Use Teradata Vantage with Azure Machine Learning Studio
Overview
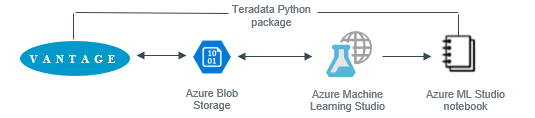
Azure Machine Learning (ML) Studio is a collaborative, drag-and-drop tool you can use to build, test, and deploy predictive analytics solutions on your data. ML Studio can consume data from Azure Blob Storage. This getting started guide will show how you can copy Teradata Vantage data sets to a Blob Storage using ML Studio 'built-in' Jupter Notebook feature. The data can then be used by ML Studio to build and train machine learning models and deploy them into a production environment.
Prerequisites
- Access to a Teradata Vantage instance.
Note
If you need a test instance of Vantage, you can provision one for free at https://clearscape.teradata.com
- Azure subscription or create free account
- Azure ML Studio workspace
- (Optional) Download AdventureWorks DW 2016 database (i.e. 'Training the Model' section)
- Restore and copy 'vTargetMail' table from SQL Server to Teradata Vantage
Procedure
Initial setup
-
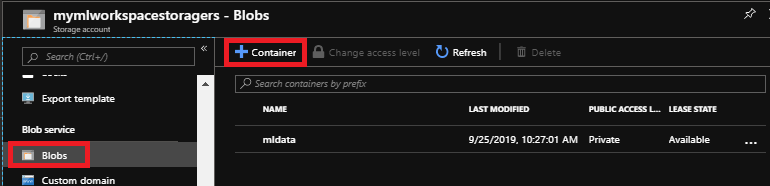
During ML Studio workspace creation, you may need to create 'new' storage account unless you have one in current availability locations and choose DEVTEST Standard for Web service plan for this getting started guide. Logon to Azure portal, open your storage account and create a container if one does not exist already.
-
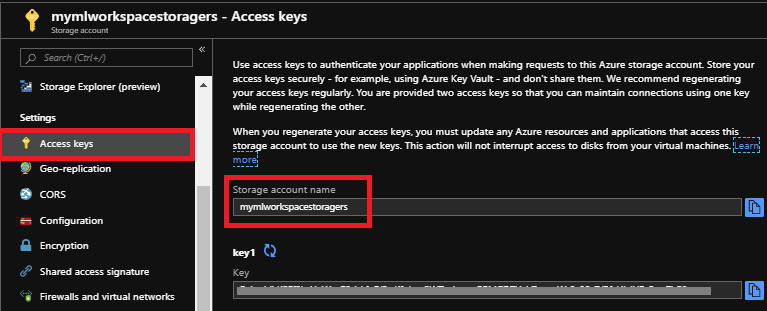
Copy your storage account name and key to notepad which we will use for Python3 Notebook to access your Azure Blob Storage account.
-
Finally, open Configuration property and set 'Secure transfer required' to Disabled to allow ML Studio Import Data module to access blob storage account.

Load data
To get the data to ML Studio, we first need to load data from Teradata Vantage to a Azure Blob Storage. We will create a ML Jupyter Notebook, install Python packages to connect to Teradata and save data to Azure Blob Storage,
Logon to Azure portal, go to to your ML Studio workspace and Launch Machine Learning Studio and Sign In.
-
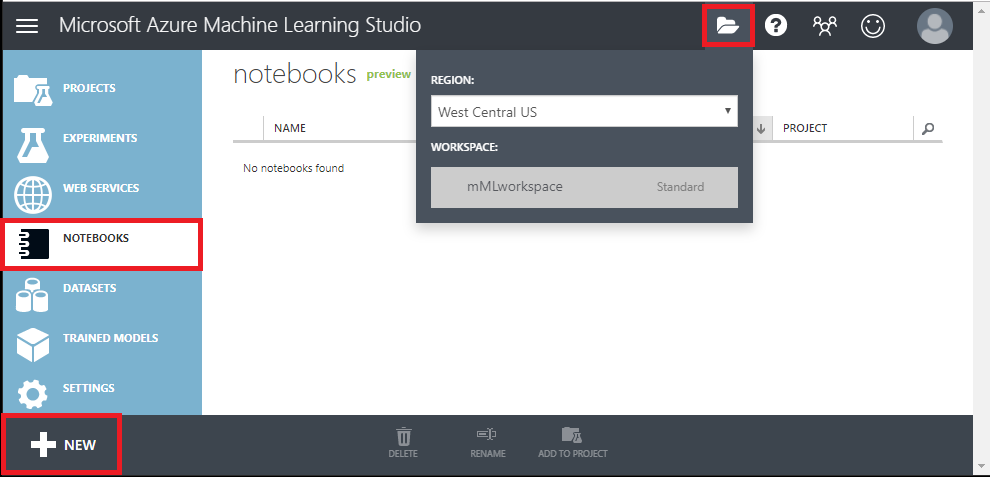
You should see the following screen and click on Notebooks, ensure you are in the right region/ workspace and click on Notebook New
-
Choose Python3 and name your notebook instance
-
In your jupyter notebook instance, install Teradata Vantage Python package for Advanced Analytics:
NoteThere is no validation between Microsoft Azure ML Studio and Teradata Vantage Python package.
