を使用して Airbyte に読み込まれたデータを変換する方法
概要
このチュートリアルでは、 dbt (データ構築ツール) を使用して、Teradata Vantage の Airbyte (オープンソースの抽出ロード ツール) を介して外部データ ロードを変換する方法�を説明します。
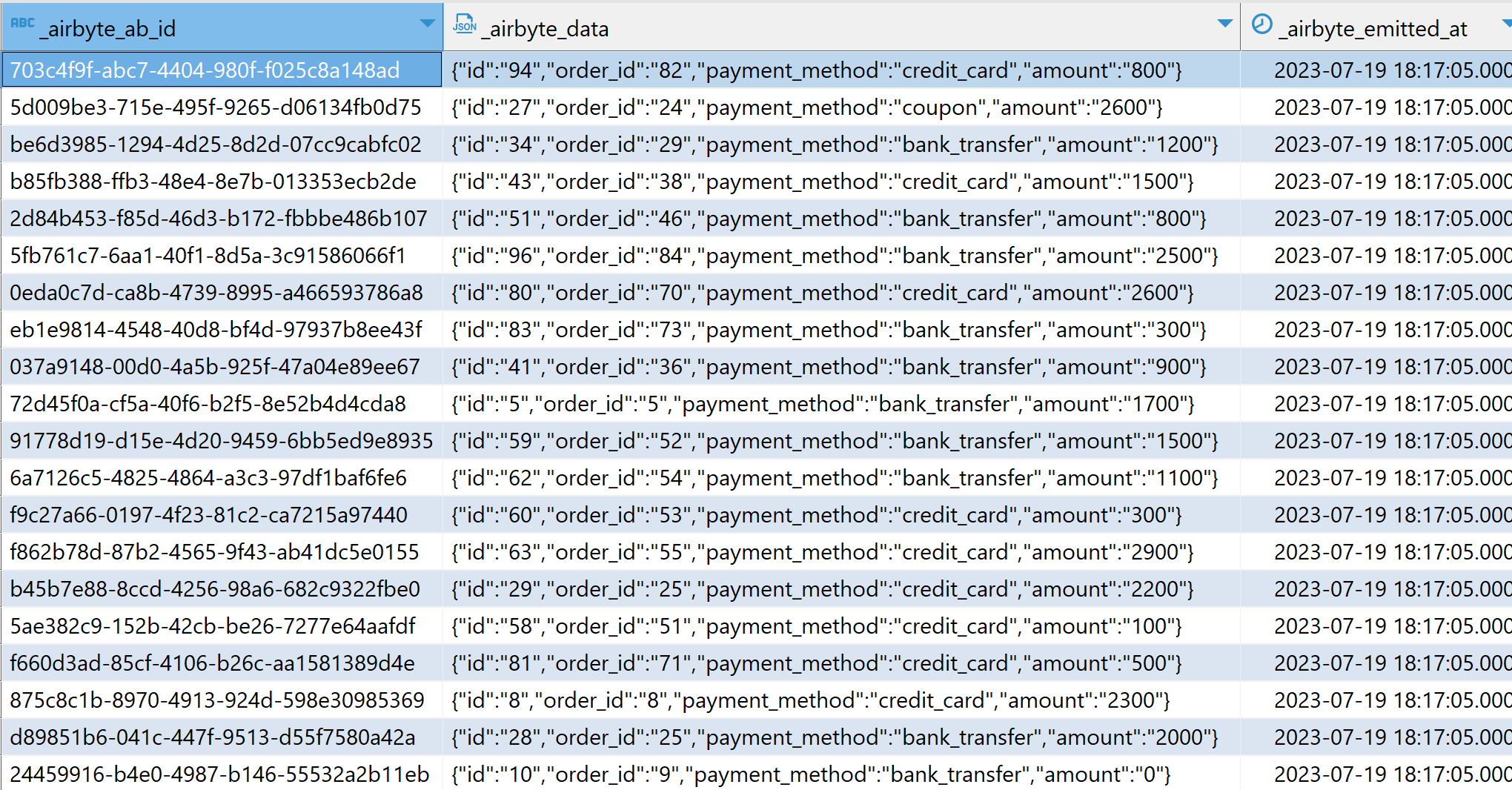
このチュートリアルは、元の dbt Jaffleショップチュートリアル をベースに少し変更を加えたもので、 dbt seed コマンドを使用する代わりに、Airbyte を使用して Jaffle Shop データセットを Google スプレッドシートから Teradata Vantage にロードします。airbyte を通じてロードされたデータは、次の図に示すように JSON 列に含まれています。
前提条件
- Teradata Vantageインスタンスへのアクセス。
注記
Vantage のテストインスタンスが必要な場合は、 https://clearscape.teradata.com で無料でプロビジョニングできます
- サンプルデータ: サンプルデータ Jaffleショップデータセット はGoogle スプレッドシートにあります。
- 参照 dbt プロジェクト リポジトリ: Airbyte との Jaffle プロジェクト。
- Python 3.7、3.8、3.9、3.10、または 3.11 がインストールされています。
サンプルデータのローディング
- Airbyteチュートリアルの手順に従います。Airbyte チュートリアルで参照されているデフォルトのデータセットではなく、 Jaffle Shop スプレッドシート からデータをロードするようにしてください。また、Teradata の宛先の
Default Schemaをairbyte_jaffle_shopに設定します。
