Transform data Loaded with Airbyte using dbt
Overview
This tutorial demonstrates how to use dbt (Data Build Tool) to transform external data load through Airbyte (an Open-Source Extract Load tool) in Teradata Vantage.
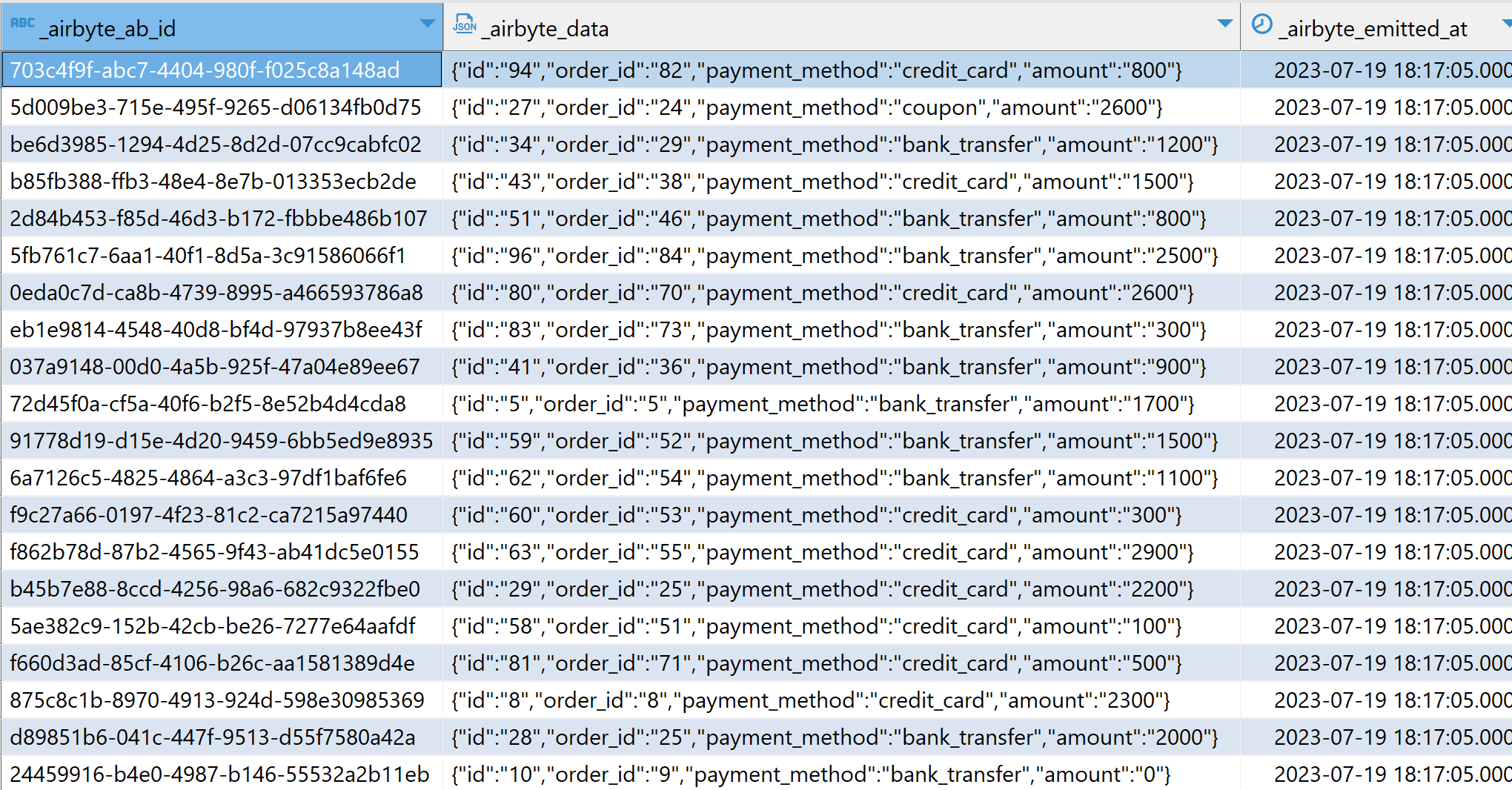
This tutorial is based on the original dbt Jaffle Shop tutorial with a small change, instead of using the dbt seed command, the Jaffle Shop dataset is loaded from Google Sheets into Teradata Vantage using Airbyte. Data loaded through airbyte is contained in JSON columns as can be seen in the picture below:
Prerequisites
- Access to a Teradata Vantage Instance.