-
Install Microsoft Azure Storage Blob Client Library for Python:
-
Import the following libraries:
-
Connect to Teradata using command:
-
Retrieve Data using Teradata Python DataFrame module:
-
Convert Teradata DataFrame to Panda DataFrame:
-
Convert data to CSV:
-
Assign variables for Azue Blob Storage account name, key and container name:
-
Upload file to Azure Blob Storage:
-
Logon to Azure portal, open blob storage account to view uploaded file:

Train the model
We will use the existing Analyze data with Azure Machine Learning article to build a predictive machine learning model based on data from Azure Blob Storage. We will build a targeted marketing campaign for Adventure Works, the bike shop, by predicting if a customer is likely to buy a bike or not.
Import data
The data is on Azure Blob Storage file called vTargetMail.csv which we copied in the section above.
- Sign into Azure Machine Learning studio and click on Experiments.
- Click +NEW on the bottom left of the screen and select Blank Experiment.
- Enter a name for your experiment: Targeted Marketing.
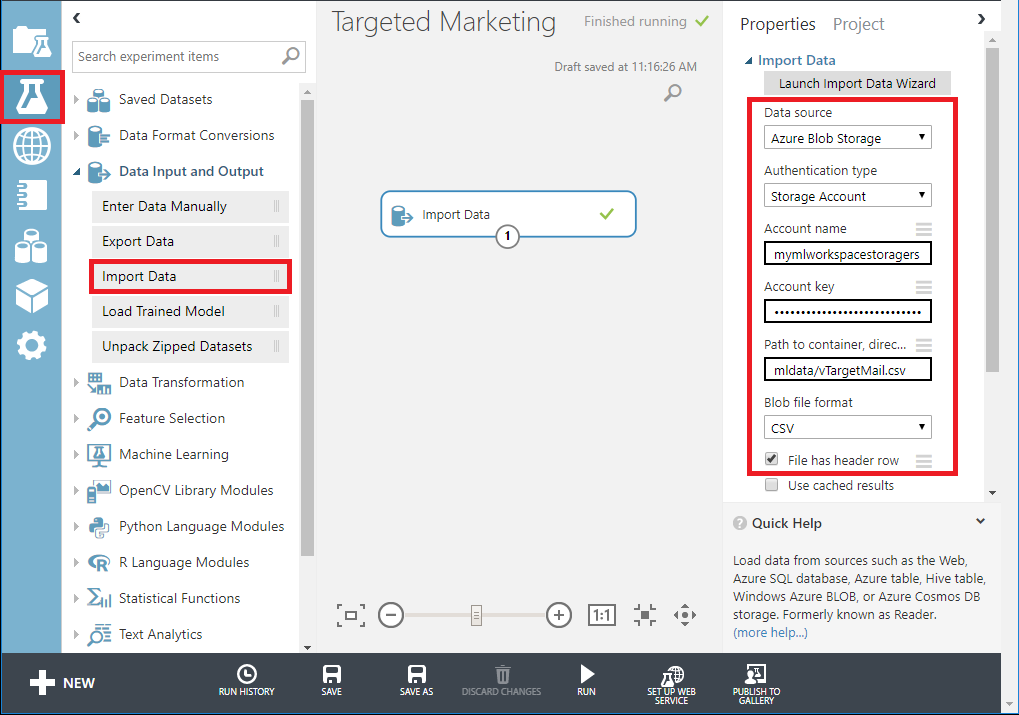
- Drag Import data module under Data Input and output from the modules pane into the canvas.
- Specify the details of your Azure Blob Storage (account name, key and container name) in the Properties pane.
Run the experiment by clicking Run under the experiment canvas.
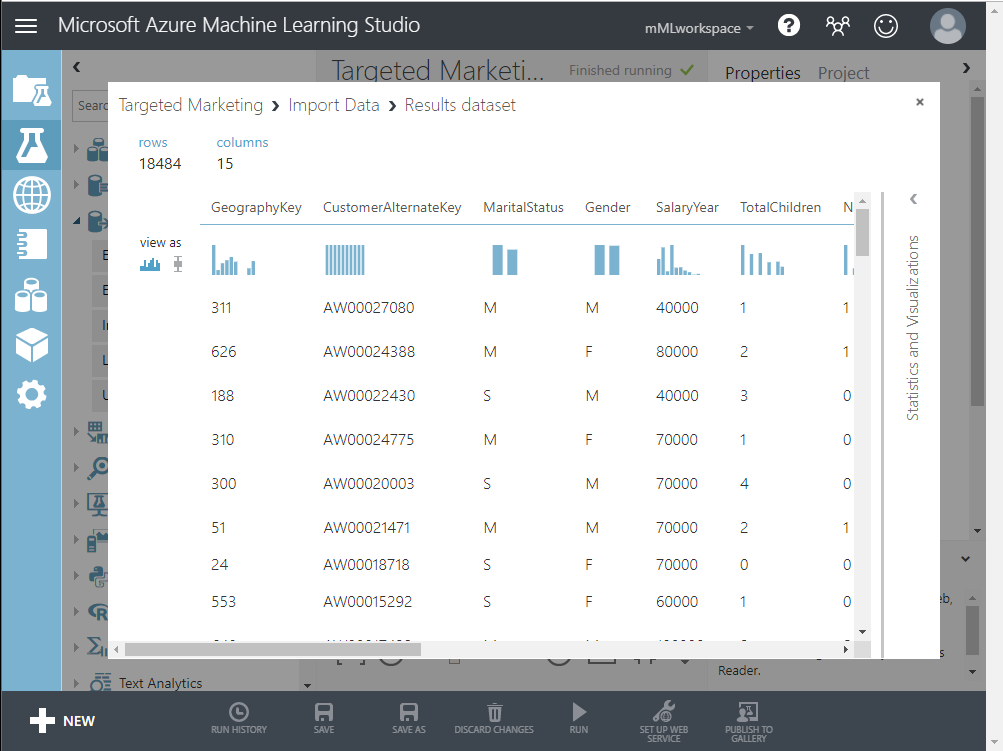
After the experiment finishes running successfully, click the output port at the bottom of the Import Data module and select Visualize to see the imported data.