AirbyteでTeradata宛先を設定すると、Default Schema をリクエストされます。Default Schema を airbyte_jaffle_shop に設定します。
プロジェクトのクローンを作成する
チュートリアル リポジトリのクローンを作成し、ディレクトリをプロジェクト ディレクトリに変更します。
dbtをインストールする
-
dbt とその依存関係を管理するための新しい Python 環境を作成します。環境をアクティブ化します。
注記対応するバッチ ファイル
./myenv/Scripts/activateを実行することで、Windows で仮想環境をアクティブ化できます。 -
dbt-teradataモジュールをインストールします。dbtのコアモジュールも依存関係のあるモジュールとして含まれているので、別にインストールする必要はありません。
dbtを構成する
-
dbtプロジェクトを初期化します。
dbt プロジェクト ウィザードでは、プロジェクト名とプロジェクトで使用するデータベース管理システムの入力を求められます。このデモでは、プロジェクト名を
dbt_airbyte_demoと定義します。dbt-teradata コネクタを使用しているため、使用できるデータベース管理システムは Teradata のみです。

-
$HOME/.dbtディレクトリにあるprofiles.ymlファイルを設定します。profiles.ymlファイルが存在しない場合は、新しいファイルを作成できます。 -
Teradataインスタンスの
HOST、Username、Passwordに合わせて、server、username、passwordをそれぞれ調整します。 -
この構成では、
schemaはサンプルデータを含むデータベースを表し、この場合は、Airbyteairbyte_jaffle_shopで定義したデフォルト スキーマです。 -
profiles.ymlファイルの準備ができたら、セットアップを検証できます。dbt プロジェクト フォルダに移動して、次のコマンドを実行します。デバッグコマンドがエラーを返した場合、