노트
If you need a test instance of Vantage, you can provision one for free at https://clearscape.teradata.com
- Sample data: The sample data Jaffle Shop Dataset can be found in Google Sheets.
- Reference dbt project repository: Jaffle Project with Airbyte.
- Python 3.7, 3.8, 3.9, 3.10 or 3.11 installed.
Sample Data Loading
- Follow the steps in the Airbyte tutorial. Make sure you load data from the Jaffle Shop spreadsheet and not the default dataset referenced by the Airbyte tutorial. Also, set the
Default Schemain the Teradata destination toairbyte_jaffle_shop.
When you configure a Teradata destination in Airbyte, it will ask for a Default Schema. Set the Default Schema to airbyte_jaffle_shop.
Clone the project
Clone the tutorial repository and change the directory to the project directory:
Install dbt
-
Create a new python environment to manage dbt and its dependencies. Activate the environment:
노트You can activate the virtual environment in Windows by executing the corresponding batch file
./myenv/Scripts/activate. -
Install
dbt-teradatamodule and its dependencies. The core dbt module is included as a dependency so you don't have to install it separately:
Configure dbt
-
Initialize a dbt project.
The dbt project wizard will ask you for a project name and database management system to use in the project. In this demo, we define the project name as
dbt_airbyte_demo. Since we are using the dbt-teradata connector, the only database management system available is Teradata.

-
Configure the
profiles.ymlfile located in the$HOME/.dbtdirectory. If theprofiles.ymlfile is not present, you can create a new one. -
Adjust
server,username,passwordto match your Teradata instance'sHOST,Username,Passwordrespectively. -
In this configuration,
schemastands for the database that contains the sample data, in our case that is the default schema that we defined in Airbyteairbyte_jaffle_shop. -
Once the
profiles.ymlfile is ready, we can validate the setup. Go to the dbt project folder and run the command:If the debug command returned errors, you likely have an issue with the content of
profiles.yml. If the setup is correct, you will get messageAll checks passed!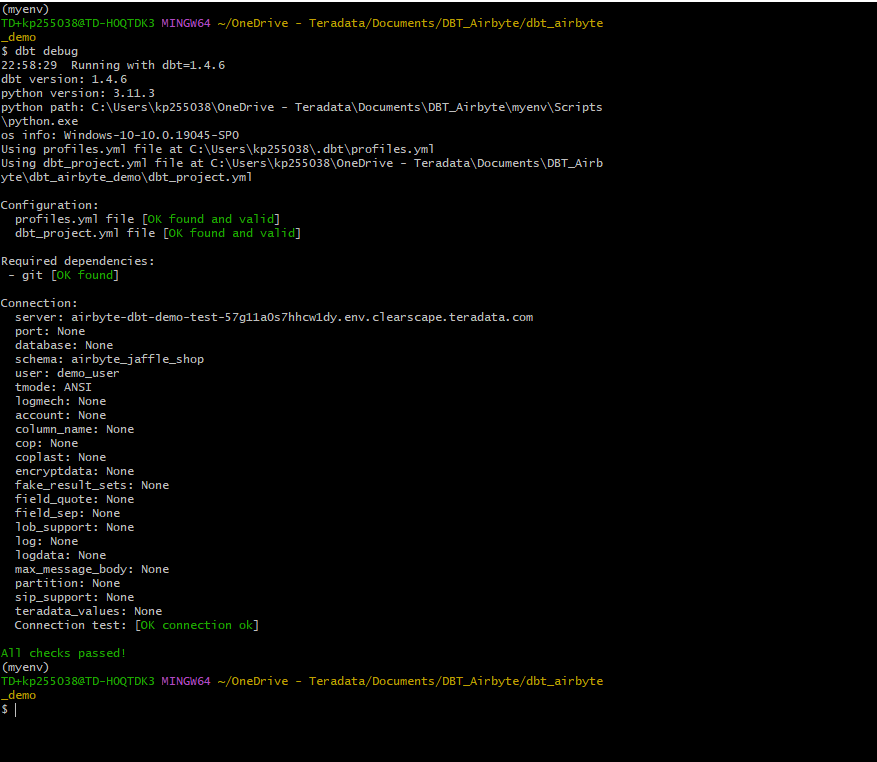
The Jaffle Shop dbt project
jaffle_shop is a fictional restaurant that takes orders online. The data of this business consists of tables for customers, orders and paymentsthat follow the entity relations diagram below:

The data in the source system is normalized. A dimensional model based on the same data, more suitable for analytics tools, is presented below:

dbt transformations
The complete dbt project encompassing the transformations detailed below is located at Jaffle Project with Airbyte.