Clean the data
To clean the data, drop some columns that are not relevant for the model. To do this:
- Drag Select Columns in Dataset module under Data Transformation < Manipulation into the canvas. Connect this module to the Import Data module.
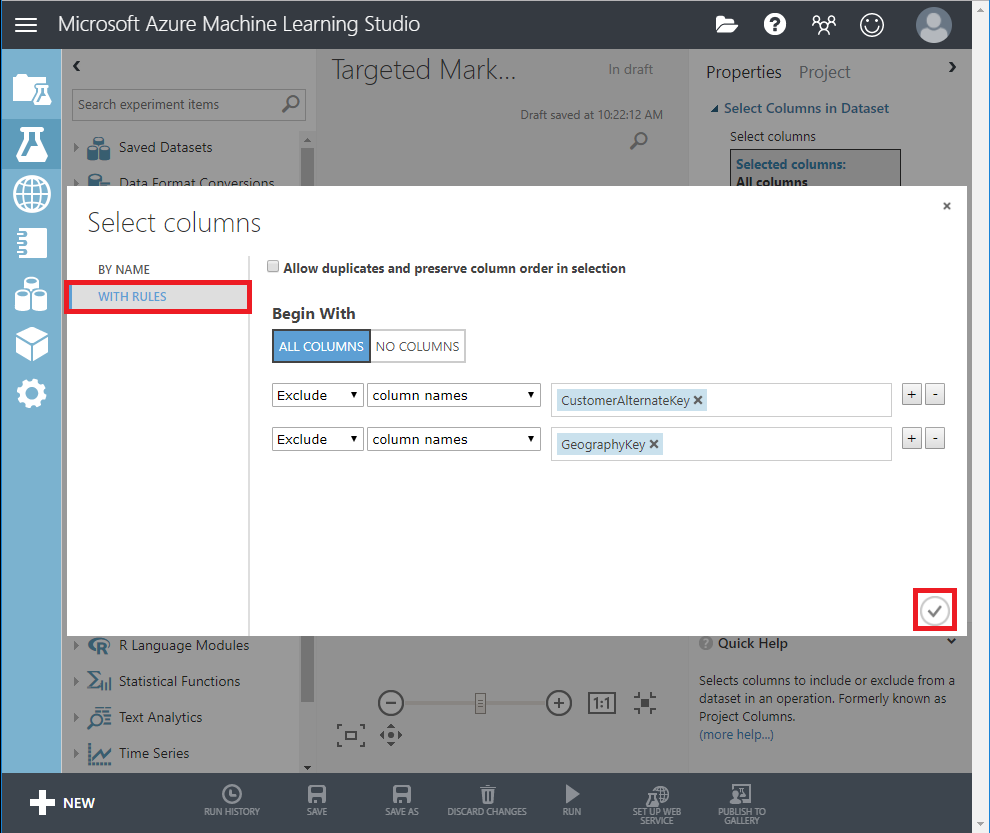
- Click Launch column selector in Properties pane to specify which columns you wish to drop.