profiles.ymlの内容に問題がある可能性があります。設定が正しい場合は、All checks passed!というメッセージが表示されます。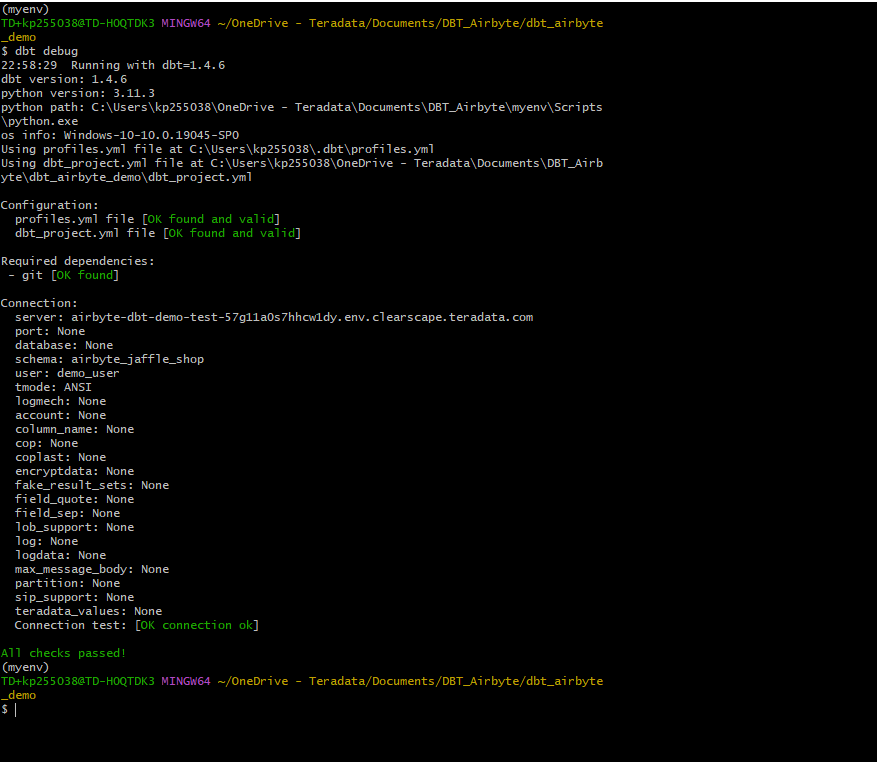
Jaffle Shop dbtプロジェクト
jaffle_shop はオンラインで注文を受ける架空のレストランです。このビジネスのデータは、以下のエンティティ関係図に従う customers、 orders 、 paymentsのテーブルで構成されています。

ソース システムのデータは正規化されています。分析ツールに適した、同じデータに基づくディメンション モデルを以下に示します。

dbt の変換
以下に詳述する変換を含む完全な dbt プロジェクトは Airbyte との Jaffle プロジェクトにあります。
参照 dbt プロジェクトは 2 つの型の変換を実行します。
- まず、Airbyte 経由で Google スプレッドシートから読み込まれた生データ (JSON 形式) をステージング ビューに変換します。この段階で、データは正規化されます。
- 次に、正規化されたビューを、分析に使用できるディメンションモデルに変換します。
以下の図は、dbt を使用した Teradata Vantage の変換手順を示しています。

すべての dbt プロジェクトと同様に、フォルダ models には、プロジェクトまたは個々のモデル レベルでの対応する構成に従って、プロジェクトがテーブルまたはビューとしてマテリアライズドするデータ モデルが含まれています。
モデルは、data warehouses/データ レイクの構成における目的に応じて、さまざまなフォルダに整理できます。一般的なフォルダ レイアウトには、 stagingのフォルダ、 coreのフォルダ、 martsのフォルダなどがあります。この構造は、dbt の動作に影響を与えることなく簡素化できます。