The reference dbt project performs two types of transformations.
- First, it transforms the raw data (in JSON format), loaded from Google Sheets via Airbyte, into staging views. At this stage the data is normalized.
- Next, it transforms the normalized views into a dimensional model ready for analytics.
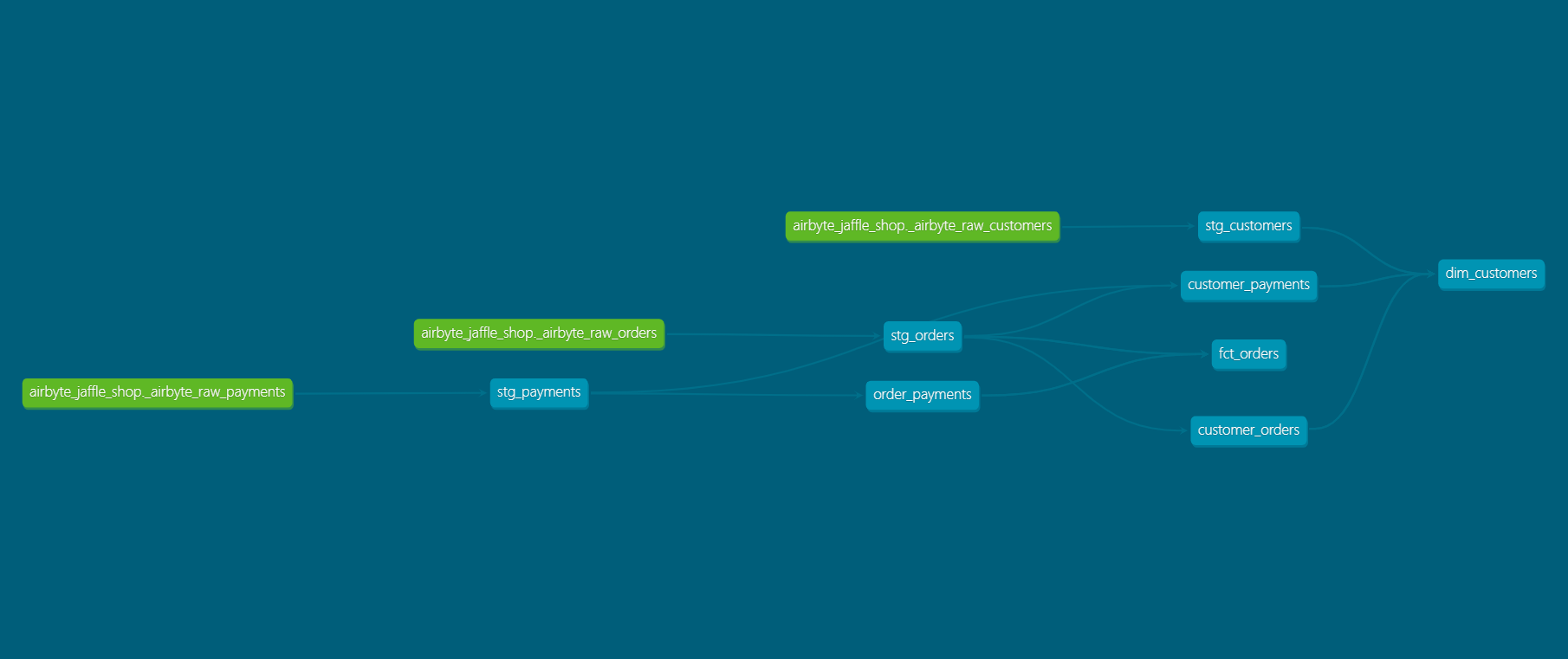
The following diagram shows the transformation steps in Teradata Vantage using dbt:

As in all dbt projects, the folder models contains the data models that the project materializes as tables, or views, according to the corresponding configurations at the project, or individual model level.