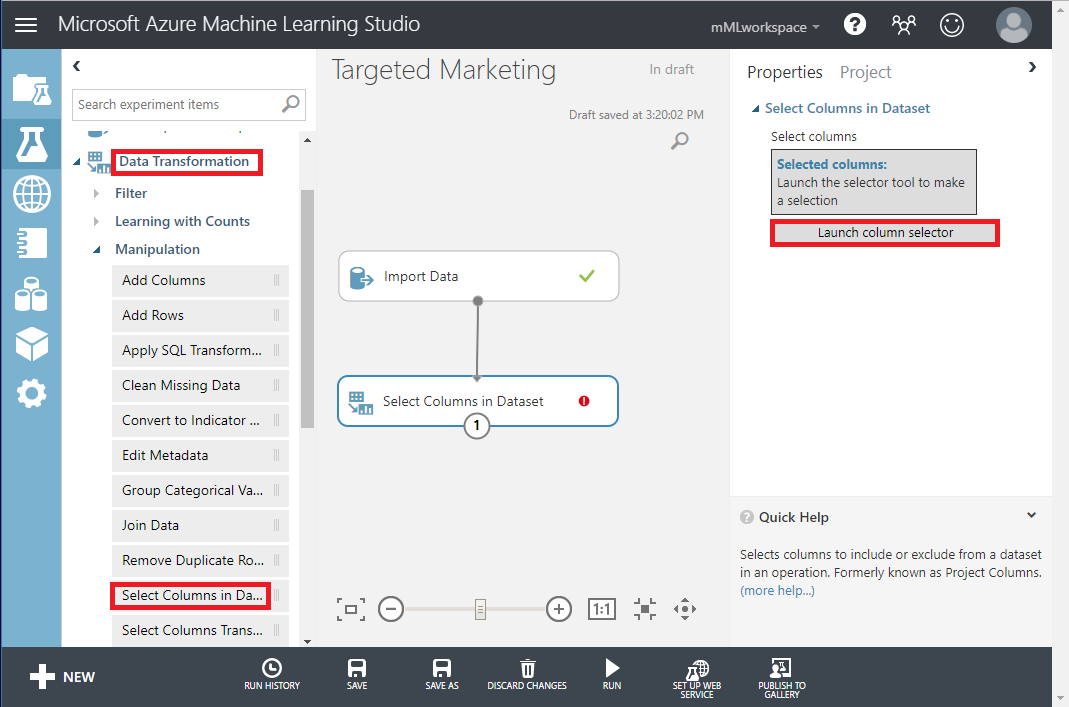
- Exclude two columns: CustomerAlternateKey and GeographyKey.
Build the model
We will split the data 80-20: 80% to train a machine learning model and 20% to test the model. We will make use of the "Two-Class" algorithms for this binary classification problem.
-
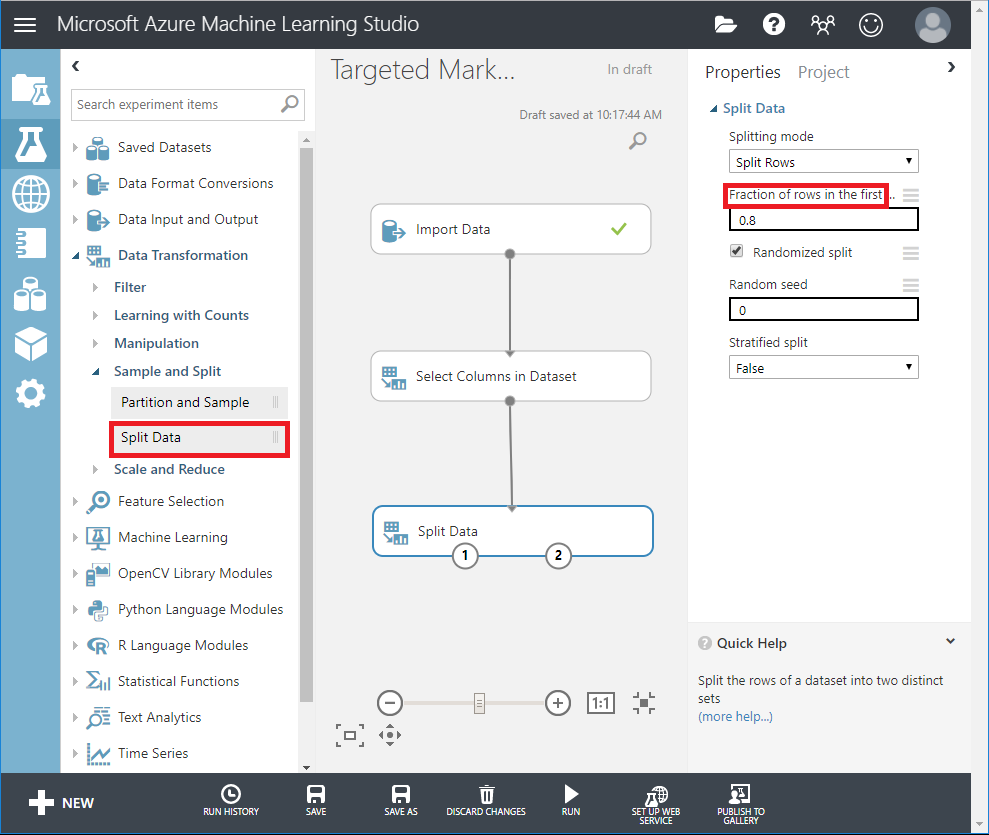
Drag SplitData module into the canvas and connect with 'Select Columns in DataSet'.
-
In the properties pane, enter 0.8 for Fraction of rows in the first output dataset.