ステージングモデル
オリジナルの dbt Jaffleショップチュートリアル では、プロジェクトのデータは ./data フォルダにある csv ファイルから dbt の seed コマンドを通じてロードされます。 seed コマンドはテーブルからデータをロードするためによく使用されますが、このコマンドはデータのロードを実行するようには設計されていません。
このデモでは、データ ローディング用に設計されたツール Airbyte を使用してデータウェアハウス/レイクにデータを読み込む、より一般的なセットアップを想定しています。 Airbyte を通じてロードされたデータは、生の JSON 文字列として表されます。これらの生データから、正規��化されたステージング ビューを作成します。このタスクは、次のステージング モデルを通じて実行します。
stg_customersモデルは、_airbyte_raw_customersテーブルからcustomersの正規化されたステージングビューを作成します。stg_ordersモデルは、_airbyte_raw_ordersテーブルからordersの正規化されたステージングビューを作成します。stg_paymentsモデルは、_airbyte_raw_paymentsテーブルからpaymentsの正規化されたステージングビューを作成します。
JSON 文字列を抽出するメソッドはすべてのステージング モデルで一貫しているため、これらのモデルの 1 つだけを例として使用して、変換の詳細な説明を提供します。
以下は、stg_orders.sql モデルを介して生の JSON データをビューに変換する例です。
- このモデルでは、ソースは生のテーブル
_airbyte_raw_ordersとして定義されます。 - この生のテーブル列には、メタデータと実際に取り込まれたデータの両方が含まれます。データ列は