The models can be organized into different folders according to their purpose in the organization of the data warehouse/lake. Common folder layouts include a folder for staging, a folder for core, and a folder for marts. This structure can be simplified without affecting the workings of dbt.
Staging models
In the original dbt Jaffle Shop tutorial the project's data is loaded from csv files located in the ./data folder through dbt's seed command. The seed command is commonly used to load data from tables, however, this command is not designed to perform data loading.
In this demo we are assuming a more typical setup in which a tool designed for data loading, Airbyte, was used to load data into the datawarehouse/lake. Data loaded through Airbyte though is represented as raw JSON strings. From these raw data we are creating normalized staging views. We perform this task through the following staging models.
- The
stg_customersmodel creates the normalized staging view forcustomersfrom the_airbyte_raw_customerstable. - The
stg_ordersmodel creates the normalized view forordersfrom the_airbyte_raw_orderstable - The
stg_paymentsmodel creates the normalized view forpaymentsfrom the_airbyte_raw_paymentstable.
As the method of extracting JSON strings remains consistent across all staging models, we will provide a detailed explanation for the transformations using just one of these models as an example.
Below an example of transforming raw JSON data into a view through the stg_orders.sql model :
- In this model the source is defined as the raw table
_airbyte_raw_orders. - This raw table columns contains both metadata, and the actual ingested data. The data column is called
_airbyte_data. - This column is of Teradata JSON type. This type supports the method JSONExtractValue for retrieving scalar values from the JSON object.
- In this model we are retrieving each of the attributes of interest and adding meaningful aliases in order to materialize a view.
Dimensional models (marts)
Building a Dimensional Model is a two-step process:
- First, we take the normalized views in
stg_orders,stg_customers,stg_paymentsand build denormalized intermediate join tablescustomer_orders,order_payments,customer_payments. You will find the definitions of these tables in./models/marts/core/intermediate. - In the second step, we create the
dim_customersandfct_ordersmodels. These constitute the dimensional model tables that we want to expose to our BI tool. You will find the definitions of these tables in./models/marts/core.
Executing transformations
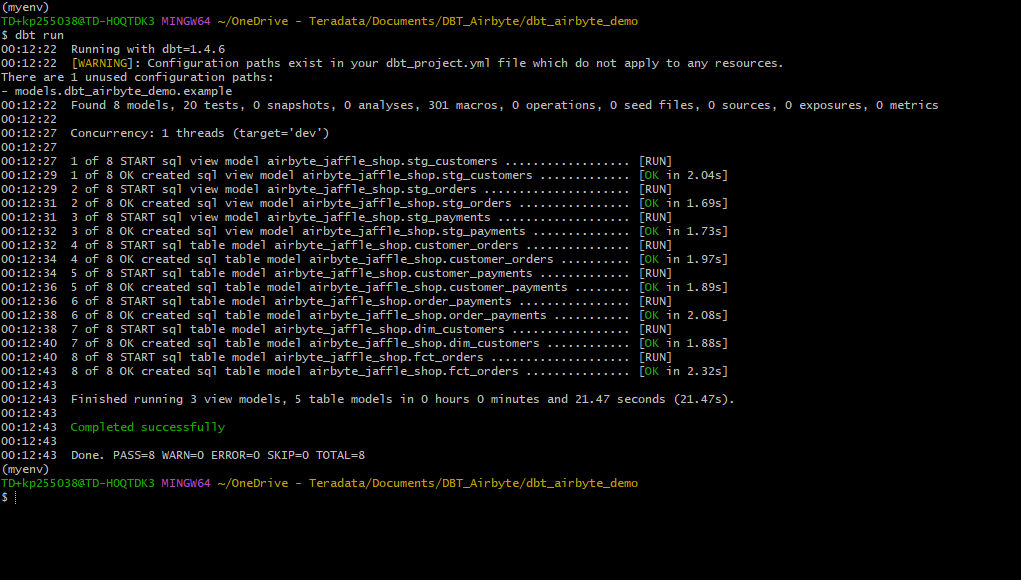
For executing the transformations defined in the dbt project we run:
You will get the status of each model as given below:
Test data
To ensure that the data in the dimensional model is correct, dbt allows us to define and execute tests against the data.