-
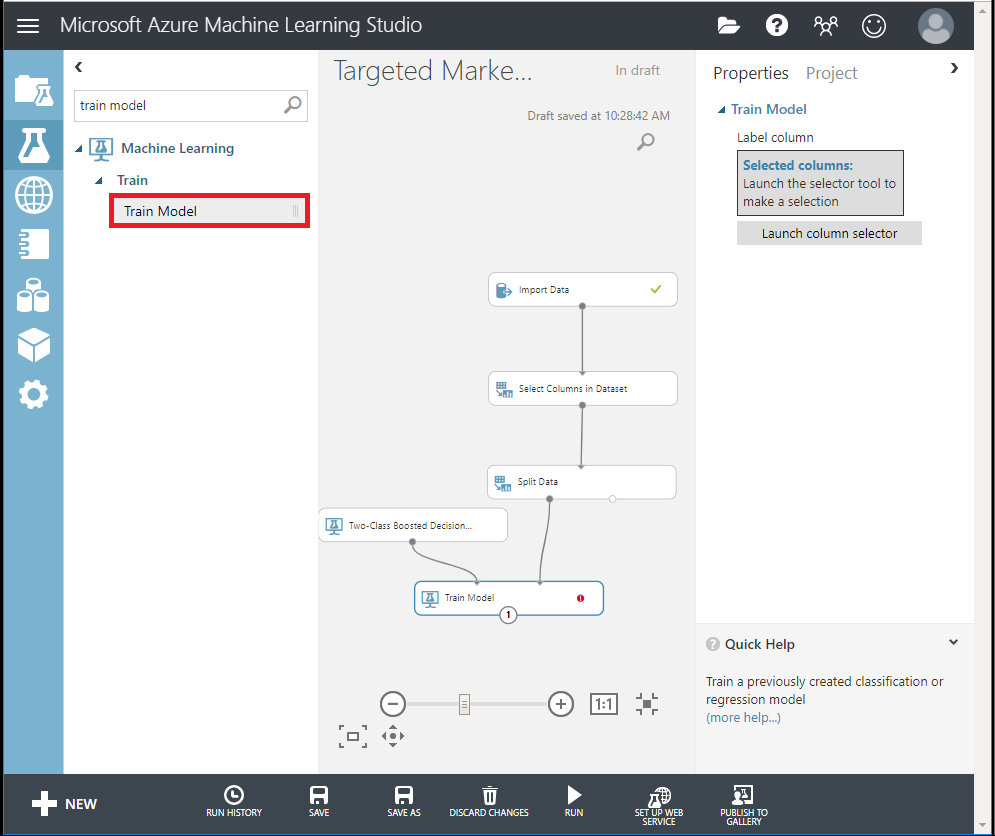
Search and drag Two-Class Boosted Decision Tree module into the canvas.
-
Search and drag Train Model module into the canvas and specify inputs by connecting it to the Two-Class Boosted Decision Tree (ML algorithm) and Split Data (data to train the algorithm on) modules.
-
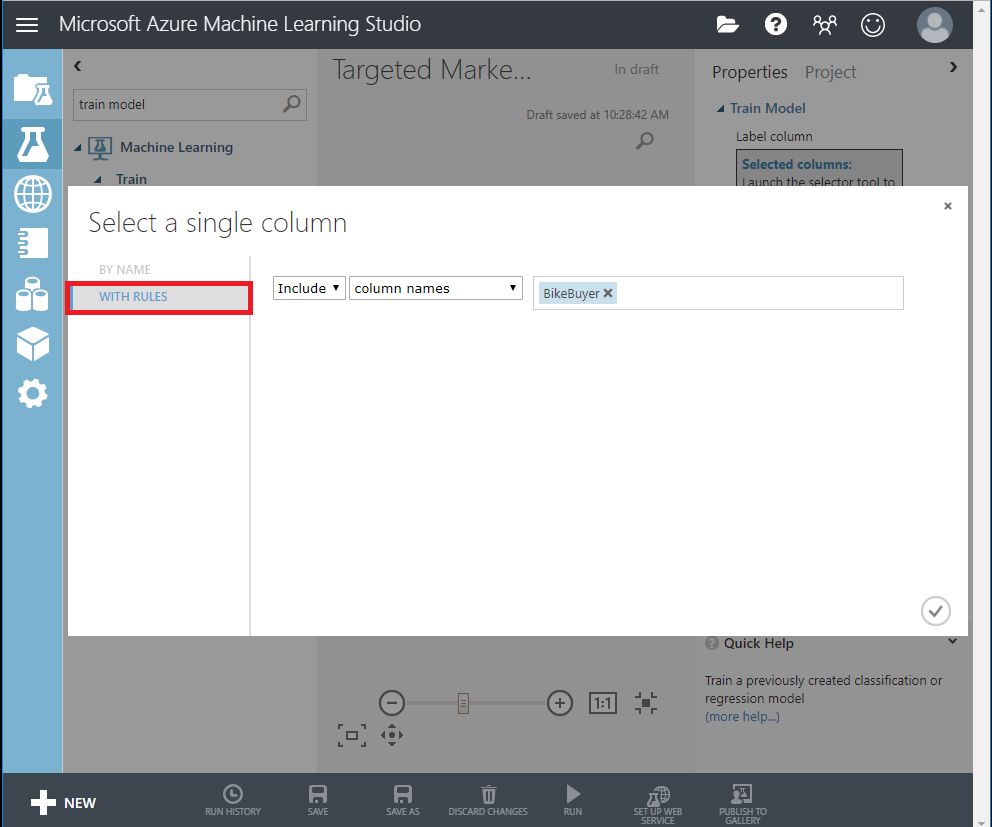
Then, click Launch column selector in the Properties pane. Select the BikeBuyer column as the column to predict.