_airbyte_dataと呼ばれます。 - この列は Teradata JSON 型です。この型は、JSON オブジェクトからスカラー値を取得するメソッド JSONExtractValue をサポートします。
- このモデルでは、ビューをマテリアライズドするために、対象の各属性を取得し、意味のあるエイリアスを追加しています。
ディメンションモデル (マート)
ディメンションモデルの構築は、以下の 2 段階のプロセスです。
- まず、
stg_orders、stg_customers、stg_paymentsの正規化されたビューを取得し、非正規化された中間結合テーブルcustomer_orders、[]、order_payments、customer_paymentsを構築します。これらのテーブルの定義は./models/marts/core/intermediateにあります。 - 2 番目のステップでは、
dim_customersおよびfct_ordersモデルを作成します。これらは、BI ツールに公開するディメンション モデル テーブルを構成します。これらのテーブルの定義は./models/marts/coreにあります。
変換を実行する
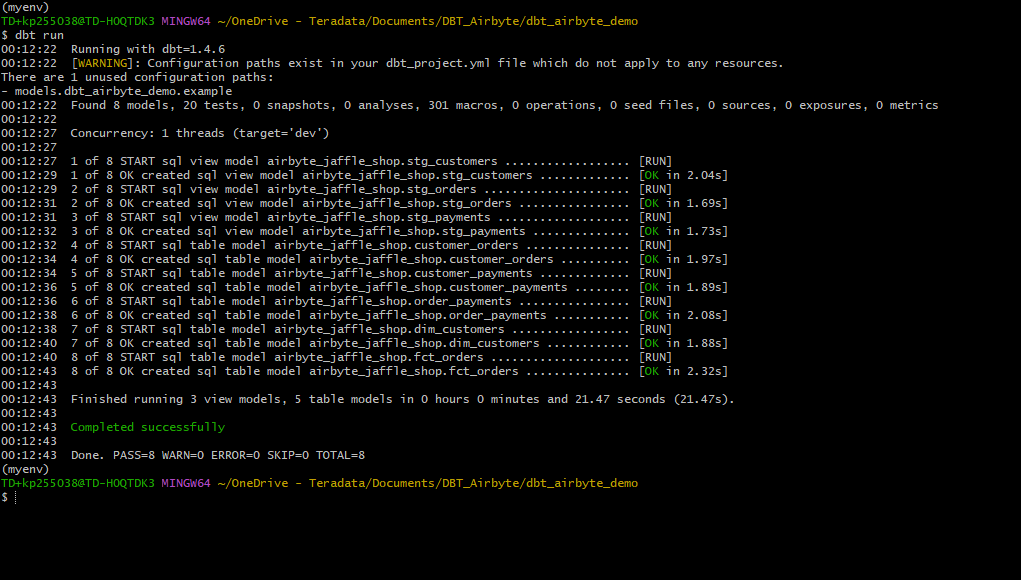
dbt プロジェクトで定義された変換を実行するには、以下のコマンドを実行します。
以下に示すように、各モデルのステータスが取得されます。
テストデータ
ディメンションモデル内のデータが正しいことを確認するために、dbt を使用すると、データに対するテストを定義して実行できます。
テストは ./models/marts/core/schema.yml と ./models/staging/schema.yml で定義されています。各列には、tests キーの下で複数のテストを構成できます。
- 例えば、
fct_orders.order_id列には固有な非 NULL 値が含まれることが予想されます。
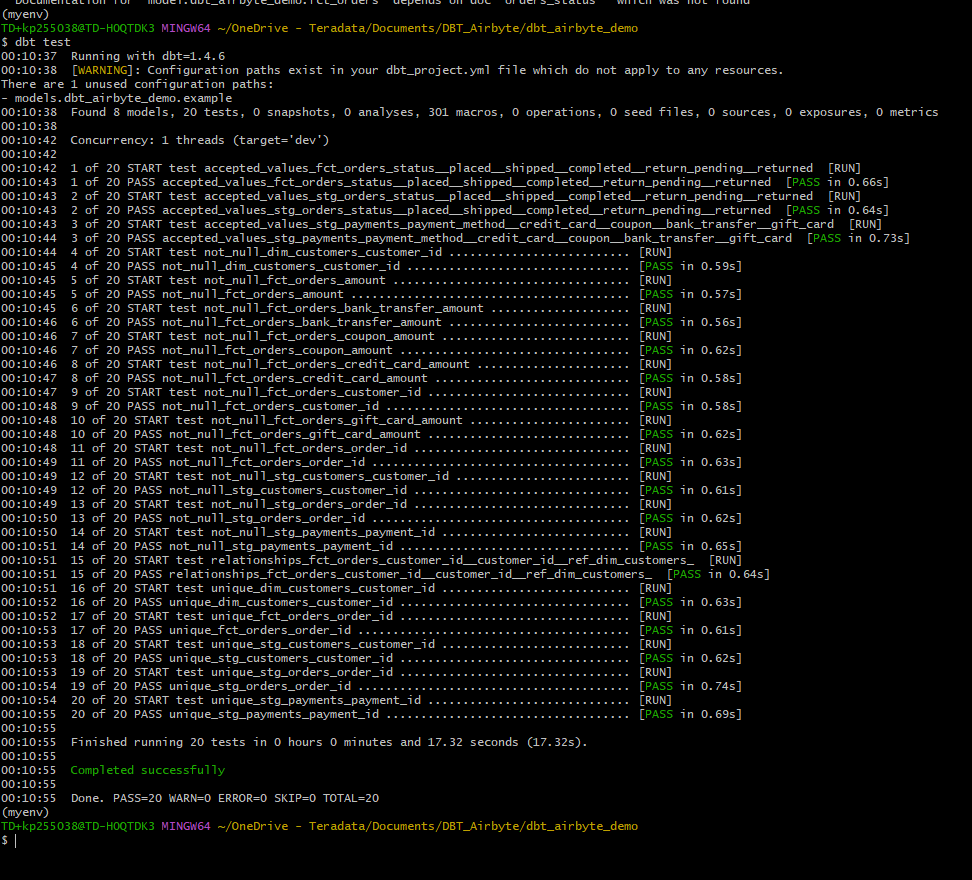