The tests are defined in ./models/marts/core/schema.yml and ./models/staging/schema.yml. Each column can have multiple tests configured under the tests key.
- For example, we expect that
fct_orders.order_idcolumn will contain unique, non-null values.
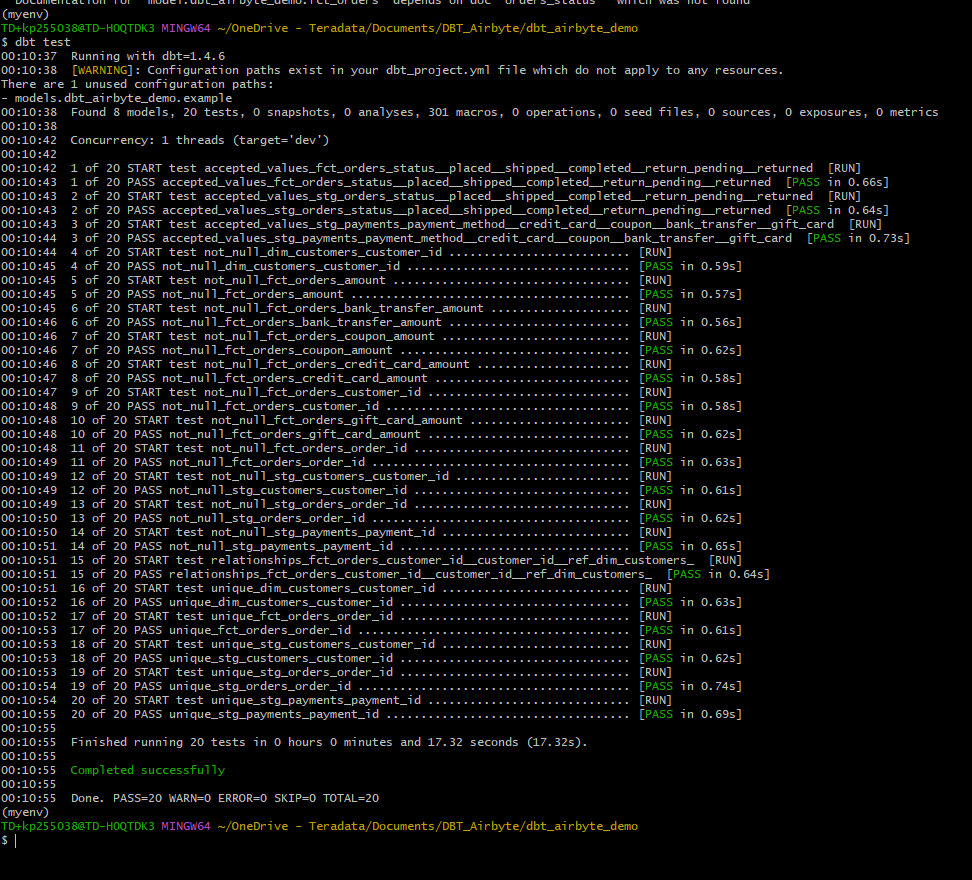
To validate that the data in the produced tables satisfies the test conditions run:
If the data in the models satisfies all the test cases, the result of this command will be as below:
Generate documentation
Our model consists of just a few tables. In a scenario with more sources of data, and a more complex dimensional model, documenting the data lineage and what is the purpose of each of the intermediate models is very important.
Generating this type of documentation with dbt is very straight forward.
This will produce html files in the ./target directory.
You can start your own server to browse the documentation. The following command will start a server and open up a browser tab with the docs' landing page:
Lineage graph
Summary
This tutorial demonstrated how to use dbt to transform raw JSON data loaded through Airbyte into dimensional model in Teradata Vantage. The sample project takes raw JSON data loaded in Teradata Vantage, creates normalized views and finally produces a dimensional data mart. We used dbt to transform JSON into Normalized views and multiple dbt commands to create models (dbt run), test the data (dbt test), and generate and serve model documentation (dbt docs generate, dbt docs serve).
Further reading
If you have any questions or need further assistance, please visit our community forum where you can get support and interact with other community members.