Score the model
Now, we will test how the model performs on test data. We will compare the algorithm of our choice with a different algorithm to see which performs better.
- Drag Score Model module into the canvas and connect it to Train Model and Split Data modules.
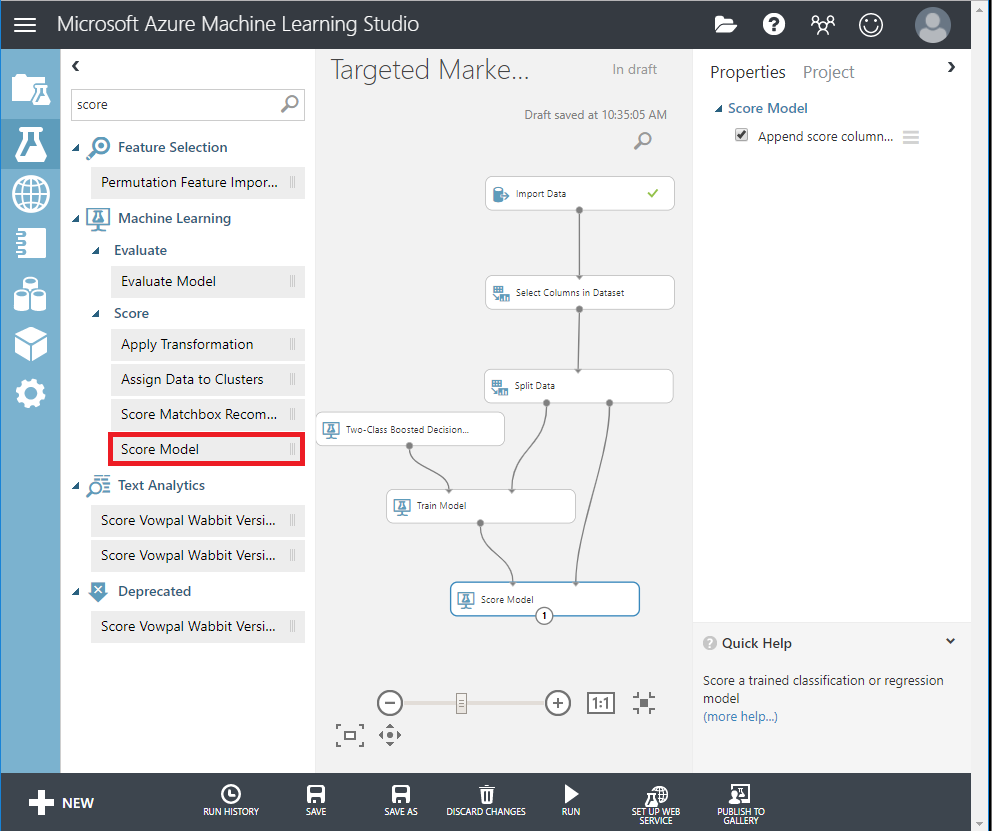
- Search and drag Two-Class Bayes Point Machine into the experiment canvas. We will compare how this algorithm performs in comparison to the Two-Class Boosted Decision Tree.
- Copy and Paste the modules Train Model and Score Model in the canvas.
- Search and drag Evaluate Model module into the canvas to compare the two algorithms.
- Run the experiment.