生成されたテーブルのデータがテスト条件を満たしていることを検証するには、以下のコマンドを実行します。
モデル内のデータがすべてのテスト ケースを満たしている場合、このコマンドの結果は以下のようになります。
ドキュメントを生成する
私たちのモデルはほんの数個のテーブルで構成されています。より多くのデータ ソースとより複雑なディメンションモデルを使用するシナリオでは、データ系統と各中間モデルの目的をドキュメント化することが非常に重要です。
dbt を使用してこの型のドキュメントを生成するのは非常に簡単です。
これにより、./targetディレクトリにhtmlファイルが生成されます。
独自のサーバーを起動してドキュメントを参照できます。次のコマンドはサーバーを起動し、ドキュメントのランディング ページを含むブラウザー タブを開きます。
Lineage Graph
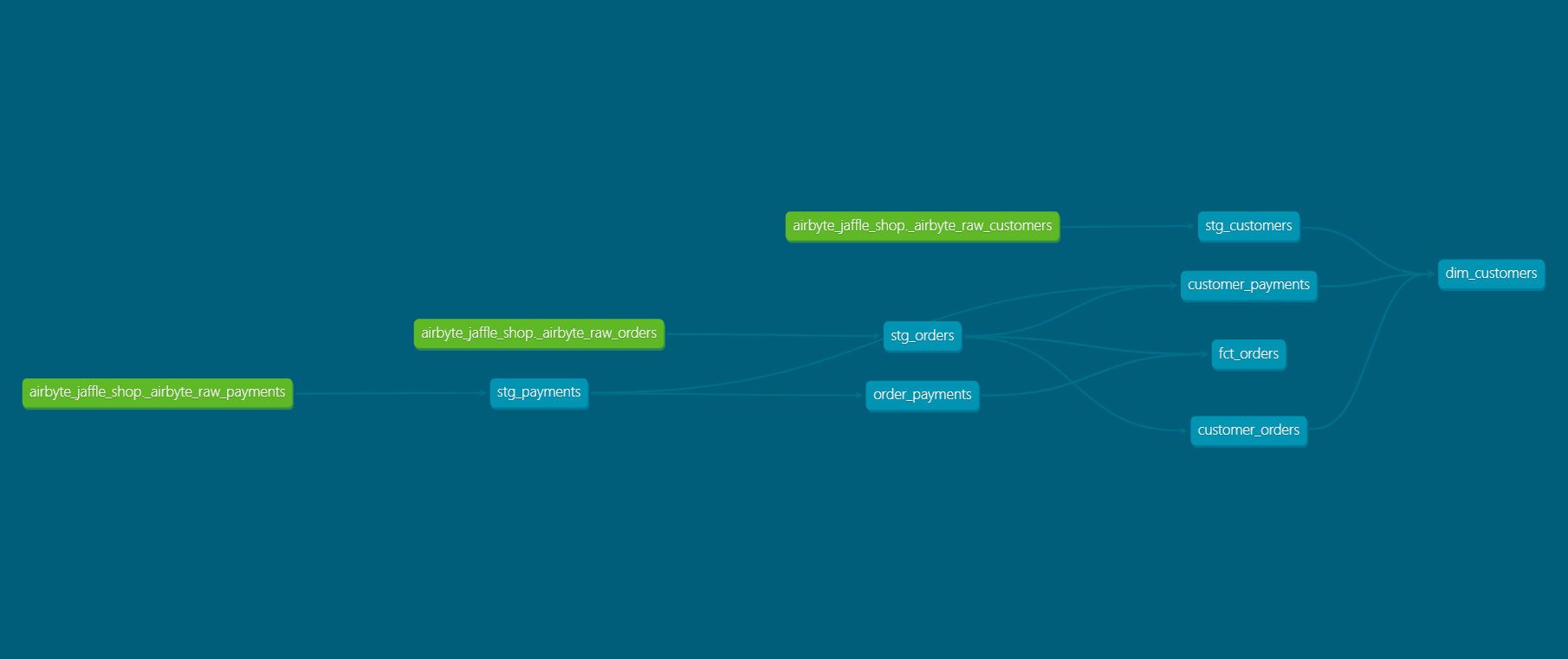
まとめ
このチュートリアルでは、Airbyte を通じてロードされた生の JSON データを dbt を使用して Teradata Vantage のディメンション モデルに変換する方法を説明しました。サンプル プロジェクトでは、Teradata Vantage にロードされた生の JSON データを取得し、正規化されたビューを作成して、最終的にディメンション データ マートを生成します。dbt を使用して JSON を正規化されたビューに変換し、複数の dbt コマンドを使用してモ��デル (dbt run) を作成し、データをテストし (dbt test)、モデル ドキュメント (dbt docs generate、 dbt docs serve) を生成して提供しました。
さらに詳しく
ご質問がある場合やさらにサポートが必要な場合は、 コミュニティフォーラム にアクセスしてサポートを受けたり、他のコミュニティ メンバーと交流したりしてください。