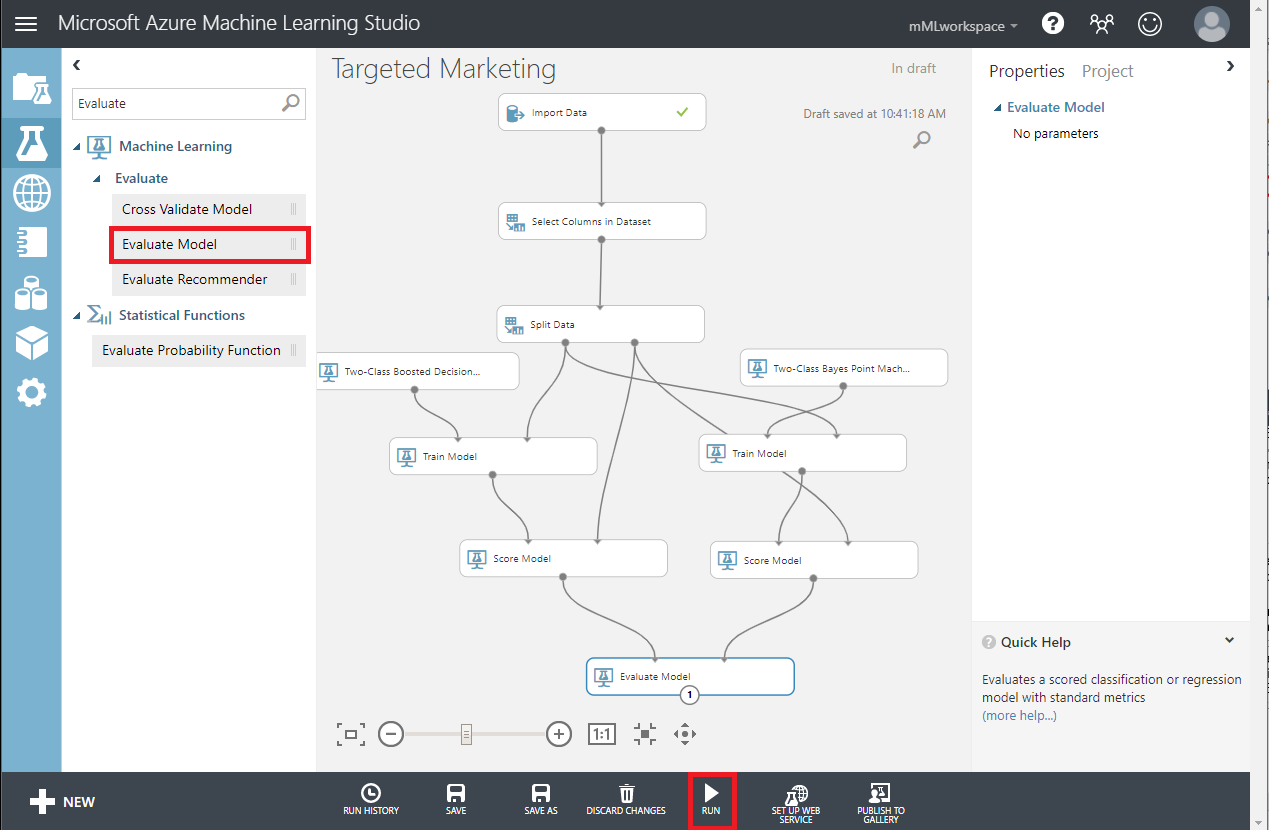
- Click the output port at the bottom of the Evaluate Model module and click Visualize.
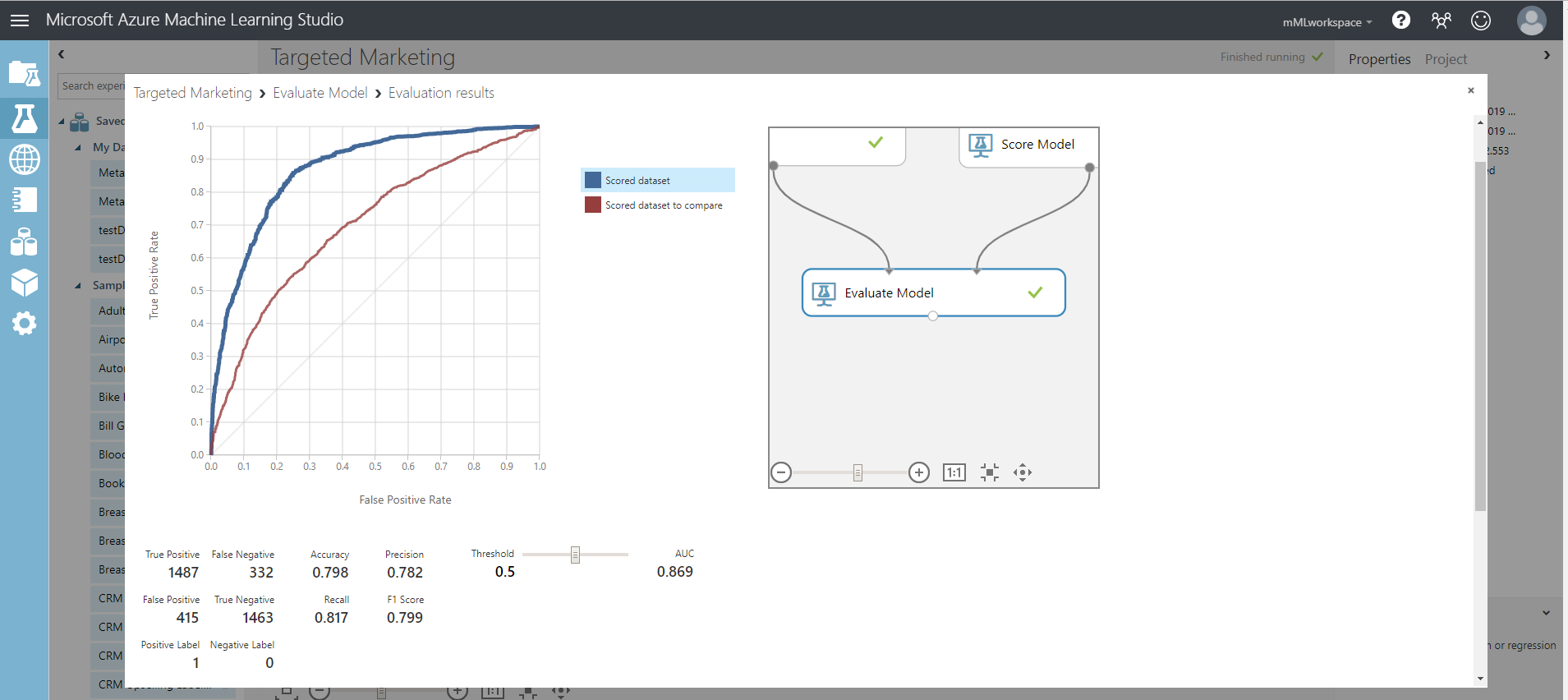
The metrics provided are the ROC curve, precision-recall diagram and lift curve. Looking at these metrics, we can see that the first model performed better than the second one. To look at the what the first model predicted, click on output port of the Score Model and click Visualize.
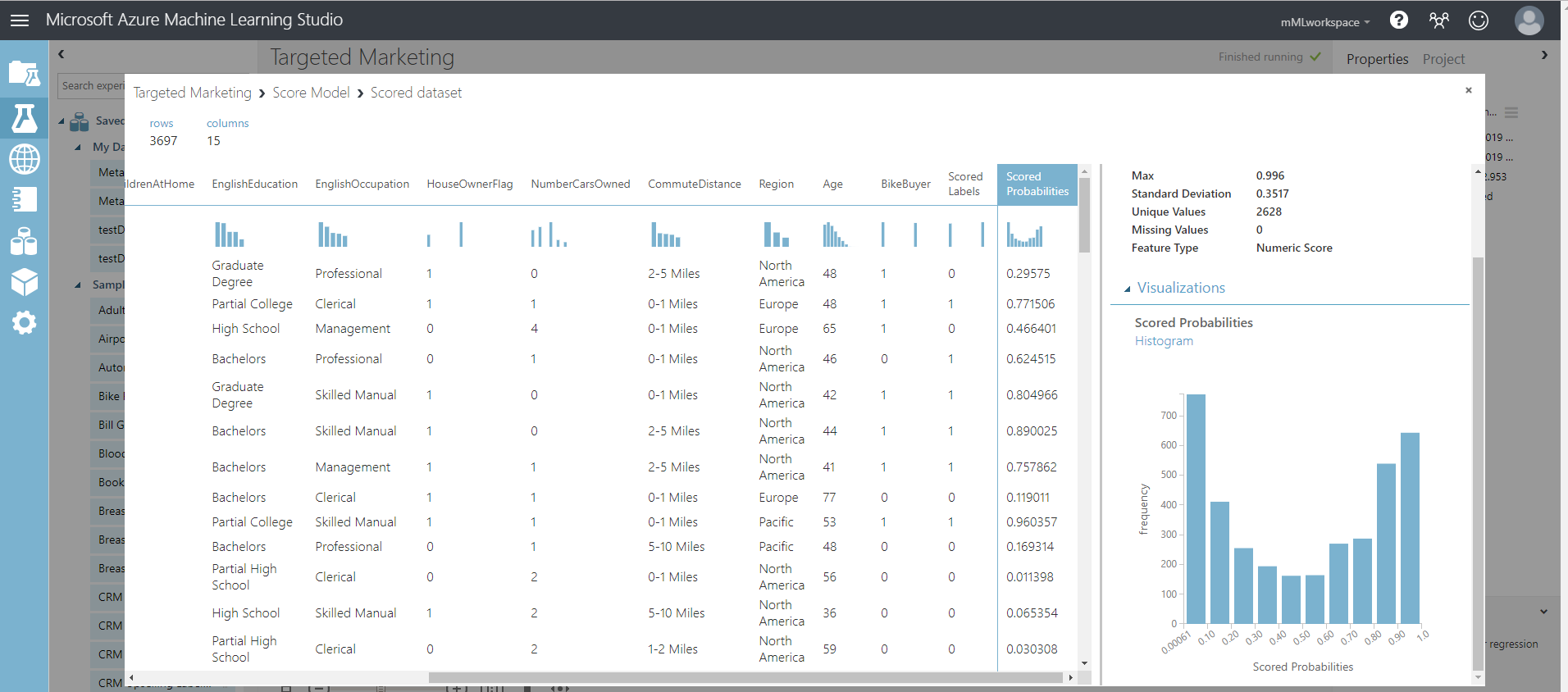
You will see two more columns added to your test dataset.
- Scored Probabilities: the likelihood that a customer is a bike buyer.
- Scored Labels: the classification done by the model - bike buyer (1) or not (0). This probability threshold for labeling is set to 50% and can be adjusted.
Comparing the column BikeBuyer (actual) with the Scored Labels (prediction), you can see how well the model has performed. As next steps, you can use this model to make predictions for new customers and publish this model as a web service or write results back to SQL Data Warehouse.
Further reading
- To learn more about building predictive machine learning models, refer to Introduction to Machine Learning on Azure.
- For large data set copies, consider using the Teradata Access Module for Azure that interfaces between the Teradata Parallel Transporter load/unload operators and Azure Blob Storage.
If you have any questions or need further assistance, please visit our community forum where you can get support and interact with other community members.